
LLM推論基盤プロビジョニング講座 第1回 基本概念と推論速度


こんにちは!
本日は LLMサービスの自社構築する際の推論基盤プロビジョニング、GPUプロビジョニングについて数回にわけて解説いたします。
はじめに
LLMの進化に伴い、ChatGPTやClaudeといったパブリックなLLMの活用は企業においても急速に広がってきました。しかし先進的な企業はこれらの汎用LLMに加えて、「領域特化型」「ドメイン特化型」といった専用LLMの構築へと歩みを進めています。こうした動きの背景には、企業固有の専門知識への対応力強化と情報セキュリティの確保という二つの重要なニーズがあります。
一般的なパブリックLLMでは対応できない企業固有の専門知識や機密情報の取り扱いが必要なケースが増えているため、自社LLMの構築や自社サーバーでの運用を検討する企業が急増しています。特に金融、医療、製造、法務といった専門性の高い領域では、業界特化型の独自LLMが競争優位性をもたらすと認識されています。
しかし、業界特化型のLLMを自社で運用することは簡単ではありません。自社運用を決断した場合、まず最初に取り組むべきは適切な推論環境の整備です。オンプレミス環境を構築するにしても、クラウドサービスを利用するにしても、どのようなハードウェアスペックが必要で、特にどのようなGPUがどれだけの数量必要になるのかを事前に見積もる必要があります。
これは単にGPUを購入すれば良いという話ではなく、サービスの想定負荷やモデルの特性に基づいた緻密な計算が必要です。必要なGPUの種類や数量を適切に見積もることで、過剰投資を避けつつ、必要な性能を確保するための調達費用を正確に見積もることができます。
こうした自社運用型LLMサービスを効果的に構築するためには、適切なGPUリソースと推論環境の「プロビジョニング」が不可欠です。特にコスト効率と性能のバランスを取りながら、ユーザー体験を損なわないLLM環境を構築することは容易ではありません。
本記事では、LLMサービスの本番稼働前に必要な「推論基盤プロビジョニング」の概念と、具体的な実施ステップについて解説します。
本記事は株式会社Qualiteg提供の 生成AI/LLM基礎研修2024-2025資料から一部抜粋して再編集しております。実測データは一部2024年当時のものとなりますのでご了承くださいLLM推論基盤プロビジョニング講座 シリーズ記事一覧
- 第1回 基本概念と推論速度
- 第2回 LLMサービスのリクエスト数を見積もる
- 第3回 使用モデルの推論時消費メモリ見積もり
- 第4回 推論エンジンの選定
- 第5回 GPUノード構成から負荷試験までの実践プロセス
- 番外編 KVキャッシュのオフロード戦略とGQA
推論基盤プロビジョニングとは
LLMサービス構築の鍵となる推論基盤プロビジョニングとは
自社でLLMサービスを本格的に構築・運用する企業が増える中、本番環境への移行前に適切なハードウェアリソースを確保することが課題となっています。特に高性能GPUの調達と最適な推論環境の構築は、サービスの品質とコスト効率を左右する重要な要素です。
LLMサービスの本番化の前に必要なGPUおよび推論用サーバーリソース(推論環境)を準備しておくことを「推論基盤プロビジョニング」と呼びます。これはGPUの確保だけでなく、サービス全体を支える推論インフラの設計と準備を含む包括的なプロセスです。

