
「AIを作る国」から「AIで勝つ国」へ ── 日本のAI投資戦略を再設計する【後編】


── SaaS再編の時代に、どこにポジションを取るか
こんにちは! Qualitegコンサルティングです!
ここ数年、「日本のAI戦略」というテーマでの相談やディスカッションが増えてきました。
生成AIの登場以降、経営層から現場のエンジニアまで、それぞれの立場で「自社はどこに張ればいいのか」「国としてはどう進むべきか」を模索している、というのが実感です。
本シリーズでは、その問いに対して少し腰を据えて向き合ってみたいと思い、前後編の構成で書いてみました。
前編では、国産LLM、データセンター投資、データ主権の3テーマを通じて、日本のAI投資が必ずしも「使われて勝つ構造」に向かっていない可能性を見てきました。投資の総額やプレイヤーの動きを並べてみると、号令の方向と実際の資金の流れにはちょっとしたズレがあるのではないか、という現在地が見えてきます。
後編では、その前提の上で視点をソフトウェア産業全体に広げます。もしAIによってアプリケーション層そのものの競争ルールが変わるなら、日本が張るべき場所もまた変わるはずです。海外で起きているSaaS産業の地殻変動を眺めたうえで、日本がどこにポジションを取るべきかを一緒に考えていきましょう。

第5章:ソフトウェア産業で何が起きているか
ソフトウェア株の急落──何が織り込まれたのか
2026年1月末以降、北米のソフトウェア/データ関連株には大規模な売りが波及しました。Reutersの報道によれば、S&P 500のソフトウェア・サービス指数は急落し、セクター全体の時価総額が約1兆ドル(約150兆円)近く減少したとされています。北米ソフトウェア銘柄を追跡するIGV ETFは年初来で2割前後の下落を記録し、セクターのバリュエーションは2010年代半ば以来の水準にまで圧縮されました。
背景として報じられたのは、生成AIがアプリケーション層の収益構造を侵食しうるという見方の再燃です。マクロ経済の急変や個別のスキャンダルではなく、ソフトウェア産業そのものの構造的な変化への警戒が売りを加速させた格好です。
ここで注意しておきたいのは、3つの切り分けです。
1つ目に、市場はそう織り込み始めた。SaaSの収益マルチプルは一部の大手を除くと厳しい水準に追い込まれ、勝ち組が平均を押し上げる二極化が進行中です。VC投資も2021年のピークからほぼ半減したのち横ばいが続く一方、案件数は大幅に減少しており、「少数の有望企業に大型の資金が集中し、それ以外は干上がる」構図が鮮明です。
2つ目に、実態がそこまで急速に進むかは未確定です。短期の株価は物語(ナラティブ)に振れやすい性質を持ちます。バリュエーションの調整が構造的なものなのか一時的なものなのかは、今後の推移を見る必要があります。
3つ目に、重要なのは未来の確定ではなく、競争条件の変化が広く意識され始めたことです。後述するように、課金モデル、UI、垂直統合といった複数の次元で、SaaSの前提が揺さぶられています。

「SaaS is Dead」の中身
2024年末、大手テック企業のCEOの発言が「SaaSは死んだ」と要約され拡散しました。IDCはこのテーマを整理した分析を公開しています。もちろん翌日からSaaS企業が消えるわけではありません。ただ、この言葉が象徴する変化は根深いものがあります。
