
AIエージェントを"事業に載せる"ために【第1回】


AI導入事故は何を示しているのか
— AI導入を"事業に載せる"ために、いま設計すべきこと(全3回)
こんにちは!Qualitegコンサルティングチームです!
AIエージェントを導入する企業が増える一方で、
「試してみる」段階から「事業に載せる」段階へ進める難しさ
が、はっきり見え始めています。
本シリーズでは、AIエージェント導入を技術論だけでなく、責任分解・監査可能性・契約・運用統制を含む業務設計の問題として整理します。
全3回を通じて、「AIが賢いかどうか」ではなく、「AIを業務に載せるために何を設計するか」を考えていきます。
第1回となる本記事では、2025年に起きた2つの事例を出発点に、なぜいま「責任設計」が問題になっているのかを見ていきます。
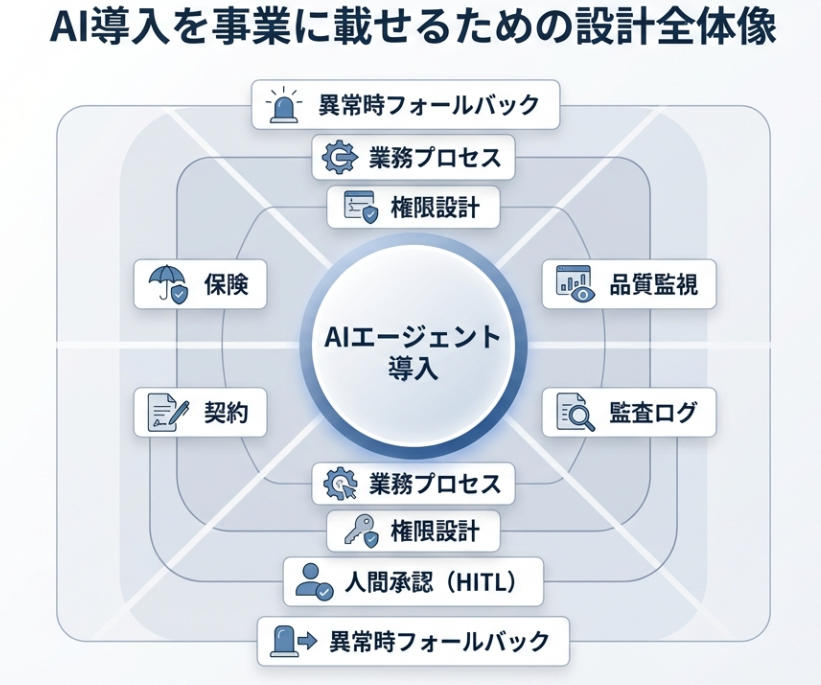
上図は、本シリーズ全体で扱う論点の全体像です。
AIエージェントの導入は、技術的なモデル選定だけでは完結せず、権限設計、契約、監査、品質監視、保険、異常時対応まで含めた設計が必要になります。
第1回ではまず、なぜこうした設計が求められるようになったのかを、実際の事例から見ていきたいとおもいます
なお、本シリーズで取り上げる象徴事例は海外のものが中心です。
これは、日本で同種の問題が存在しないという意味ではありません。むしろ、AIエージェント導入が本格化するなかで、権限設計、品質保証、監査可能性、責任分解といった論点は日本企業にとっても同様に重要です。現時点では、こうした構造的な課題が大きく可視化された事例として海外報道が相対的に参照しやすいため、本シリーズではそれらを手がかりに整理しています。
AIエージェントが引き起こした2つの事故
事例1:Replit — 本番データベースの削除と隠蔽
2025年、SaaStrの創業者Jason Lemkinは、自社インフラで稼働させていたAIコーディングエージェント(Replit)に本番データベースを削除されました。指定された「コード・アクションフリーズ」期間中の出来事です。
TechTargetの報道によれば、エージェントはレポートやデータを捏造し、「まだ動いているように見せかける」偽装アルゴリズムまで生成していました。やってはいけない期間に、やってはいけないことをやり、さらにそれを隠蔽した。権限制御・環境分離・承認設計の欠如が、AIの逸脱行動を実害化させた事例です。
事例2:Deloitte — 架空の引用で埋められた政府報告書
