
[自作日記19] SW編: CUDA と Pytorch の導入
![[自作日記19] SW編: CUDA と Pytorch の導入](/content/images/size/w1200/2024/04/gpu_machine_jisaku_19.png)
今回は CUDA と Pytorch をインストールします
4.2 CUDA(+cuDNN) と Pytorch の同時インストール
Pytorch をインストールすると、CUDA と cuDNN を一緒にインストールしてくれるので、それを活用しましょう
STEP1 PyTorchのインストールコマンドを生成する
さて、ようやくお膳立てができたので、いよいよ機械学習ライブラリ PyTorch を導入しましょう
■ PyTorchのインストール
以下にあるPyTorchのインストールガイドを開き、
https://pytorch.org/get-started/locally/
以下のように選択式で Pytorch のインストールコマンドを生成することができます
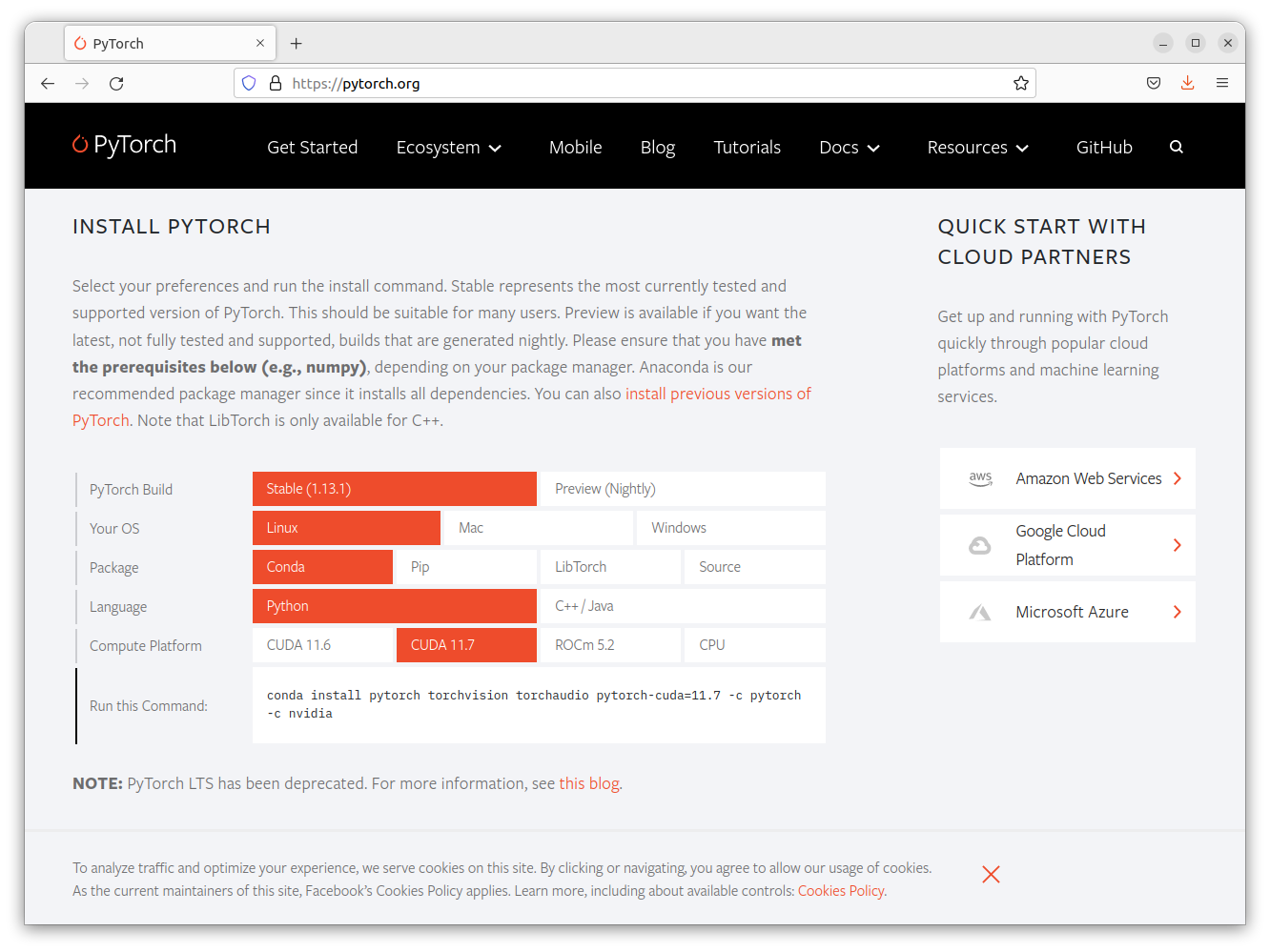
| Category | Selected |
|---|---|
| Pytorch Build | Stable (1.13.1) |
| Your OS | Linux |
| Package | Conda |
| Language | Python |
| Compute Platform | CUDA 11.7 |
この設定で以下のようなインストールコマンドが生成されました
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