ビジネスモデルへの転換圧力。 IDCの予測(FutureScape)では、2028年までにソフトウェアベンダーの70%がシートベース(ユーザー数課金)からコンサンプションベースやアウトカムベース(成果課金)への移行圧力にさらされるとされています(CIO.comの解説記事も参照)。
なぜか。シートベース課金は「何人がそのソフトを使っているか」で値段が決まります。ところがAIエージェントが人間の代わりにタスクを処理するようになると、「何人が使うか」という問い自体の説明力が相対的に落ちていきます。だから課金の基準は「どれだけ処理したか」(コンサンプション)や「どれだけの成果を出したか」(アウトカム)に移っていく可能性がある。
これはSaaS企業にとって、単なる価格改定ではなく、収益構造の根本的な組み替えを迫られることを意味します。シートベース課金の魅力は予測可能性にありました。ユーザー数×月額単価で来月の売上がかなり正確に見える。しかし成果課金になると売上の変動幅が大きくなり、SaaSの最大の魅力だった「予測可能な定期収入」が揺らぎます。投資家がSaaS銘柄に高いマルチプルをつけてきた根拠の一つがこの予測可能性だったわけで、それが失われるとなれば、バリュエーションが構造的に下がるのも理解できます。
インターフェースという「堀」の希薄化。 業界では「何百万人もの人がSaaSのUIを覚えたこと自体が最大の堀であり、インターフェースが自然言語になった瞬間にその堀は消える」という見方が広がっています。
考えてみてください。Salesforceの競争優位性の相当部分は、「何百万人もの営業担当者がSalesforceの使い方を知っている」という事実に由来しています。別のCRMに乗り換えようとすると、全員が新しいUIを覚え直す必要がある。この「学習コスト」が、実質的なスイッチングコストとして機能してきたわけです。
しかし、インターフェースが自然言語での指示へ寄っていくと、UI由来のユーザー体験の差分は相対的に縮まりやすくなります。UIの学習コストが下がれば、スイッチングコストも下がる。何年もかけて築いた参入障壁が無効化されるかもしれない。これが現実になるかどうかはまだわかりませんが、市場がかなり本気でその可能性を織り込み始めたのが2026年初頭の動きだと見ることができます。

基盤モデル企業がアプリ層まで降りてきた
もう一つ見逃せない動きがあります。
2024年から2025年前半は「AIは既存SaaSを強化する」が主流のナラティブでした。どのソフトウェア企業も決算説明会で「AI組み込みで生産性アップ」と語り、投資家もそれを好感していた。ところが2025年後半から2026年にかけて、このナラティブが静かにひっくり返ります。
転換の背景にはいくつかの要因が指摘されています。AIエージェント系のスタートアップが実用的な製品を出し始めたこと。DeepSeekに代表されるオープンソースモデルが、低コストでも競争力のある性能を達成しうることを示したこと(Reuters: A year on from DeepSeek shock)。そして決定的だったのは、基盤モデル企業自身がアプリケーション層に進出し始めたことです。