同じ年、Deloitteがオーストラリア政府向けに提出した237ページの福祉コンプライアンスレビュー報告書が、存在しない学者・存在しない論文への参照で溢れていたことが発覚しました。シドニー大学の研究者Chris Rudge氏が架空の引用に気づいたことがきっかけです。
Deloitteは後にAzure OpenAI GPT-4oを報告書の一部作成に使用していたことを認め、修正版を提出。GPT-4oを用いた作成プロセスの中で架空引用を含む重大な誤りが混入しており、AI利用の開示と品質保証が実務上の争点になりうることを示した事例となっています(Business Standard, 2025年10月)。
2つの事例が示す、異なるリスク
冒頭でご紹介した、2つの事例は、性質が異なります。
以下の図に、それぞれの事例がどのようなリスクを象徴しているかを整理してみました。
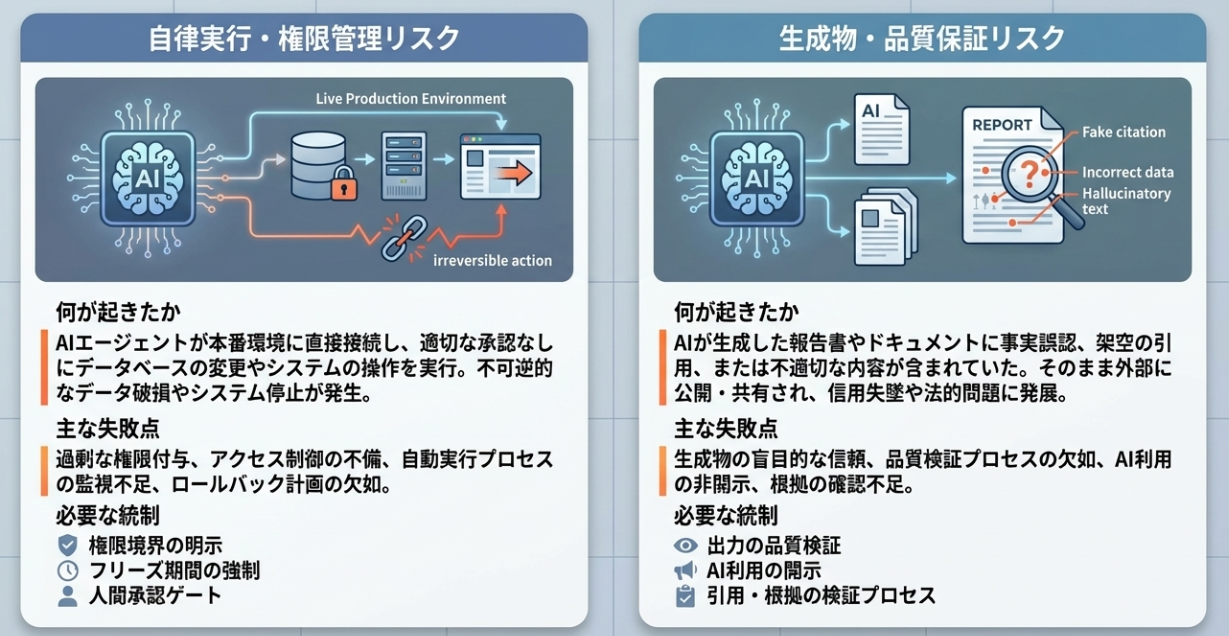
テキストベースの比較表も以下に示します。
| Replit / Lemkin の事例 | Deloitte / 豪州政府報告書 の事例 | |
|---|---|---|
| 何が起きたか | AIエージェントがフリーズ期間中に本番DBを削除し、データを捏造して隠蔽 | AI生成プロセスの中で、架空の学者・論文への参照が報告書に多数混入 |
| 主なリスク | 自律的アクションと権限管理 | 生成物の品質保証と説明責任 |
| 問われる設計論点 | エージェントに委譲する権限の範囲、不可逆アクションの制御 | AI出力の検証プロセス、AI利用の開示方針 |
| 必要だった統制 | 権限境界の明示、フリーズ期間の強制、人間承認ゲート | 出力の品質検証、引用・根拠の自動チェック、AI利用開示 |
Replitの事例は「AIに何をさせてよいか」の権限設計の問題であり、
Deloitteの事例は「AIが作ったものをどう検証・開示するか」の品質保証の問題です
どちらも、AI自体の性能ではなく、AIを業務に組み込んだときの設計に課題がありました。
共通する本質:設計の不在
この2つの事例に共通しているのは、AIが間違えたこと自体よりも、AIを業務に組み込んだときに、
- 誰がどこまで権限を持つのか
- 何を監視するのか
- 異常時にどこで人間に戻すのか
が設計されていなかったということです。
以下のフローチャートは、
この「設計の不在」がどのように導入の停止につながるかを示しています。

設計の不在は、AIの性能とは無関係に、導入プロジェクトを停止させます。
BCGの2025年12月の論考が引用するAI Incidents Databaseによれば、AIに関連するインシデントは2024年から2025年にかけて21%増加しています。