推論基盤プロビジョニングの概要
推論基盤プロビジョニングとは、LLMサービスの本番稼働の前に必要なGPUおよび推論用サーバーリソース(推論環境)を準備しておくことを指します。
この工程は大きく分けて以下の2つの要素から構成されています
1. GPUプロビジョニング
GPUプロビジョニングでは、提供予定のLLMサービスの想定負荷やLLMモデルの素性に応じて、LLMサービスの要件を満たすGPUの種類や数を決定します。
具体的には
- サービスの同時利用者数予測
- 応答時間の要件
- 処理すべきトークン数
- 選定したLLMモデルの要求スペック
- コスト効率
などを総合的に判断し、最適なGPUの種類(NVIDIA A100, H100など)と必要台数を算出します。
2. 推論環境プロビジョニング
推論環境プロビジョニングでは、GPUが搭載されるサーバー・ワークステーションやクラウド環境を決め、サービス提供に必要となるソフトウェアを適切な環境に配置し、必要な設定を行う作業が含まれます。
ここでの主な作業は
- 推論サーバーのハードウェア選定または仮想環境の構築
- コンテナ環境(Docker, Kubernetes)の構築
- モデルサーブィングフレームワーク(vLLM, TensorRT-LLM)の導入
- 負荷分散の設定
- モニタリングシステムの導入
- セキュリティ対策
Qualitegが実践する7ステップGPUプロビジョニングプロセス
さて、前節で説明した推論基盤プロビジョニングの重要性を踏まえ、ここではQualitegが実際に行っている具体的なGPUプロビジョニングプロセスを紹介します。Qualitegでは、実現したいLLMサービスに必要なGPUの種類と必要ボリュームを以下の7つのステップで決定します。
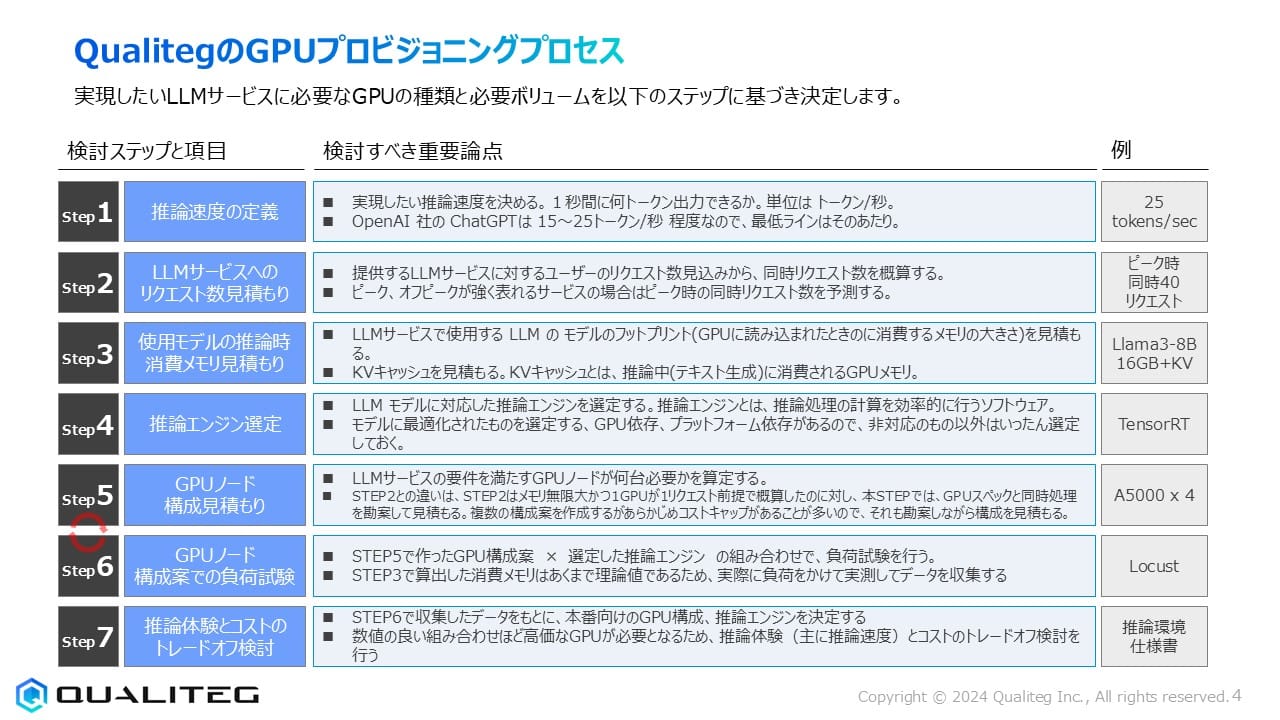
Step 1: 推論速度の定義
まず最初に、実現したい推論速度を明確に定義します。推論速度は「1秒間に何トークン出力できるか」という単位(トークン/秒)で測定します。業界の参考値として、OpenAIのChatGPTは約15〜25トークン/秒の速度であり、最低ラインとしてはこの程度の速度が一般的に求められます。例えば、25トークン/秒などの具体的な目標を設定します。
Step 2: LLMサービスへのリクエスト数見積もり
次に、提供するLLMサービスに対するユーザーのリクエスト数の見込みから、同時リクエスト数を概算します。特にピーク時とオフピーク時で強く表れるサービスの場合は、ピーク時の同時リクエスト数を予測することが重要です。例えば、ピーク時には同時40リクエストが発生すると予測する場合があります。
Step 3: 使用モデルの推論時消費メモリ見積もり
LLMサービスで使用するモデルのフットプリント(GPUに読み込まれたときに消費するメモリの大きさ)を見積もります。また、KVキャッシュ(推論中のテキスト生成に消費されるGPUメモリ)の容量も考慮に入れる必要があります。例えば、Llama3-8Bモデルの場合、16GB+KVキャッシュ分のメモリが必要になります。
Step 4: 推論エンジン選定