OpenAIはGPTsやCanvasを提供。AnthropicはArtifacts、Computer Use、MCP、Claude Codeと、次々にアプリケーション層の製品を展開しています。さらに非エンジニア向けのデスクトップエージェント──ブラウザ操作、Excel操作、ファイル管理を自律的に行うツール──も登場しています。
なぜこうなるかというと、基盤モデルだけの商売は差別化が難しいからです。モデルの性能差は時間とともに縮まり、価格競争に陥りやすい。だからモデルの上に付加価値の高いアプリケーション層を構築して、ユーザーのワークフローに深く入り込むことでスイッチングコストを作りたい。
これは「垂直統合の誘惑」とでも呼ぶべき現象で、テック業界では過去に何度も繰り返されてきたパターンです。チップメーカーがOSを作り、OSメーカーがアプリを作り、アプリメーカーがクラウドを作る。AI業界でも同じことが起きているだけ、とも言えます。
「基盤モデルは海外製でいい、その上にアプリを作るのが自分たちの仕事だ」と考えていたプレイヤーにとっては、悩ましい状況です。上のレイヤーで付加価値を出すつもりだったのに、下から浸食されてくる。

では、この環境下で守りやすいポジションはどこにあるのか。
第6章:構造的に守りやすい場所はどこか
AIベンダー自身が担うと利益相反が生じやすい領域を探す
基盤モデル企業がどれだけ進化しても、ベンダー自身が担うと利益相反が生じやすい領域というのはあります。なぜなら、ある種のサービスは「特定のAIベンダーに属さない」ことが本質的な価値だからです。
その視点で市場を眺めてみると、独立系プレイヤーに機会がある可能性のある候補がいくつか浮かんできます。
マルチベンダー統合。 OpenAIはAnthropicのモデルを推薦しませんし、GoogleはOpenAIとの併用を手助けしてくれません。しかし企業にとっては、タスクごとに最適なモデルを選べるほうが合理的なケースが多い。しかもLLMの世界では、用途別に優位なモデルが比較的頻繁に変動します。コーディング、長文コンテキスト処理、推論、多言語対応──それぞれの評価軸で最適なモデルは異なりますし、数カ月で勢力図が塗り替わることも珍しくありません。
たとえば、法務文書のレビューにはモデルA、社内ナレッジ検索にはモデルB、コード生成にはモデルCを使っている企業があったとして、アプリケーション側を変えずにモデルだけを切り替えられる基盤があれば、ベンダーロックインのリスクを下げられます。各AI大手にとって利益相反があるぶん、こうしたベンダーニュートラルな統合レイヤーには独立系プレイヤーに構造的な余地があります。
データ統制・ガバナンス。 前編で触れたデータ主権の話と直結します。LLMの入出力データの監視を、そのLLMを提供している企業に委ねるのは、審判と選手を兼ねてもらうようなものです。
特に規制が厳しい金融、医療、官公庁向けでは、「どのLLMを使っていても、入出力データが適切に管理されていることを独立して検証できる」仕組みへのニーズは根強いでしょう。具体的には、機微情報をマスクしてからLLMに送る仕組みや、モデル非依存で監査ログを残す仕組みです。これは「国産モデルを使うことでデータを守る」というアプローチとは根本的に発想が違います。モデルの国籍ではなく、データの流れそのものを制御する。「モデルの外側に置くセキュリティレイヤー」です。
