
[自作日記3] グラボ2枚挿しの夢
![[自作日記3] グラボ2枚挿しの夢](/content/images/size/w1200/2024/04/gpu_machine_jisaku_03.png)
こんにちは!
今日の話題はレーン分割とグラボ2枚挿しについてです。
前回みてきたとおり、インテル Core シリーズCPUでは、CPUから接続されるPCI Express は PCIe gen5 で x 16(16レーン分)使えました。
PCIe gen5 は非常に高速で、そのレーンを16レーン使えるので、実質的にこの PCIe gen5 x 16 がグラフィックボード(GPU)用です。
実はマザーボードによっては、 PCIe gen5 x16 を2分割して使えるものがあります。
さて、ここで、もう1回、 z690 チップセットのブロック図をみてみましょう。
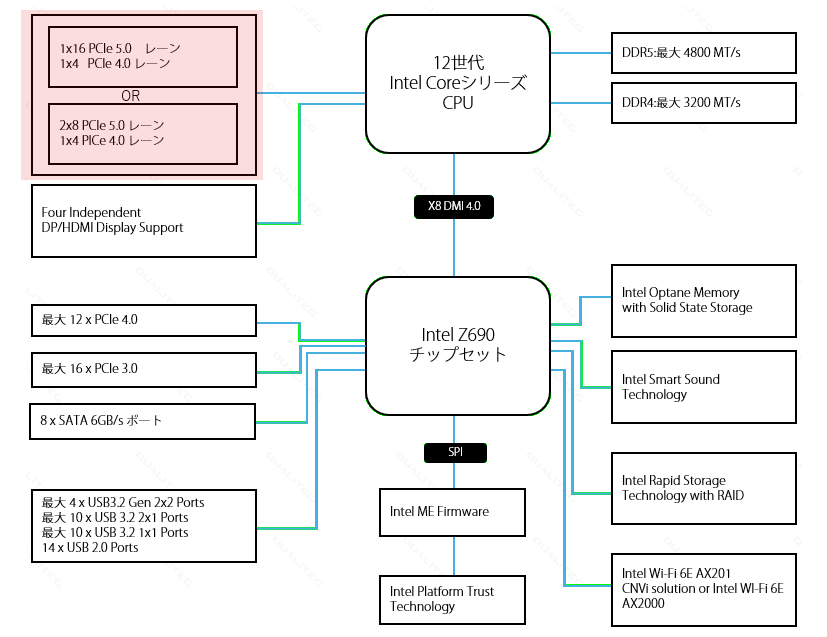
この左上の↓ですが、2つのボックスがあり、それの中間にORとかいてあります。
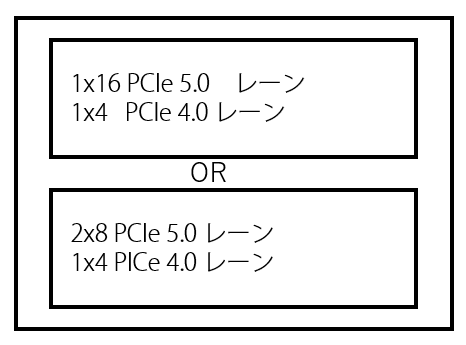
これは、「以下の2つのパターンのうち、どちらかを選択することができるよ」という意味になります
- 1x16 PCIe 5.0 ・・・ PCIe x16 の拡張ボードを1枚接続する
- 2x8 PCIe 5.0 ・・・ PCIe x8 の拡張ボードを2枚接続する
つまり、 PCIe 5.0 は全部で 16本用意してあるけど、1つのスロットで 16本全部つかってもいいけど、 2つのスロットで8本ずつつかうのもありというわけです。
これを レーン分割 と呼びます
レーン分割
このようにレーン分割を使うと、各グラボを x8 の PCIe gen5 として動作させることで、2枚のグラボを同時に使えることになります。
これが インテル Core シリーズのCPUでグラボ2枚挿しができる理屈です。
PCI Express gen5 であれば x8 (レーン8本) だとしても 32 gbytes/s の帯域をもつので、それ以上の帯域を要求されない使用用途であれば問題ないでしょう。
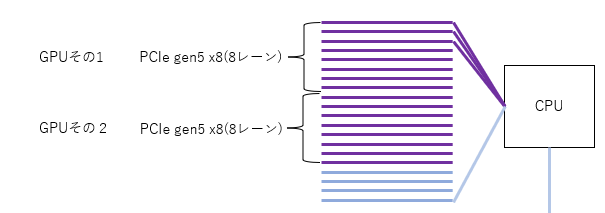
レーン分割はマザーボードの対応が必要
とはいえ、すべてのマザーボードがレーン分割に対応しているわけではりません。CPUがレーン分割に対応していても、マザーボードが対応していなければレーン分割機能は使用できません。
それではレーン分割できるマザーボードを実際にみてみましょう。
MSI から発売された MSI MPG Z690 CARBON WIFI はレーン分割に対応したマザーボードです。ゲーミング用のラインナップですが非常に安定した秀作マザーボードです。
以下は、マニュアルに記載 Expansion Slot(拡張スロット) に関する仕様を抜粋したものです。