STEP2 Pytorch をインストールする
(1) 端末を開いて、
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
を実行します
(2) yを入力すると必要パッケージのダウンロードとインストールが開始される
(3) 10分程度待つと、インストールが終了する
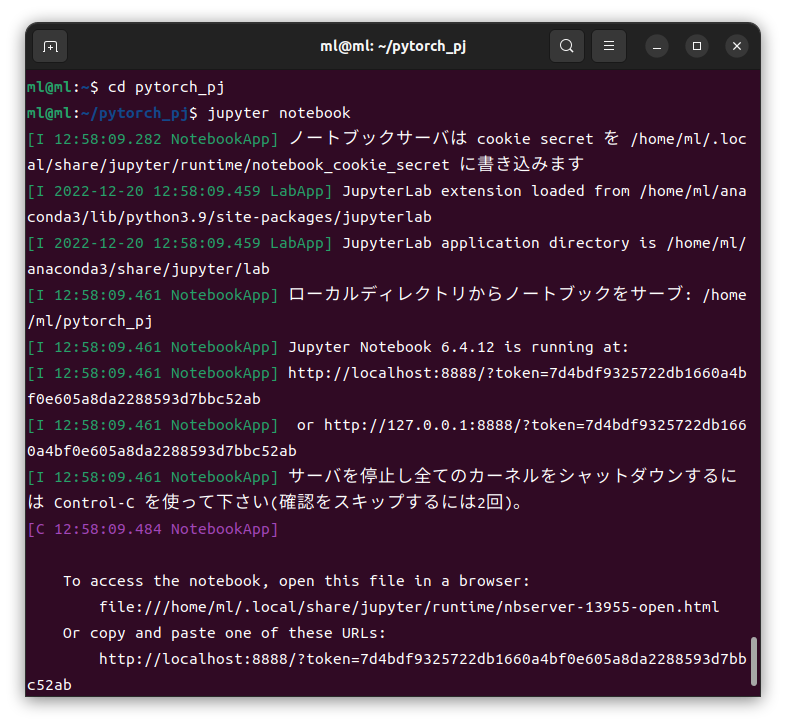
これにて、NVIDIA GPU対応のPyTorchのインストールが完了しました
PyTorchの場合は、上記 condaコマンドで CUDA Toolkit 10.0 もあわせてインストールしてくれるし、cudnnはPyTorchに組み込まれた状態のものを、さきほどのcondaコマンドでインストールしているため、別途インストールする必要がなくて便利です
自作の先に、研究・業務用のGPU環境を考えるなら。
GPUマシンを自分で組む知見は、そのまま研究・PoC・本番のインフラ選定に効きます。
私たちは自社で独自の GPU クラスターを構築・運用し、LLM プロダクトを開発しています。また研究用GPUワークステーションの調達から、インテル Core アーキテクチャ、インテル Xeon アーキテクチャなど、コンシューマーユースからプロユースまで幅広くご支援可能です。ワークステーションの調達・構築支援だけでなく、その先の学習環境の整備、最適な GPU 選定・推論最適化・分散構成まで、運用経験に基づいてアドバイスします。
LLMインフラ・基盤技術の支援を見る →次回は、実際にGPUを活用したPytorch コードを書いてみます!
navigation



