
[自作日記15] SW編:Ubuntu インストール手順
![[自作日記15] SW編:Ubuntu インストール手順](/content/images/size/w1200/2024/04/gpu_machine_jisaku_15.png)
こんにちは!
前回つくったUSBドライブから、Ubuntu 22.4 をGPUマシンにインストールしていきましょう!
2.0 LANケーブルを接続する
インストールする前に、GPUマシンにLANケーブルを接続してインターネットが使える状態にしておきましょう。
2.1 USB メモリからブートする
2.1 で作成した USB メモリ を GPUマシンのUSBポートに挿します

USBドライブを挿したら、
PCケースの電源ボタンを押して電源を入れましょう。
するとマザーボードの初期起動画面が表示されるので キーボードで F11 を押しながら待ちます

ブートデバイスを選択する画面がでたら、 UEFI: USB を選択してエンターを押します
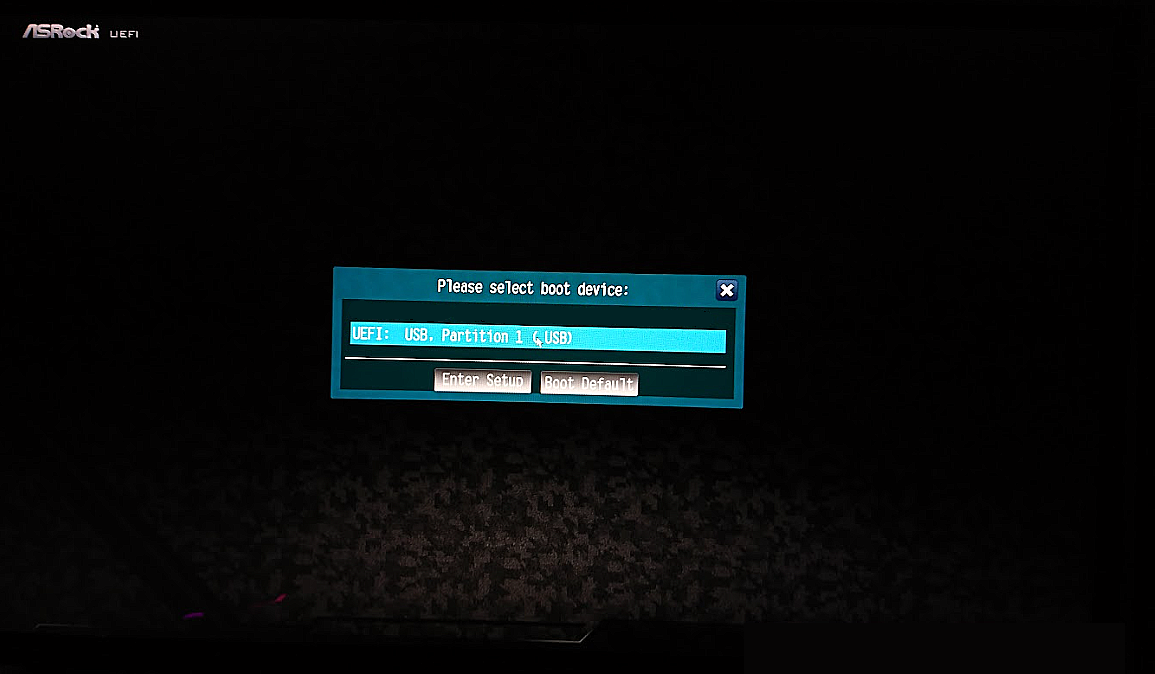
しばらくすると Ubuntuのインストール画面が表示されるので

Try or install ubuntu を選択してエンターを押します
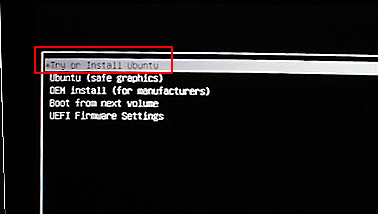
これでUbuntu のインストールが開始するのをまちます
2.2 Ubuntu OS のインストール
Ubuntu OS のインストーラーが開始したら、Ubuntuをインストールをクリックします
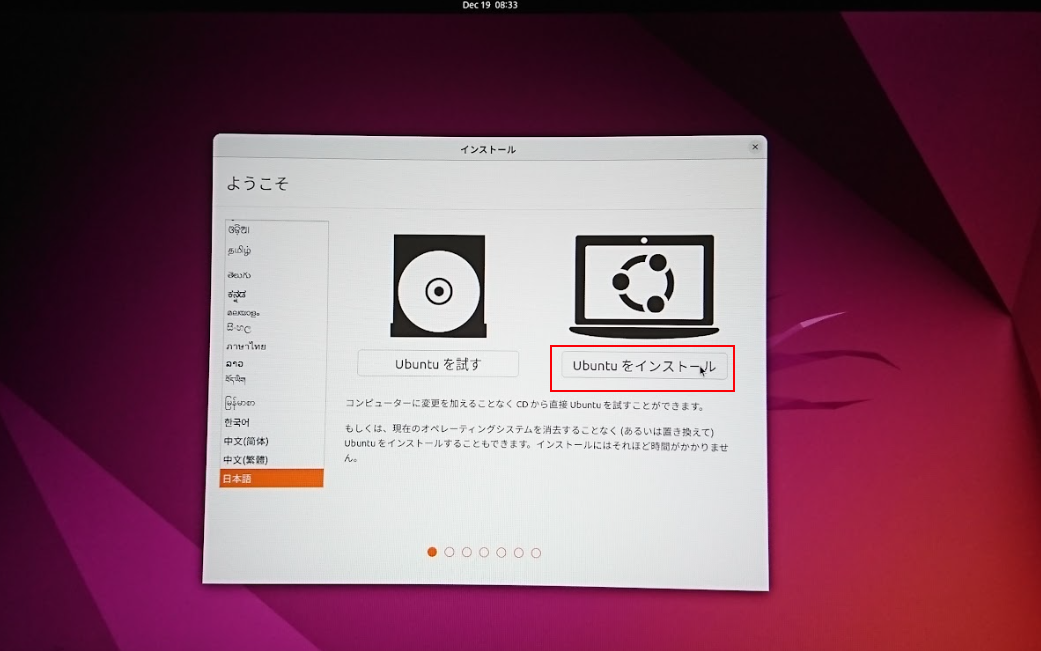
言語設定を Japanese にしました
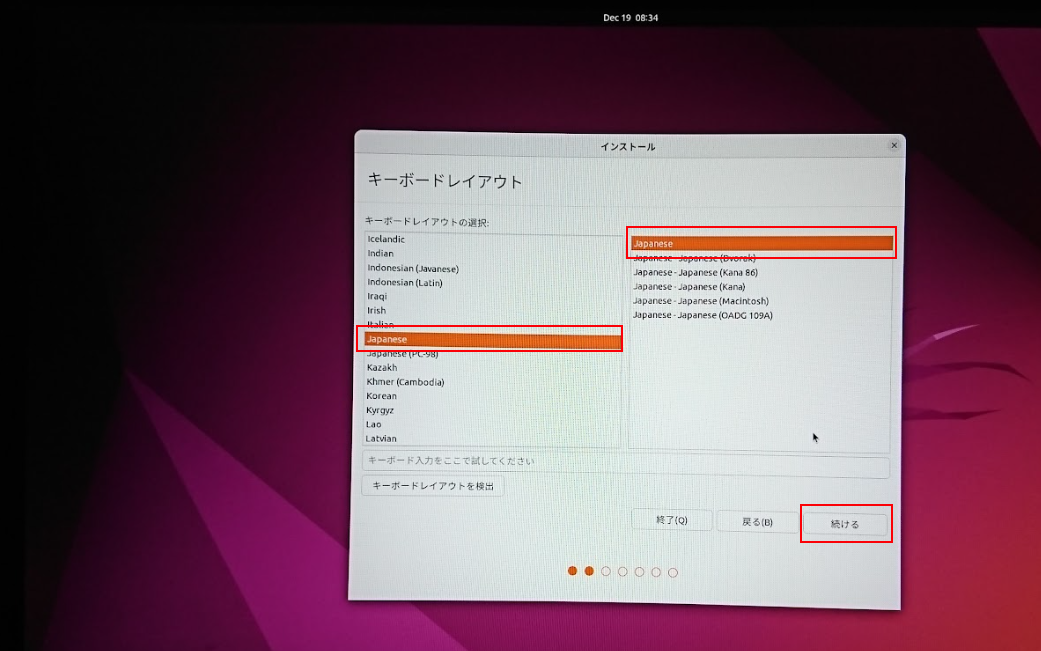
無線設定 の画面ですが 有線LAN で接続されている場合は、なにもせず 続ける をクリックします
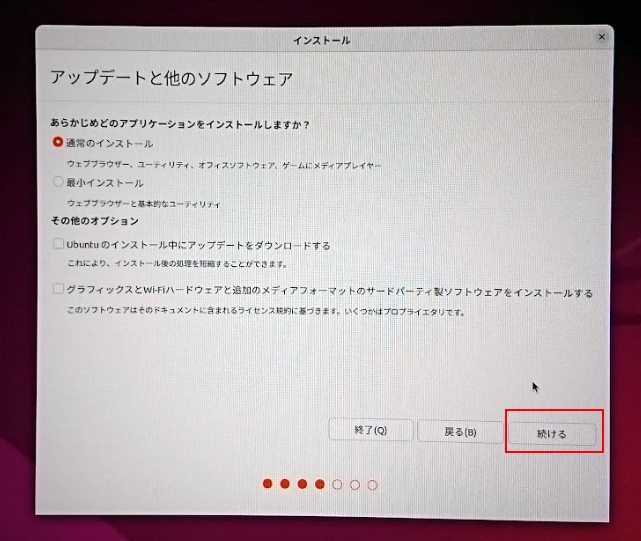
