
CyberAgentLM3-22B-Chat(cyberagent/calm3-22b-chat) 徹底解説

こんにちは、(株)Qualiteg プロダクト開発部です。
本日は昨日プレスリリースされた サイバーエージェント社の最新LLM CyberAgentLM3-22B-Chat(cyberagent/calm3-22b-chat) について、ファーストルックレポートを行います。
デモ
実際に、以下サイトで calm3-22b-chat とチャットお試し可能です

https://chatstream.net/?ws_name=chat_app&mult=0&ontp=1&isync=1&model_id=calm3_22b_chat

オープン・フルスクラッチモデルでリーダーボード最高評価
本モデルは、このモデルは、既存モデルをベースに用いずスクラッチで開発を行なった225億パラメータのモデルで Nejumi LLM リーダーボード3の総合評価で 700億パラメータのMeta-Llama-3-70B-Instructと同等性能となっているようです。
継続事前学習ではなく、フルスクラッチの日本語LLMという点にも注目です。
以下は日本語LLMリーダーボード1つ、Nejumi リーダーボード3ですが、総合評価で70Bクラスのモデルと同等の性能を示していますね。
さらに、Nejumiリーダーボード3からは言語モデルの汎用性能だけでなくアラインメントに関する評価も加わっており、汎用性能とアラインメントを両者総合した評価で上位に入っているというのが興味深いですね。
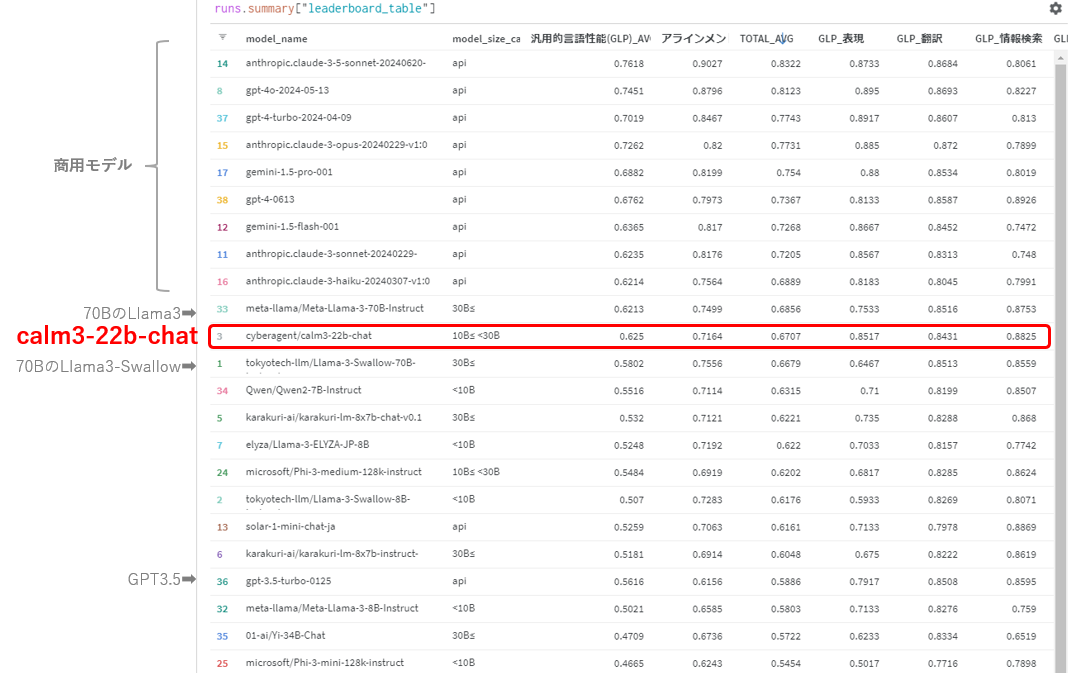
https://note.com/wandb_jp/n/nd4e54c2020ce#d0dec68f-f64d-440b-80f6-f2075d0d014a
上記ブログによると、アラインメントでは、モデルの安全性や制御性に関する評価を行っており、つまるところ、道徳的に間違ったことを言わないか、社会的バイアスがかかっていないか、などの点が評価にはいっています。
株式会社 AI Shift・株式会社サイバーエージェントが提供する、要約や広告文生成、Pro/Conのリストアップという3つのタスクに対してフォーマット・キーワード・NGワード・文字数をいかに制御することができるかを評価する評価データ・フレームワークです。
ただし、アラインメントの評価設計にはサイバーエージェント社のタスクが使われているというところもあり、現状、サイバーエージェント社にとってこの評価はやや有利に働いた可能性もありますが、サイバーエージェント社はRinna社とともに日本語LLMの最古参ですので、それまでの経験、高品質なデータセットの準備など相当入念な準備と努力、そしてGPUパワーによる結晶であると思います。このようなモデルをOSSでおしげもなく公開する企業姿勢に敬意を表します。
さて、LLM開発に携わっていると、ベンチマークはあくまでも参考値、実際の用途で使用して初めて体感値がわかるものですので、それはひとつの参考として、実際に使ってみるのが一番良いでしょう。
実際に試してみました
ということで、ChatStream に calm3-22b-chat をホストして calm3-22b-chatとのチャットを実際に試して、以下の動画にまとめました。
GPU環境と推論ソフトウェアの構成
今回は、以下のような構成でLLMチャットを構築しました。

LLMをチャット化するための構築時間は、モデルの種類にもよりますが今回は30分程度で完成しました。
さて、ポイントですが、今回はモデルサイズが 22.5B でしたので、16bit 精度でだと 45GB 程度のモデルフットプリント(モデルの重みパラメータがGPUメモリにロードされ占有されるメモリ量)となりますので、その 1/4 の 4bit 精度に量子化して NVIDIA A5000 にロードしました。
量子化したあとのフットプリントは実測値で 13GB 程度でしたので、今回使用したGPU A5000 (24GB) でゆとりをもってロードすることができました。

