
[自作日記16] SW編: GPUマシンの Ubuntu を構成する
![[自作日記16] SW編: GPUマシンの Ubuntu を構成する](/content/images/size/w1200/2024/04/gpu_machine_jisaku_16.png)
こんにちは!今回は Ubuntu OS インストール後の構成をします
3.1 Ubuntu の構成
3.1.1 初回起動時の各種アップデート
現在、Ubuntu OS のインストールが終了した状態となってますが、Ubuntu OSアップデートや言語パックのアップデートなどが表示されていた場合、それをまず実行します
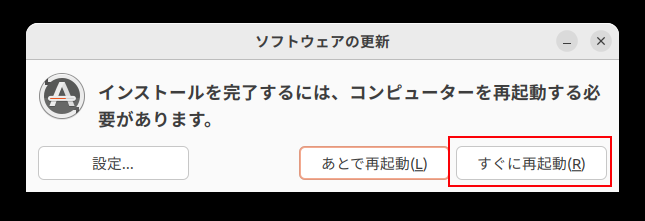
初回に表示されるアップデートが終了したときに以下のようなダイアログが表示されるのですぐに再起動をクリックしていったんリブートします
3.1.2 日本語 IME の設定
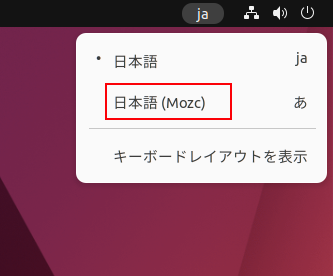