アップデートと他のソフトウェア の画面では 通常のインストールのみにチェック が入っている状態にして続けるをクリックします
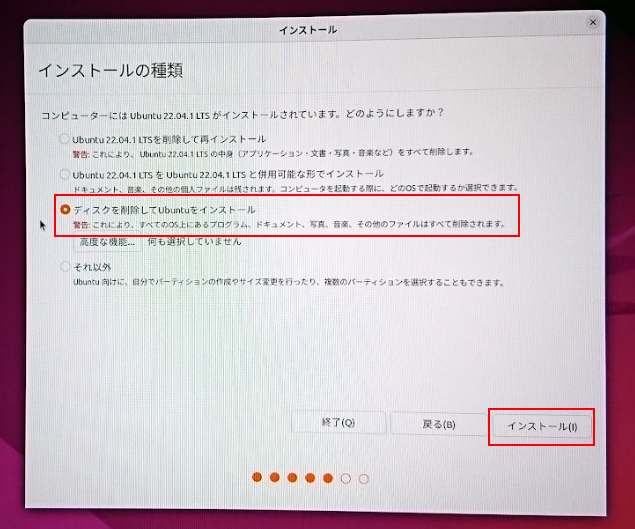
インストールの種類 の画面では、 SSDをまっさらな状態にしてインストールするので
ディスクを削除してUbuntuをインストールを選択しインストールをクリックします
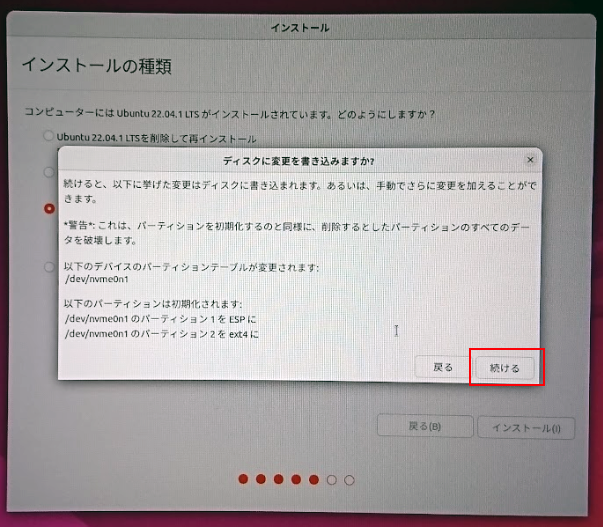
以下のような警告がでますので、確認してクリックをします
ロケールの画面では Tokyo になっているのを確認して、続ける をクリックします
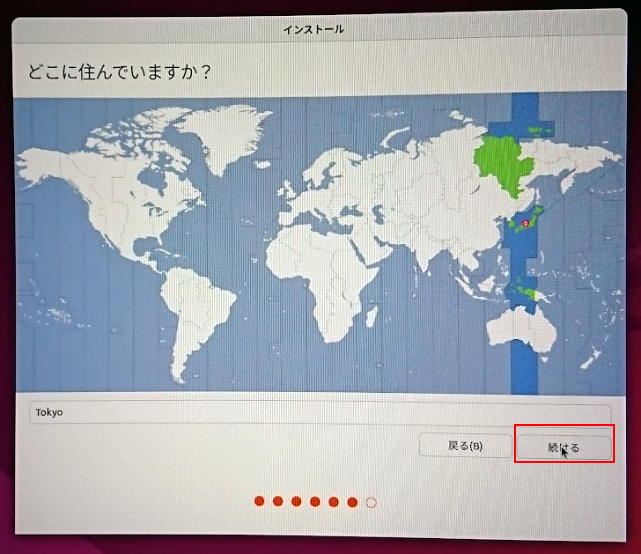
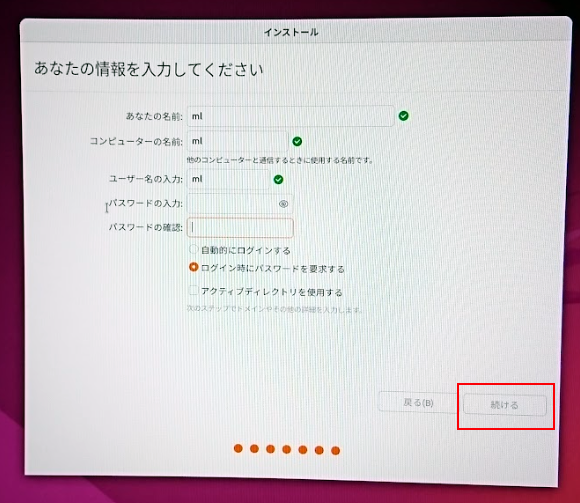
次にユーザー名とコンピューター名を入力して、 続ける をクリックします
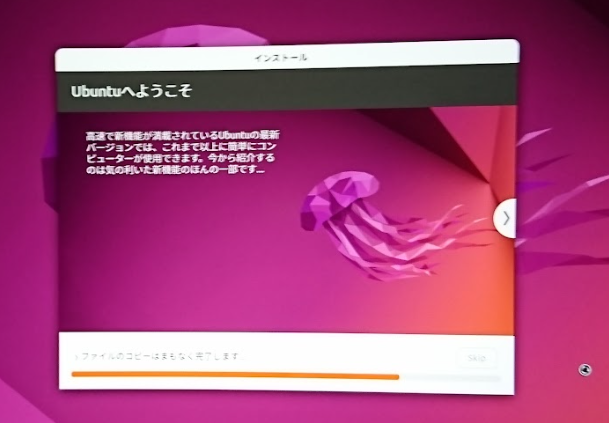
ここまで進むと、ファイルコピー等がはじまりしばらくすると Ubuntu OS のインストールが終了します。
OSのインストールはここまでです、おつかれさまでした。
自作の先に、研究・業務用のGPU環境を考えるなら。
GPUマシンを自分で組む知見は、そのまま研究・PoC・本番のインフラ選定に効きます。
私たちは自社で独自の GPU クラスターを構築・運用し、LLM プロダクトを開発しています。また研究用GPUワークステーションの調達から、インテル Core アーキテクチャ、インテル Xeon アーキテクチャなど、コンシューマーユースからプロユースまで幅広くご支援可能です。ワークステーションの調達・構築支援だけでなく、その先の学習環境の整備、最適な GPU 選定・推論最適化・分散構成まで、運用経験に基づいてアドバイスします。
LLMインフラ・基盤技術の支援を見る →次回は Ubuntu の初期設定をやっていきましょう
navigation