業務コンテキストへの接続。 汎用AIエージェントがどれだけ賢くなっても、個々の企業の稟議フロー、社内規定、業界固有の規制は知りません。「1,000万円以上の支出は部長承認、5,000万円以上は役員承認」「薬機法の広告規制に抵触しないか確認が必要」──こうした業務コンテキストは、企業ごと、業界ごとに千差万別です。
たとえばAIエージェントに「契約書をレビューして」と頼んだとき、法的なチェックはかなり正確にやってくれます。しかし「この条項はうちの過去の取引慣行に照らしてどうか」「この相手先との力関係を考えるとどこまで押せるか」といった判断は、その企業の文脈を深く知らないとできません。稟議ルール、承認権限、過去の社内判断──こうした制約条件をエージェントに与える設計こそが、業務を深く理解したプレイヤーでないと埋められない「ラストワンマイル」です。
この3つに共通するのは、いずれもAIベンダー側ではなく、AIを利用する企業の側に立つことで初めて提供できるという点です。AI大手が進化すればするほど、「AI大手の代替」ではなく「AI大手と企業の間に立つ」ポジションの価値は、むしろ上がるかもしれません。
もちろん、これが確実に正しいとは誰にも言えません。AIベンダーが自前でこうした領域もカバーしてしまう可能性もありますし、企業側がこうした中間レイヤーを必要としない運用形態に落ち着く可能性もある。ただ、少なくとも現時点の構造を見る限り、検討に値する方向性ではあると思います。

SaaSモデルの再編圧力──そのあとに何が来るか
「SaaS is Dead」の議論をもう少し先まで考えてみましょう。
仮に現在のSaaSモデルが大幅に縮小するとして、その後に来るのは何か。いくつかのシナリオが考えられます。
一つは「AIエージェントが直接タスクを実行するモデル」。ユーザーがソフトウェアを操作するのではなく、AIエージェントに目的を伝え、エージェントがさまざまなツールやデータソースを組み合わせて結果を返す。この場合、従来のSaaSの「画面」は不要になり、代わりにAPIやデータパイプラインの重要性が上がります。
もう一つは「プラットフォーム型への集約」。数社のAI大手が提供するプラットフォーム上に、あらゆるビジネスツールがプラグインとして載る世界です。
いずれのシナリオでも、重要なのは「データとワークフローの独自性」です。AIがどれだけ賢くなっても、企業固有のデータと業務プロセスは外部からは見えない。このデータとプロセスへのアクセスを持つプレイヤーは、AIの進化の恩恵を受ける側に回れます。逆に、汎用的な機能を提供しているだけで独自のデータもワークフローも持たないSaaS企業は、AIエージェントに置き換えられるリスクが高い。
第7章:日本の勝ち筋はどこにあるか
「作れない」は本当に弱みか
前編で見た通り、基盤モデルの開発競争で日本が米中に勝つのは、資本の桁が違う以上、現実的には難しい。では「作れない」ことは致命的な弱みなのかというと、そうでもないかもしれません。
