
[自作日記18] SW編: Anacondaのインストール
![[自作日記18] SW編: Anacondaのインストール](/content/images/size/w1200/2024/04/gpu_machine_jisaku_18.png)
今回は、 Anaconda を導入します。
Python は一般的にアプリケーションごとに仮想環境を使用して実行しますが、仮想環境を構築できるものに Anaconda または Python純正仮想環境の venv のどちらかがよく使われます。
今回は、 Anaconda を導入してみたいとおもいます。
4.1 Anaconda(Python環境) のインストール
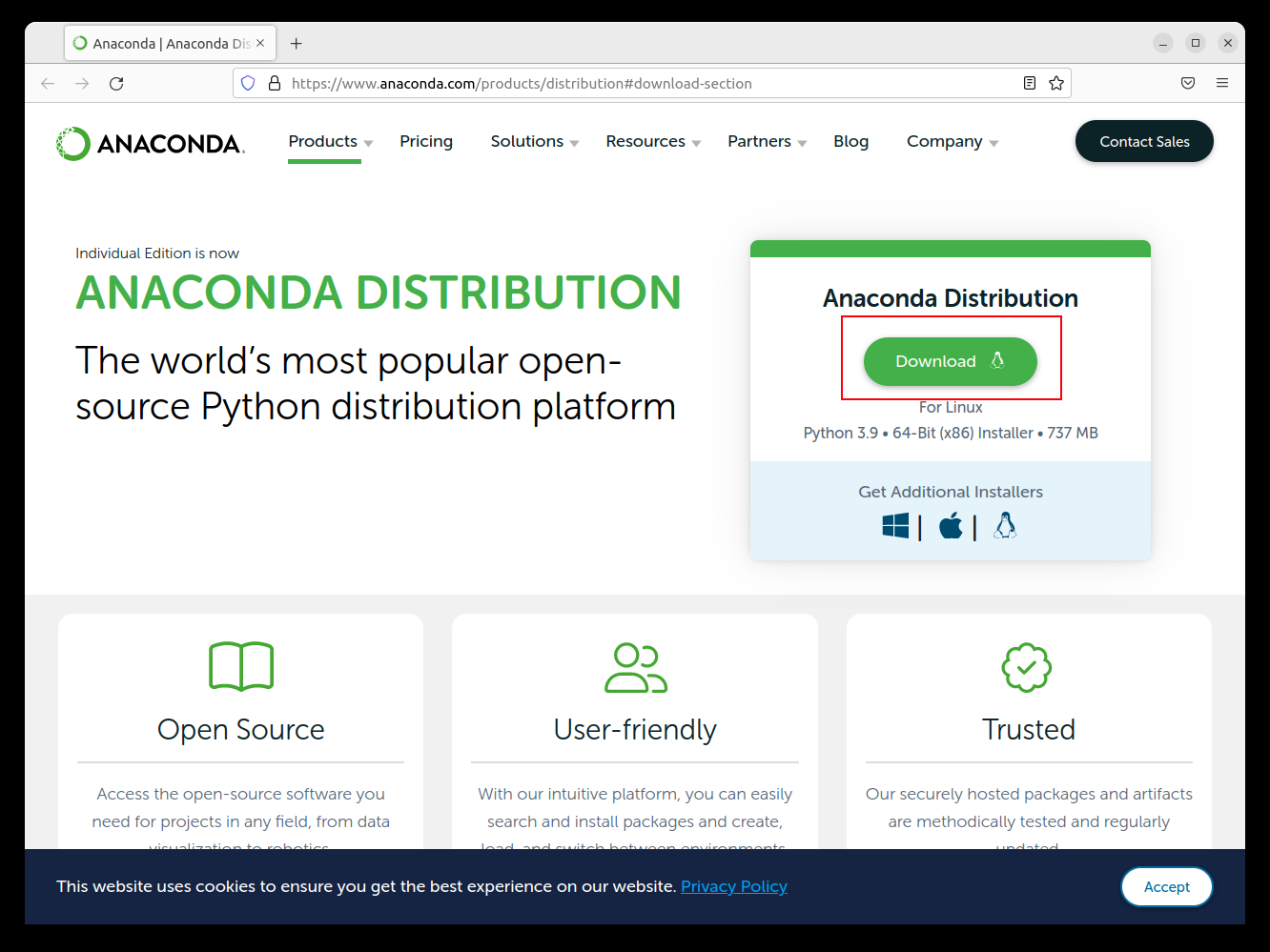
STEP1 Anaconda3 をダウンロードする
Chromeを開いて、以下を開きます
https://www.anaconda.com/distribution/#download-section
自動的に Linux 用を表示してくれるので、それをダウンロードします
STEP2 インストール用スクリプトを実行する