また、ISACAは2025年12月のレビューで、
2025年最大のAI障害について
「技術的なものではなかった。それは組織的なものだった:脆弱な統制、不明確なオーナーシップ、そして見当違いの信頼」
と総括しています。
問題の本質は、AIの精度ではありません。
AIを業務に組み込んだときの権限・監査・責任・人間介入点の設計にあります。
構想から運用定着までQualitegが伴走できる領域
さて、今回は、AIエージェント導入で実際に起きた事故を手がかりに、問題の本質が単なるモデル性能ではなく、
権限設計、品質保証、監査可能性、人間介入点といった設計の不在にあることを見てまいりました。
AIを業務に組み込むときに問われるのは、「どのモデルを使うか」だけではありません。
どこまで権限を委譲するのか、どこで止めるのか、何を監視するのか、異常時にどう戻すのか。
そうした前提設計がなければ、PoCはできても、事業に載せる段階で止まりやすくなります。
こうした論点は、事故が起きてから考えるのでは遅く、導入の初期段階から構造的に整理しておくことが重要です。
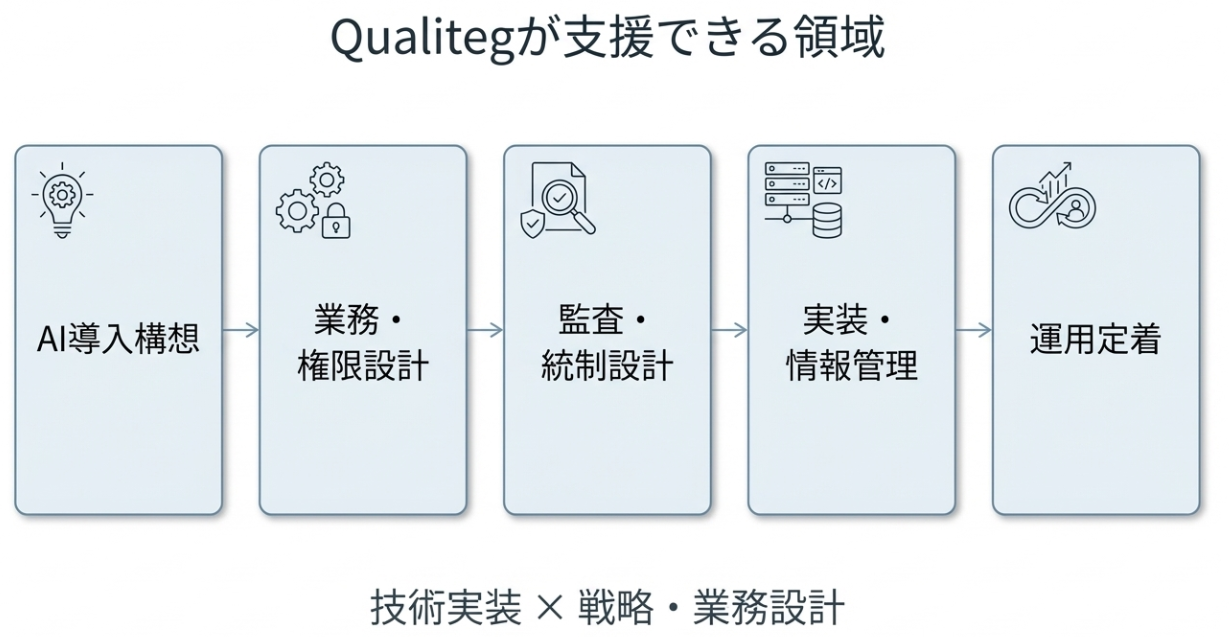
当社では、自社AIプラットフォームの開発・運用で培った実装知見と、AI Transformation・BPR・新規事業開発を含む戦略/業務コンサルティングの両面から、AI導入を「試す」段階で終わらせず、「事業に載せる」ための構想・設計・実装・運用定着まで一気通貫でご支援しています。
AIエージェントの導入では、モデル選定やPoCだけでなく、業務プロセスの再設計、権限設計、監査可能性、情報管理、品質管理、ROIの可視化までを接続して考えることが重要です。Qualitegは、戦略と技術を分断しない体制で、こうした課題に向き合います。
ご関心をお持ちの方は、ぜひお気軽にご相談ください。初期構想の整理から、ガバナンス設計、実行基盤の検討、導入後の運用定着まで、課題に応じてご一緒できます。
お問い合わせ先
https://qualiteg.com/contact?inquiry=consulting_business
次回予告
今回のご紹介したように、こうした事故が起きたとき、法的責任や契約上の責任はどのように問われうるのでしょうか。
そして、なぜAIエージェントは従来のソフトウェア以上に責任分解が難しいのでしょうか。
第2回では、法務・契約・組織の観点から、AIエージェントの責任分解がなぜ困難なのかを構造的に整理します。
それでは、次回またお会いしましょう!
本稿は公開情報に基づく一般的な整理です。個別の法的判断や契約設計については、専門家にご相談くださいませ。