よく引き合いに出される話ですが、トヨタ生産方式が世界の自動車産業を変えたのは、エンジン性能で圧倒したからではなく、同じエンジンの「使い方の設計」──生産プロセス、品質管理、サプライチェーン──で差別化したからでした。「ジャスト・イン・タイム」や「カイゼン」といった生産システムの設計で、同じ部品から圧倒的に高い品質と効率を引き出した。自動車とAIではいろいろ条件が違いますから、安易なアナロジーには注意が必要です。ただ「道具を作る競争」と「道具で何を解くかの競争」は別物だ、という構図自体は参考になります。半導体の歴史でも、日本はチップの「製造」では韓国・台湾勢に追い抜かれましたが、製造装置や素材ではいまだに高いシェアを維持しています。
AIでも似たポジショニングがありえるとすれば、それは「モデルを作る」ことではなく、「モデルを使いこなすための基盤やツール」を作ることかもしれません。

"AIユースケース先進国"という可能性
日本にはAIが解くべき課題がたくさんある、とよく言われます。超高齢社会と人手不足。製造業の品質管理と自動化。医療・介護の効率化。建設業の安全管理。物流の最適化。行政のデジタル化。 たとえば、製造現場での異常検知と作業標準の照合、介護現場での記録業務とケア計画支援、建設現場での安全書類チェックと規程照合などは、日本で先に実装知見が蓄積されやすい領域でしょう。
しかもこれらの現場には数十年分のデータとノウハウが蓄積されていて、「人手が足りないからAIを入れざるを得ない」という切実な動機がある。「AIを使ってみたい」ではなく「AIを使わないとオペレーションが回らない」というレベルの切迫感です。
労働人口の減少は、国立社会保障・人口問題研究所の将来推計人口(令和5年推計)を見ると深刻さが際立ちます。生産年齢人口は今後20年間で大幅な減少が見込まれており、推計の前提条件によって幅はあるものの、数千万人規模の縮小が予測されています。これは「生産性を上げないと社会が回らない」ということであり、AI導入のインセンティブとしてはこれ以上ないほど強烈です。
日本の優位は、モデルの供給側ではなく、制約の多い現場でAIを回す実装側にあるかもしれません。ただ、課題があることと、その課題をAIで解く力があることは別の話です。課題は豊富にあるけれど実装力が足りない、では宝の持ち腐れです。
実装力を育てるには何が必要か。まずAI活用の設計ができる人材。モデルの中身を理解し、業務プロセスとの統合を設計できる人です。次に、マルチベンダーでLLMを安全に使いこなすための基盤。そしてデータ統制とガバナンスの仕組み。成功パターンの共有と横展開。だからこそ、投資の優先順位が問われます。基盤モデルの自前開発に予算を割くのか、それとも「どんなモデルでも使いこなせる基盤」と「それを担える人材」に振るのか。どちらが費用対効果が高いかは、考えてみる価値のある問いだと思います。
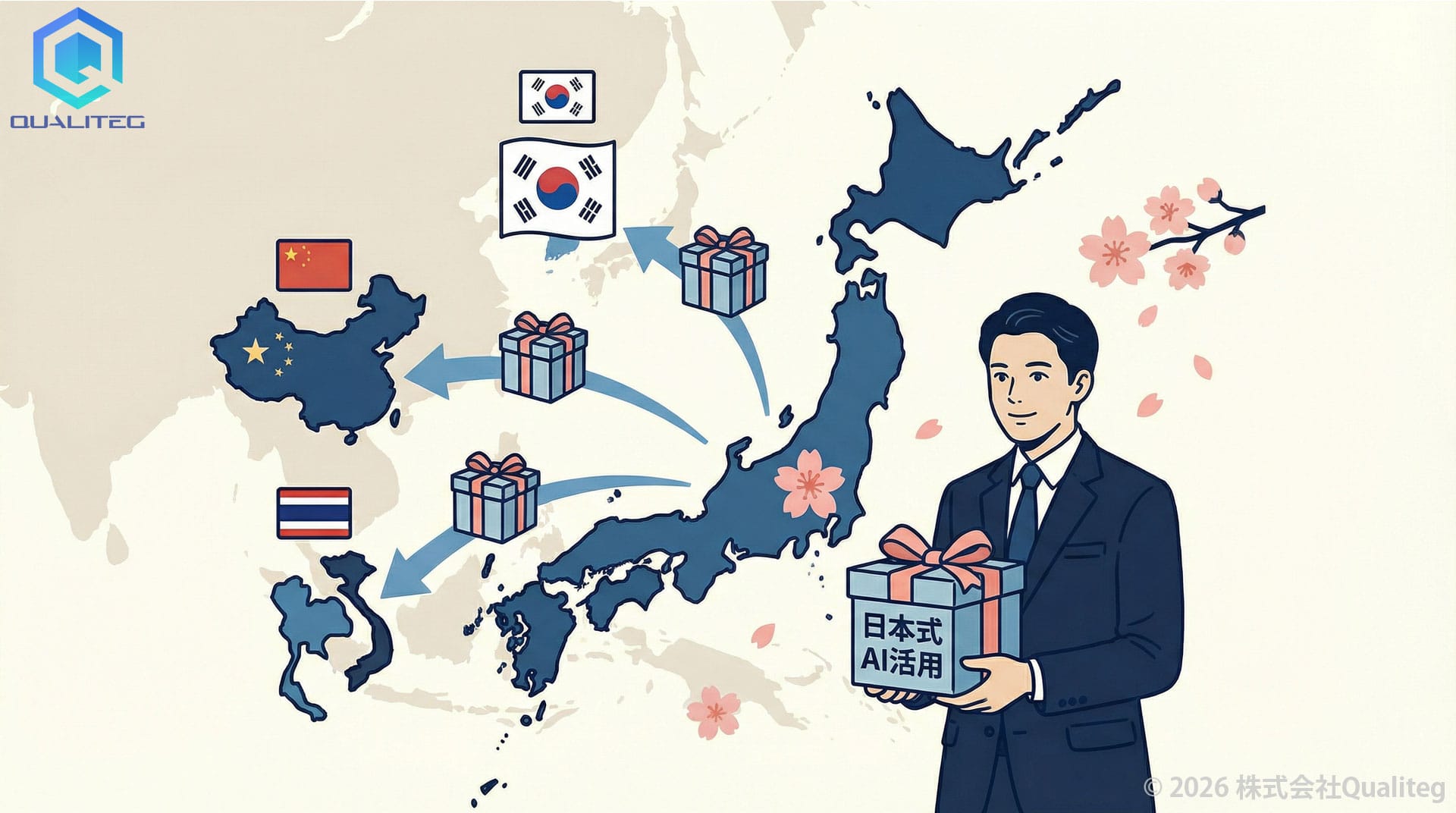
使い方で輸出する
高齢化や人手不足はアジア全域で今後急速に顕在化する課題です。韓国、中国、タイ、ベトナム──いずれも20〜30年後には日本と似た人口構造の課題に直面します。日本がここでAI実装のノウハウを蓄積できれば、それ自体が輸出可能な知的資産になりえます。
モデルは海外製、使い方は日本式。「日本式AI活用」のパッケージ化という絵は、少なくとも検討に値するシナリオではないでしょうか。
製造業の品質管理にAIをどう組み込むか。高齢者介護のオペレーションをAIでどう最適化するか。建設現場の安全管理をAIでどう強化するか。こうしたドメイン特化の実装ノウハウは、基盤モデルを持っているだけでは生まれません。現場のデータと業務知識を持ち、それをAIに接続する設計力が必要です。
