
ChatGPTによるAI革命と今後の展望


今日は ChatGPT による革命と今後の展望について書いてみたいとおもいます。
ChatGPTはほとんどの業界に大きな影響を与えているのは周知のとおりです。
このテキストベースのAIは、業務の自動化と効率化に貢献しており、その影響は広範囲に及ぶと予想されます。しかし、ChatGPTの成長と進化の途上には、いくつかの課題が存在しています。ここでは、ChatGPTが引き起こすAI革命、その業界への影響、そして将来への展望について掘り下げていきたいとおもいます。
ChatGPTによる業界の変革
ChatGPTは、既に世の中の9割の業界で劇的な変化をもたらしているといわれています。このAI技術は、顧客サービスからマーケティング、保険、HR、さらには開発まで、幅広い分野で業務の自動化と効率化を実現しています。
(我々の開発でもこれまで人間がやっていた仕様書定義・整理や単体テスト設計などで絶大な効果をあげています。)
例えば、顧客サービスでは、ChatGPTを用いたチャットボットが24時間体制で顧客の問い合わせに応じることが可能になり、人的リソースの負担を大幅に軽減しています。また、コンテンツ作成やコードの自動生成など、従来、人間らしい創造的なタスクといわれていた分野にもChatGPTが活躍しており、業務の質とスピードの向上に貢献しています。
成長の限界と今後の方向性
しかしながら、ChatGPTの成長には、公開データのみを利用した学習に限界があるという疑問が残ります。約13兆トークンのデータで学習されたChatGPTも、インターネットやWikipedia、有料コーパスなどの公開データに依存しています。これらのデータには、必然的に限界があり、AIの理解と応用の幅を制限しています。
モデルサイズを大きくすると賢くなる というスケーリング法則が正しいとすると、賢くするためにはモデルサイズを大きくしなくてはならず、モデルサイズが大きいということは、それだけ多くのパラメータ・ウェイトが満腹になるだけのデータを食べさせてあげる必要があるからです。
データの量を増やすには幅方向と深さ方向があります。幅方向はよりWikipediaに代表されるような広範な知識。一方、深さ方向は特定の領域に関する専門性の高い知識。これら知識を含むデータをどれだけ集められるかですが、直近のムーブメントは深さ方向に焦点が当たるでしょう。
つまり、”特定業界に特化”して、その業界データ、または、企業固有データを取り込んで、どのように成長させていくか、という軸の動きが活発になっていくと考えています。
企業固有のデータや専門的な業界データを学習に組み込むことで、ChatGPTはより具体的で専門的な知識を持つことができ、特定業界におけるより高度なタスクの実行が可能になります。
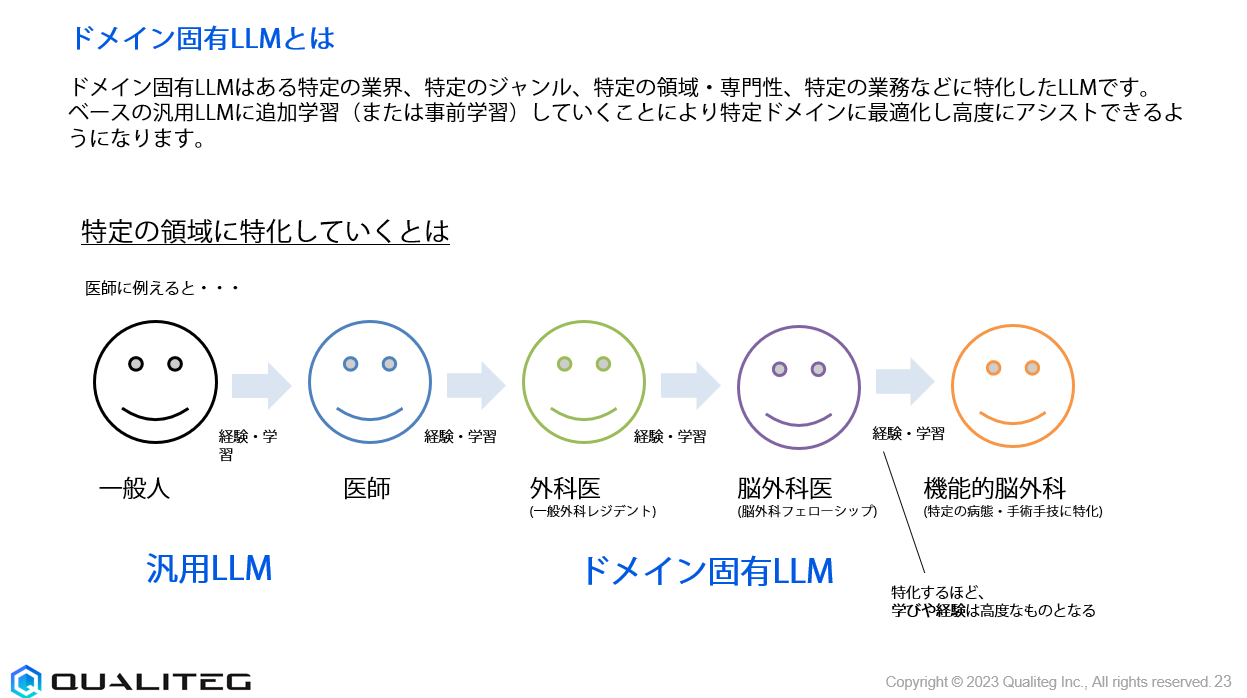