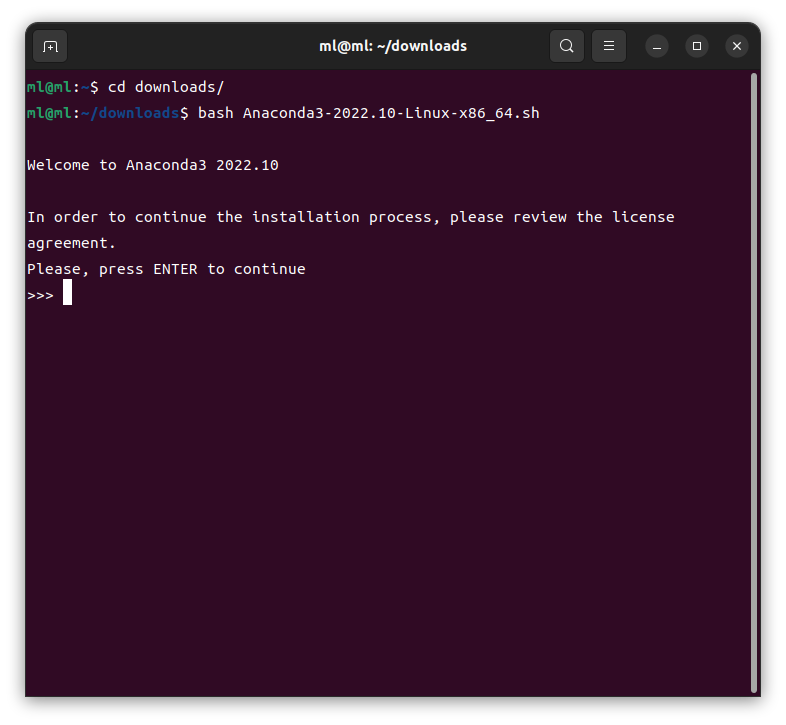
cd downloads
bash Anaconda3-2022.10-Linux-x86_64.sh
エンターキーをおすrと、 license agreement をスクロールさせることができます
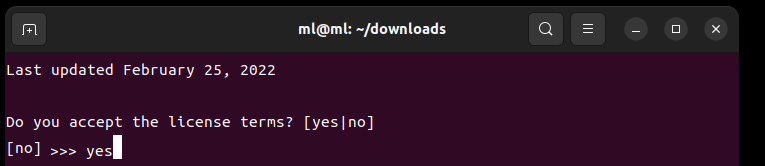
内容問題なければ yes とタイプします
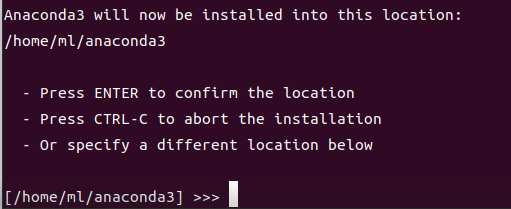
以下の図のように、Anacondaのインストールディレクトリがこれでいいかきいてくるので、エンターを押して保存先を確定します
こうしてインストールが終わると、
Do you with the installer to initialize Anaconda3 by running conda init? [yes|no]
(「conda initをしてAnaconda3を初期化するかい?」と聞いてくるので)
yes
と入力します
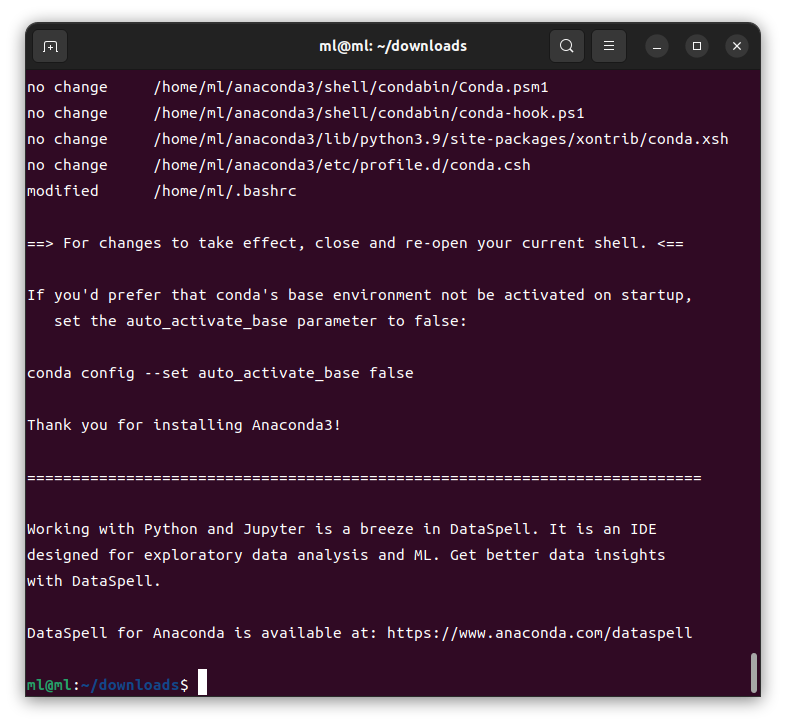
これで、Anaconda3のインストールが完了しました!