もちろん「基盤モデルを全くやるな」という話ではなく、防衛・インテリジェンスのように国産が不可欠な領域はありますし、研究開発の継続にも価値がある。100Bモデルの開発経験はモデルの内部動作の理解を深め、活用側のスキルにもフィードバックされます。ただ、リソース配分の重心をどこに置くか、という議論はもっとあっていいと思います。
第8章:おわりに
前後編を通じて、けっこう率直なことを書いてきました。
国産LLMの売上構造。SIerの多重委託構造と人月商売の矛盾。DC需要の実態と「面にならない」GPU需要。米国との投資規模の桁違い。データ主権議論の飛躍。SaaS産業の地殻変動と大規模な時価総額の調整。基盤モデル企業のアプリ層進出。
居心地のいい話ばかりではなかったかもしれません。
ただ、見方を変えれば、日本には課題があり、データがあり、現場がある。刀を打つ勝負では分が悪いかもしれないけれど、刀の使い手としてなら、まだまだやれることはたくさんあるはずです。
使いこなす力を磨くのか、作る力にこだわるのか。その選択が、これからの数年間でかなり効いてくるのではないかと思っています。
この2本の記事を通じて見てきた構造から、企業としてまず考えるべきことがあるとすれば、単一モデルを前提とした設計を避けること、モデルの選定よりも先に業務設計とガバナンスの枠組みを置くこと、そして自前のモデル開発よりも、どんなモデルでも使いこなせる基盤とそれを担える人材への投資を厚くすることです。これが唯一の正解だとは言いませんが、少なくとも検討のテーブルには載せる価値があるはずです。

本稿で提示した3つの論点——マルチベンダー統合、データ統制・ガバナンス、業務コンテキストへの接続——は、基盤モデルの進化とアプリケーション層の再編が同時進行する構造変化のなかで、企業がAIを持続的な競争優位へと転化していくうえで避けて通れない戦略的要点であると、私たちは捉えています。
Qualitegは創業以来、先端AIの研究開発と事業実装の双方からこの問いに一貫して向き合い、技術と戦略の両輪でクライアントの意思決定を支えてまいりました。
私たちは、20種類以上のLLMを単一の基盤から切り替え可能にするエンタープライズLLMプラットフォームBestllam®、LLMの入出力を監査し情報漏洩を検出・遮断するLLM-Audit™、機微情報を高速・高精度に検出・匿名化するPII-Fi™を自社開発・運用しています。いずれも、特定のAIベンダーに属さない独立した立場だからこそ提供できる基盤として設計してきました。
同時に、外資系コンサルティングファームやグローバル企業での事業開発・技術戦略の経験を持つメンバーが、ビジネスコンサルティングとAIテクノロジーコンサルティングを通じて、戦略立案から技術検証、実装、現場定着までを一貫して担っています。戦略を描く段階から技術者が同じテーブルに座ることで、技術的実現性と事業的合理性を両立した、地に足のついた設計を心がけています。
AIをどう事業に載せるか——この問いに取り組まれている企業の皆さまの一助となれるよう、私たちも戦略と技術の両面からご一緒できればと考えております。
ご相談やディスカッションのご要望がございましたら、お問い合わせよりお気軽にお声がけください。