業界特化(ドメイン固有)への進化
ChatGPTが多くの業界で広く受け入れられる中で、各業界特有のニーズへの対応が求められています。初期段階では、ChatGPTは一般的なタスクで広く活躍しますが、企業は自社固有のデータや業界特有の課題解決を求めるようになります。たとえば、金融業界では、規制遵守やリスク管理に関する深い理解が求められ、医療業界では、患者のプライバシーを保護しながら、個々の医療記録を分析する能力が必要になります。
オープンLLM勢の影響
AI界隈、特にオープンLLM(Large Language Models)に焦点を当てた時、OpenAI、Anthropic、Cohereといった大手LLMプロバイダーだけでなく、オープンソースのLLMプロジェクトにも目を向ける価値があります。我々にも深く関係のあるオープンLLMプロジェクトはどうなるでしょうか。私たちは、「業界特化」がオープンLLM勢にとっての大きなチャンスになると考えています。
現在、多くのオープンLLMプロバイダーは、性能をChatGPTに近づける、あるいはそれを超えることに注力しています。しかし、"一般知識"における一定レベルの性能達成後、次なる焦点は、特定の業界や領域に特化したモデルの構築能力に移ります。ここでのキーポイントは、特定業界の深い知識を活かした事前学習の効率化と、それに伴うファインチューニングのバランスです。短い開発期間(TAT: Turn Around Time)でこれらを実現することが、技術的な挑戦となります。
たとえば、医療や法律などの専門分野では、専門用語の理解と適用が必須となります。これらの分野での高度なタスクをこなせるLLMを開発するためには、専門家の知識を取り入れた訓練データの収集や、特定分野での事例に基づいたファインチューニングが不可欠です。さらに、ファイナンスやエネルギー分野では、市場の動向や規制の変更にタイムリー・迅速に対応する能力も求められるでしょう。これらの業界特化モデルの開発には、業界固有のデータ収集や、リアルタイムのデータ処理能力が重要となります。
これらの進化に伴い、ChatGPTが占める市場は一強ではなくなり、多様な「業界特化」モデルを提供できるプロバイダーが台頭してくると(期待を込めて^^)予想しています。これらのモデルを支えるためには、強力な推論プラットフォームと、推論アプリケーションを支える基盤・フレームワークが不可欠です。当社が提供するChatStreamや関連サービスは、この新たな時代における業界特化モデルの開発と展開を強力にサポートします。これにより、顧客はタイムリーに、そして柔軟に業界特化の問題解決を行うことが可能となります。当社の技術が、次世代のLLMの展開において、どのように価値を提供できるかを考えることは、非常に刺激的です。そして楽しい!
navigation