また、Pythonのインストールも同時に完了しました!
STEP3 Pythonが動作するかを確認する
Anacondaのインストールが終わったら、いったん、端末(ターミナル)を閉じて、再度 端末(ターミナル)を開きます。
端末(ターミナル)を開き直したら以下のコマンドで、インストールされたPythonを確認してみましょう
Pythonのバージョン
$ python --version
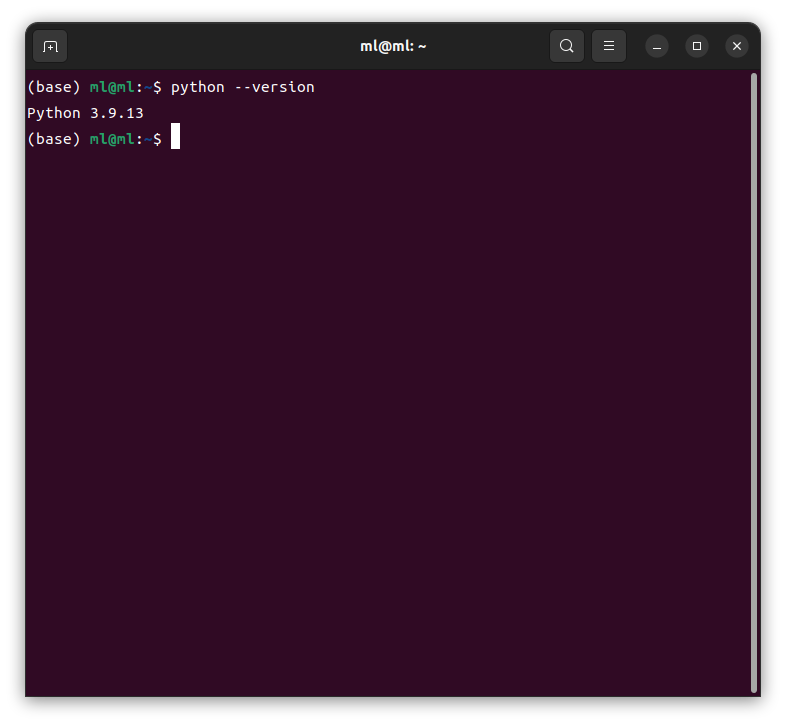
これでPythonが無事インストールできました!
この段階で、Python やcondaコマンドもインストールされており、Pythonの基本的な開発ができるようになりました!
自作の先に、研究・業務用のGPU環境を考えるなら。
GPUマシンを自分で組む知見は、そのまま研究・PoC・本番のインフラ選定に効きます。
私たちは自社で独自の GPU クラスターを構築・運用し、LLM プロダクトを開発しています。また研究用GPUワークステーションの調達から、インテル Core アーキテクチャ、インテル Xeon アーキテクチャなど、コンシューマーユースからプロユースまで幅広くご支援可能です。ワークステーションの調達・構築支援だけでなく、その先の学習環境の整備、最適な GPU 選定・推論最適化・分散構成まで、運用経験に基づいてアドバイスします。
LLMインフラ・基盤技術の支援を見る →次回は、 CUDA と Pytorch をインストールします
navigation