一見、難しそうですが、
これまでのシリーズを読んでいただいていれば、すんなり読み解けるはずです。
さぁ、読み解いていきましょう。
1行ずつに①~⑥をふってみました。

① は、「3つの PCI Express x16 スロットが装備されています」と読み解けます。
これは、このマザーボードには全部で3つの x16 形状 をした PCI Expressスロットが装備されています。という意味です。形状が x16なだけです。以下を思い出してください、PCI Expressの ”スロット” の形状には x1,x4,x8,x16がありましたね。
それです。 PCI Express の内部接続レーン数ではない点に注意です。
次は②をみてみましょう

②は「PCI_E1 と PCI_E2 スロットは CPU とつながっています」と読むことができます。
はい、この意味もわかるとおもいます。そうです、このPCI_E1とPCI_E2 こそがGグラボ2枚挿しをするためのスロットです。
せっかくなので、実際のマザーボードで、 PCI_E1 スロットとPCI_E2スロットをみてみましょう。

上のようにPCI_E1とPCI_E2スロットが配置されていますね。
さらに、どちらも x16 タイプのスロット(横長ですね)であることがわかります。
次は③を読んでみましょう

③はPCI_E1は PCI_E2は「 PCI Express 5.0 をサポートしています。」ということがかいてあります。

④は、「 x16/x0 と x8/x8 をサポートしています」と書いてあります。
さてこれはどういう意味でしょうか。
これは、さきほど説明したレーン分割について説明している内容となります。
つまり、以下のように読み解くことができます
”x16/x0”の意味
これは以下のような意味をもっています
- PCI_E1スロットを PCI Express gen5 x16 として使用する
- PCI_E2スロットは 無効(使用できない)とする
どういうことかというと、 PCI_E1スロット のほうにCPUと接続されるレーン16本をすべて使ってしまうということです。そのため、PCI_E2のほうには残りのレーンが無く、レーン0本になり、実質的にPCI_E2スロットのほうに拡張ボードを挿しても使用することができない、ということです。
"X8/X8" の意味
はい、こちらは、もうお分かりの通り、
以下のような意味をもっています
- PCI_E1スロットを PCI Express gen5 x8 として使用する
- PCI_E2スロットも PCI Express gen5 x8 として使用する
これが、仕様ではあのように簡単な表記で表現されています。慣れている人なら、すぐにわかりますが、慣れないと、何をいってるのか難しいところがありますね。
つまり、このマザーボードMSI MPG Z690 CARBON WIFI は X8/X8 モードをサポートしており、 X8/X8 モードを使用することで、 1枚のグラボあたり 8本のレーンを使用したグラボの2枚挿しができるというわけです。
最後に⑤⑥も一応みておきましょうか。

⑤は 「PCI_E3スロットは Z690チップセットに結線されています」
⑥は、PCI_E3スロットは PCI Express 3.0 x4 規格をサポートしています」
を意味しており、チップセット側と接続されるレーンは低速の規格であることを読み解くことができます。
PCIe3.0 x4 ということで PCI Express 3.0 規格のレーンが4本チップセットと接続されていますが、スロットの形状は x16 である点をもう一度おさえておきましょう。
まとめ
今回はPCI Express のレーン分割と、グラボ2枚挿しについて解説しました。
AI用GPUマシン自作の知識は深まってきましたでしょうか。
私たちは AI の研究や開発のための個人用パソコンで、グラフィックスボードの2枚挿しをしたいシーンがたまにありますので、その際には今回のノウハウが役にたちますが、グラフィックスボードは高性能なものほど高熱となり、2枚挿しをした環境で高負荷な処理を継続的に行うと、廃熱などエアフローに関しても適切な知識が求められますので、2枚挿しをするときには、PC自作に詳しい専門家の方の相談を仰ぎましょう。秋葉原には相談できる店員さんもたくさんいらっしゃいます。
また、グラボ複数枚挿しにはインテルCoreシリーズよりもインテル Xeon シリーズのほうがはるかに向いており、本格的なAI用途の場合はそちらがおすすめです。こちらについても、別記事で触れていきたいと思います。
事前知識はこのへんにして、
次回からは実際にGPU搭載マシンを作っていこうとおもいます!
それでは、また次回お会いしましょう!
navigation




{kind=link}