画面右上にある日本語IMEを選択します
3.1.3 ”downloads” ディレクトリの作成
ダウンロードファイルの保存先用に "downloads" ディレクトリを作成します。
日本語の「ダウンロード」ディレクトリがもともとあるが、端末(shell)から扱いにくいですし、日本語フォルダ名は何かと不便なためです。
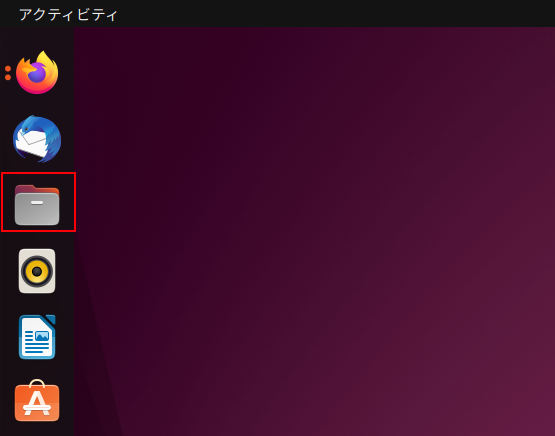
画面左バーからファイルを起動します
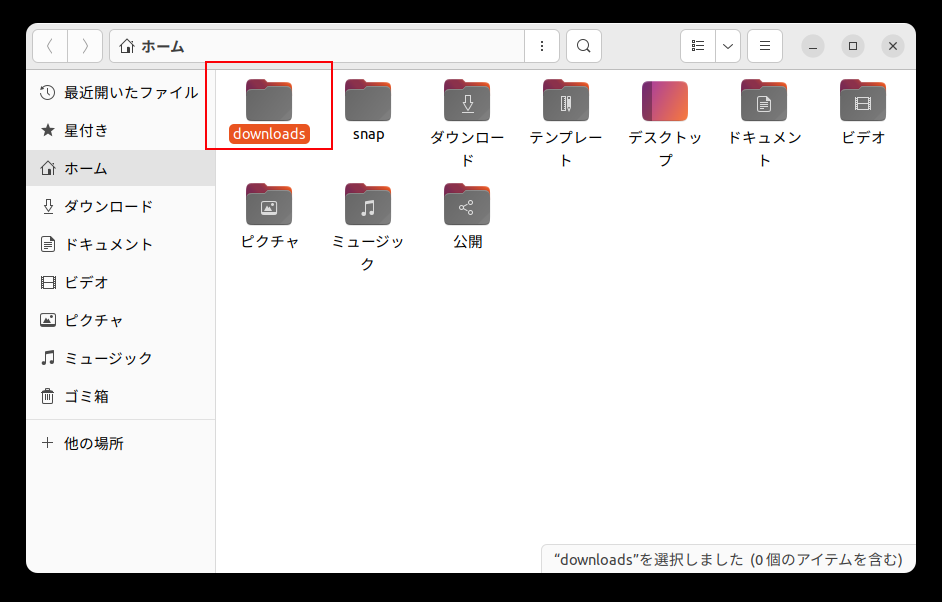
ホームディレクトリ以下にdownloadsというディレクトリを作成します
3.1.4 Firefox(ブラウザ)の設定
左側バーから、Firefoxを起動します
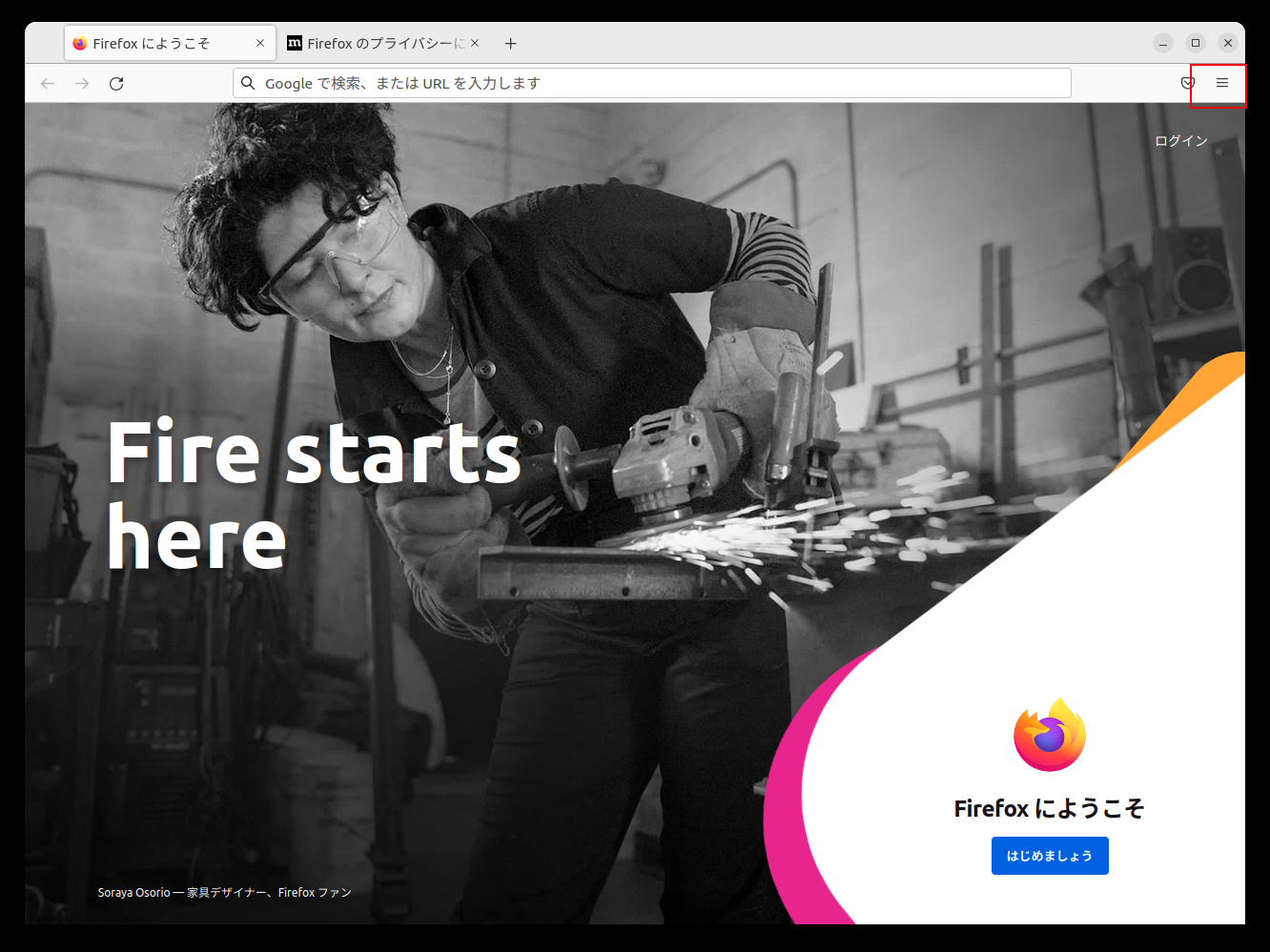
Firefox画面の右上にあるハンバーガーメニューをクリックし、