図のように、残りのメモリは実際の生成において使用されます。
古典的な生成処理では、今回のLLMを含む多くの自己回帰型モデルでは1トークン生成するごとに、それまでの生成結果を入力し、新しいトークンを生成しますので、そのとき、それまでの生成の計算処理を効率化するために、過去の計算で用いた値(K値、V値)をキャッシュしておきます。
これは1トークンごとに必要になりますので、いちどに取り扱うシーケンス長(トークン列の長さ)が長いほど、多くのKVキャッシュ用メモリを消費します。また、このような生成処理の同時リクエストが多いほど、当然、必要になるKVキャッシュは大きくなりますので、KVキャッシュ領域は多いに越したことはありません。
KVキャッシュの必要領域は、最大シーケンス長、最大同時アクセス数によって計算可能ですので、それは別記事にて詳細にご説明しようとおもいます。
当然、こうしたKVキャッシュ(たりない)問題について各種テクニックが生み出されており多くの推論エンジンでは、KVキャッシュを工夫し使用できるメモリ量を減らす方向で改善がなされていますが、ベースラインとしてこの考え方は重要ですので、商用LLMサービス開発の際は厳密な机上計算を行いGPUをプロビジョニングします。
calm3-22b-chat の諸元値
さて、話が若干それてしまいましたが、モデルの主要なパラメータについても以下に記載します。
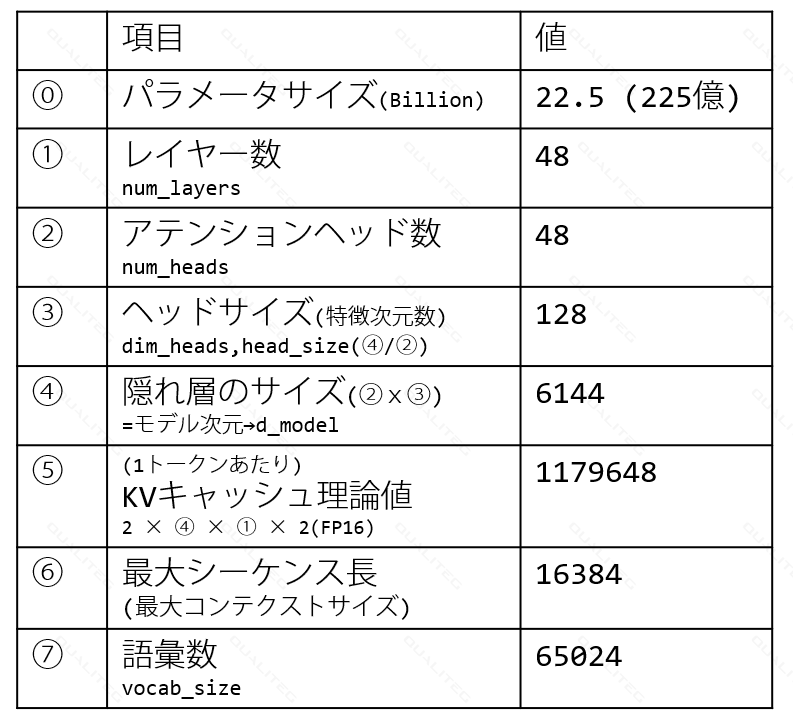
表にあるように、各種パラメータからKVキャッシュ理論値を求めることが可能です。
他特筆すべき点はそんなにありませんが、語彙数は最近のQWenやLlama3 に比べると半分程度なので、多言語対応のチューニングを行うときや、トークン効率はQWenやLlama3に比べると少しさがるかもしれませんね。日本語と英語程度なら、6万もあれば十分、ということなのかもしれません。
まとめ
今回はファーストルックレポートとして、主に動画と記事にてご紹介させていただきました。
ベンチマークで好成績をおさめていますが、実際つかってみた体感としてはかなり性能が高いモデルと感じます。
引き続き要約、翻訳、コード生成、RAGシーンでの活用など実利用での可能性について検証していきたいとおもいます!
今年は Rakuten Mixtralや ELYZA-Llama3 など性能の高いLLMが毎月のようにリリースされていますが、業界最古参の CALMシリーズがまた新たなオープンLLMの歴史を刻んだ感じがしますね!
22Bという、エントリーレベルGPU1枚でも量子化すればギリギリ推論ができる、という点も非常にとっつきやすかったです。
このようなモデルをオープンソースでリリースしていただいたサイバーエージェント社に再度敬意🫡を表します。
今回も、最後までお読みいただき、誠にありがとうございます。
私たちQualitegは、LLMをはじめとするAI技術、開発キット・SDKの提供、LLMサービス構築、AI新規事業の企画方法に関する研修およびコンサルティングを提供しております。
今回ご紹介したChatStream🄬 SDK を使うと、最新のオープンソースLLMや、最新の商用LLMをつかったチャットボットをはじめとした本格的商用LLMサービスを超短納期で構築することが可能です。
もしご興味をお持ちいただけた場合、また具体的なご要望がございましたら、どうぞお気軽にこちらのお問い合わせフォームまでご連絡くださいませ。
LLMスポットコンサルご好評です
また、LLMサービス開発、市場環境、GPUテクノロジーなどビジネス面・技術面について1時間からカジュアルに利用できるスポットコンサルも実施しておりますのでご活用くださいませ。

(繁忙期、ご相談内容によっては、お受けできない場合がございますので、あらかじめご了承ください)



