
【極めればこのテンソル操作 】NumPy配列の縦マージ方法:5つのアプローチ

こんにちは!
今日は、NumPyにおける配列の縦マージについてご説明いたします!
ご存じの通りNumPyは、Pythonで科学的計算を行うための強力なライブラリです。
複数のNumPy配列を縦にマージして大きな配列を作成する方法について、5つの異なるアプローチを詳しく見ていきましょう。
具体的には、(N,128)と(M,128)の形状を持つ複数のNumPy配列が格納されたPythonのリストから、(N+M,128)の形状を持つ単一のNumPy配列を作成する方法を説明します。
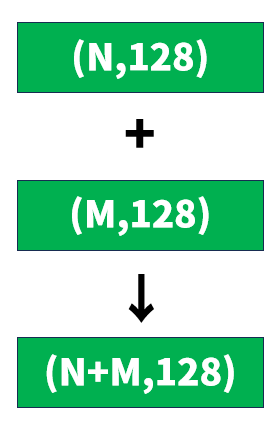
1. np.vstack() を使用する方法
np.vstack() 関数は、垂直方向(行方向)に配列をスタックするための関数です。
import numpy as np
list_of_arrays = [
np.random.rand(3, 128),
np.random.rand(2, 128)
]
merged_array = np.vstack(list_of_arrays)
print(merged_array.shape) # (5, 128)
特徴
- v(vertical縦に)にstack(積む)ということでメソッド名がとてもシンプルで直感的ですね。

使用場面
- 複数の2次元配列を縦に結合する一般的なケース
- メモリ効率と速度が重要な場合
2. np.concatenate() を使用する方法
np.concatenate() 関数も配列同士のマージでよく登場します。vstackよりももっと汎用性が高く指定した軸(axis)に沿って配列を結合します。
この関数の重要なパラメータの1つが axis です。
ただ、「軸ってなにさ?」と最初は戸惑うかもしれません、ので、少し軸についてもこまかくみていきましょう。
import numpy as np
list_of_arrays = [
np.random.rand(3, 128),
np.random.rand(2, 128)
]
merged_array = np.concatenate(list_of_arrays, axis=0)
print(merged_array.shape) # (5, 128)
axis=0 の詳細な説明
NumPyにおいて、axisは配列の次元を指定するパラメータです。
たとえば2次元配列の場合は
axis=0は最初の次元(行)に沿って操作を行います。axis=1は2番目の次元(列)に沿って操作を行います。
たとえばaxis=0 を指定すると、以下のような動作になります:
- 配列を「縦方向」に結合します。
- 最初の次元(行数)が増加します。
- 2番目の次元(列数)は変わりません。
視覚的に表すと次のようになります:
Array1 (3x128): [ ][ ][ ]
[ ][ ][ ]
[ ][ ][ ]
Array2 (2x128): [ ][ ][ ]
[ ][ ][ ]
Merged (5x128): [ ][ ][ ] (Array1)
[ ][ ][ ]
[ ][ ][ ]
[ ][ ][ ] (Array2)
[ ][ ][ ]
axis=1 との比較
対照的に、axis=1 を使用すると
- 配列を「横方向」に結合します。
- 最初の次元(行数)は変わりません。
- 2番目の次元(列数)が増加します。
# 注意:この例では、入力配列の形状を変更しています
array1 = np.random.rand(3, 64)
array2 = np.random.rand(3, 64)
merged_horizontal = np.concatenate([array1, array2], axis=1)
print(merged_horizontal.shape) # (3, 128)
視覚的には:
Array1 (3x64): [ ][ ][ ]
[ ][ ][ ]
[ ][ ][ ]
Array2 (3x64): [ ][ ][ ]
[ ][ ][ ]
[ ][ ][ ]
Merged (3x128): [ ][ ][ ][ ][ ][ ]
[ ][ ][ ][ ][ ][ ]
[ ][ ][ ][ ][ ][ ]
使用上の注意点
axis=0を使用する場合、結合する配列の列数(2番目の次元)が同じである必要があります。axisを指定しない場合、デフォルトでaxis=0が使用されます。- 3次元以上の配列の場合、
axisの値とその効果はより複雑になります。
特徴
- 柔軟性が高い(軸を指定可能)のが特徴ですね。axisの指定により3次元以上まで拡張できます。
使用場面
- 結合する軸を動的に変更したい場合
- 複数の次元で結合操作を行う必要がある場合
- データの構造や処理の要件に応じて柔軟に対応したい場合
(おまけ) 3. リスト内包表記と np.row_stack() を使用する方法
np.row_stack() は np.vstack() のエイリアスですが、リスト内包表記と組み合わせることで、より表現力の高いコードを書くことができます。
import numpy as np
list_of_arrays = [
np.random.rand(3, 128),
np.random.rand(2, 128)
]
merged_array = np.row_stack([arr for arr in list_of_arrays])
print(merged_array.shape) # (5, 128)
特徴
- Pythonic な書き方をめざしたい人向け。
使用場面
- 結合前に配列に対して操作を行いたい場合。
(おまけ) 4. np.r_ を使用する方法
np.r_ は、配列を行方向に結合するための簡潔な構文を提供します。
import numpy as np
list_of_arrays = [
np.random.rand(3, 128),
np.random.rand(2, 128)
]
merged_array = np.r_[tuple(list_of_arrays)]
print(merged_array.shape) # (5, 128)
特徴
- 非常に簡潔な構文ですが、可読性の点でわざわざこの書き方をしなくてもよいきもします。
使用場面
- どうしてもこの書き方がかっこいいとおもうとき。
(おまけ) 5. ループを使用して手動で結合する方法
この方法は、結合プロセスを完全に制御したい場合に有用です。
import numpy as np
list_of_arrays = [
np.random.rand(3, 128),
np.random.rand(2, 128)
]
total_rows = sum(arr.shape[0] for arr in list_of_arrays)
merged_array = np.zeros((total_rows, 128))
current_row = 0
for arr in list_of_arrays:
n_rows = arr.shape[0]
merged_array[current_row:current_row+n_rows] = arr
current_row += n_rows
print(merged_array.shape) # (5, 128)
まとめ
おまけも含めて5つご紹介いたしましたが、一般的には、np.vstack() や np.concatenate() が最も効率的かつ頻出かとおもいます。
それでは、また次回お会いしましょう!