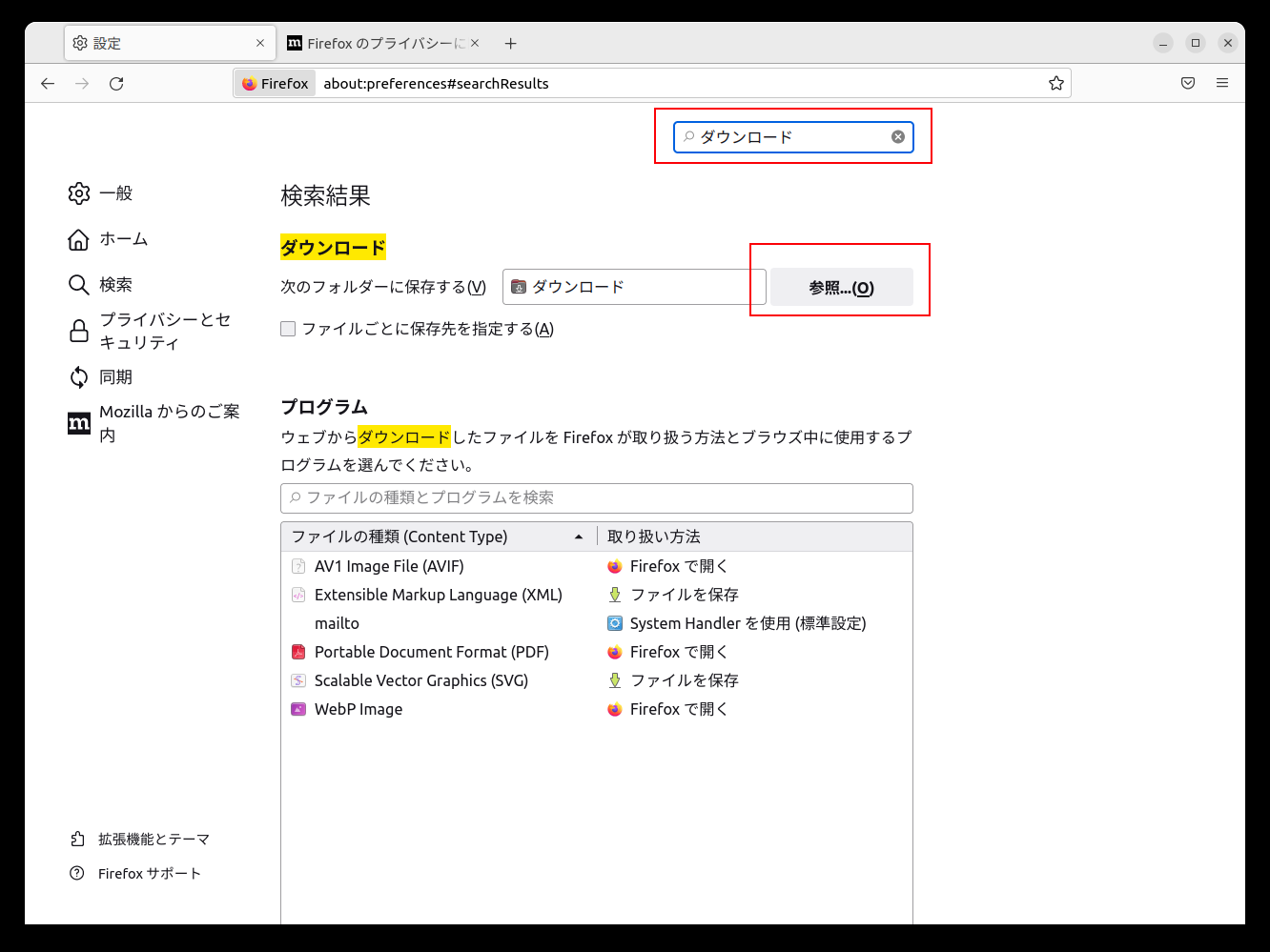
設定画面が表示されるので検索窓にダウンロードと入力すると、
ダウンロード先ディレクトリの設定画面がでるので参照をクリックし、
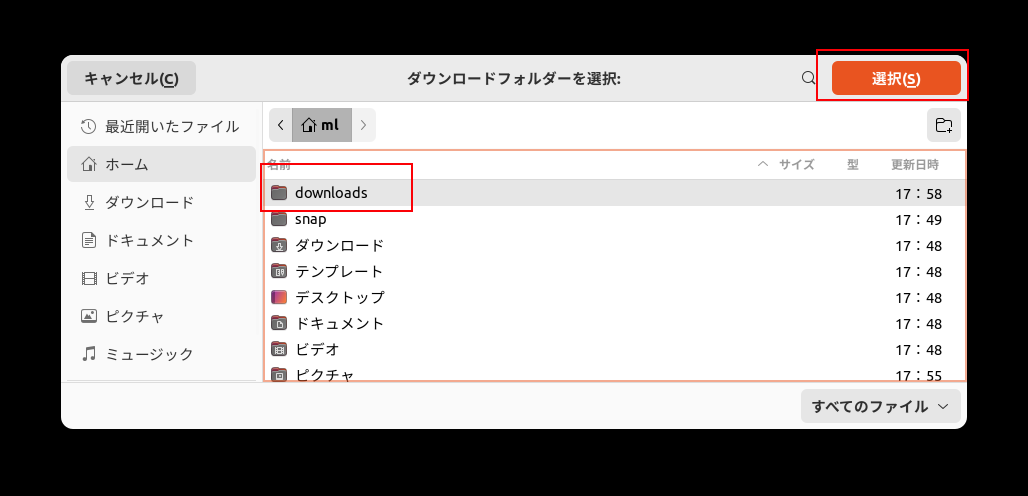
さきほどつくったdownloadsディレクトリを選択します
これで、Firefoxのデフォルトのダウンロード先が downloads となりました
3.1.5 端末(shell)を左側バーに入れる
左側バーはいわゆる「お気に入り」ですね。よく使う端末はそこにいれておきます
- 画面左下のメニューボタンをおして、アプリ一覧を表示します
- そこにある端末をクリックして起動して、

左側バーに表示されてるアイコンを右クリックしてお気に入りに追加をやっておきましょう
さて、最低限の構成ができました
次回は、 GPU用のNVIDIA Display Driver をインストールします!
navigation