LLMモデルに対応した推論エンジンを選定します。推論エンジンとは、推論処理の計算を効率的に行うソフトウェアです。モデルに最適化されたエンジンを選ぶことが重要で、GPU依存、プラットフォーム依存があるため、非対応のものは選定しないようにします。例えば、TensorRTなどが代表的な推論エンジンとして挙げられます。
Step 5: GPUノード構成見積もり
LLMサービスの要件を満たすGPUノードが何台必要かを算定します。Step 2の同時リクエスト数とStep 3のメモリ見積もりからGPUリクエスト計算時間で概算したものに対し、このステップではGPUスペックと同時処理を勘案して見積もります。複数の構成案を作成するのが一般的ですが、最初からコストキャップがあることが多いため、それも勘案しながら構成を見積もります。例として、A5000 × 4などの構成が考えられます。
Step 6: GPUノード構成案での負荷試験
Step 5で作ったGPU構成案と選定した推論エンジンの組み合わせで、実際に負荷試験を行います。Step 3で算出した消費メモリはあくまで理論値であるため、実際に負荷をかけて実測してデータを収集することが重要です。この負荷試験にはLocustなどのツールが使用されることがあります。
Step 7: 推論体験とコストのトレードオフ検討
最後に、Step 6で収集したデータをもとに、本番向けのGPU構成、推論エンジンを決定します。数値の良い組み合わせほど高価なGPUが必要になる傾向があるため、推論体験(主に推論速度)とコストのトレードオフを検討します。この検討結果は最終的に推論環境仕様書としてまとめられます。
それでは、重要なステップの内容をみていきましょう。
STEP1: 推論速度の定義 - LLMサービス構築の基本
同期型と非同期型のLLMサービス
LLMサービスを提供する形態には「同期型」と「非同期型」の2つのパターンがあります。

同期型LLMサービスとは
チャットボットのような「リアルタイム性」や「即時性」が求められるサービスが同期型LLMサービスに分類されます。ユーザーが質問や指示を入力すると、即座に応答が返ってくることが期待されます。この場合、推論速度が速いほど応答を受け取るユーザー体験は向上するため、同期型LLMサービスを提供する際には、最初に「目指すべき推論速度」を明確に定義することが重要です。
同期型LLMサービスは同時に大量のリクエストが来ることを想定する必要があり、リクエストを捌くために複数のGPUや推論環境が必要になるため、実現難易度とコストは非同期型に比べて高くなります。
非同期型LLMサービスとは
即時性が求められない用途では、例えば
- 大量の文章を要約する
- 大量の文章を翻訳する
といった処理をLLMに一括して実行させ、終わり次第結果を通知させるようなユースケースがあります。このようなパターンを非同期型サービスと呼びます。
「数時間、数日かけて終われば良い」というレベル感の非同期型LLMサービスの場合、1台のGPUでも効率的に処理できる場合があり、実現難易度は低く、コストも抑えられる利点があります。
ストリーミングレスポンスによる体験向上
ユーザーが入力してからLLMが応答を返し、ユーザーの画面に表示されるまでの時間を「レイテンシ」と呼びます。
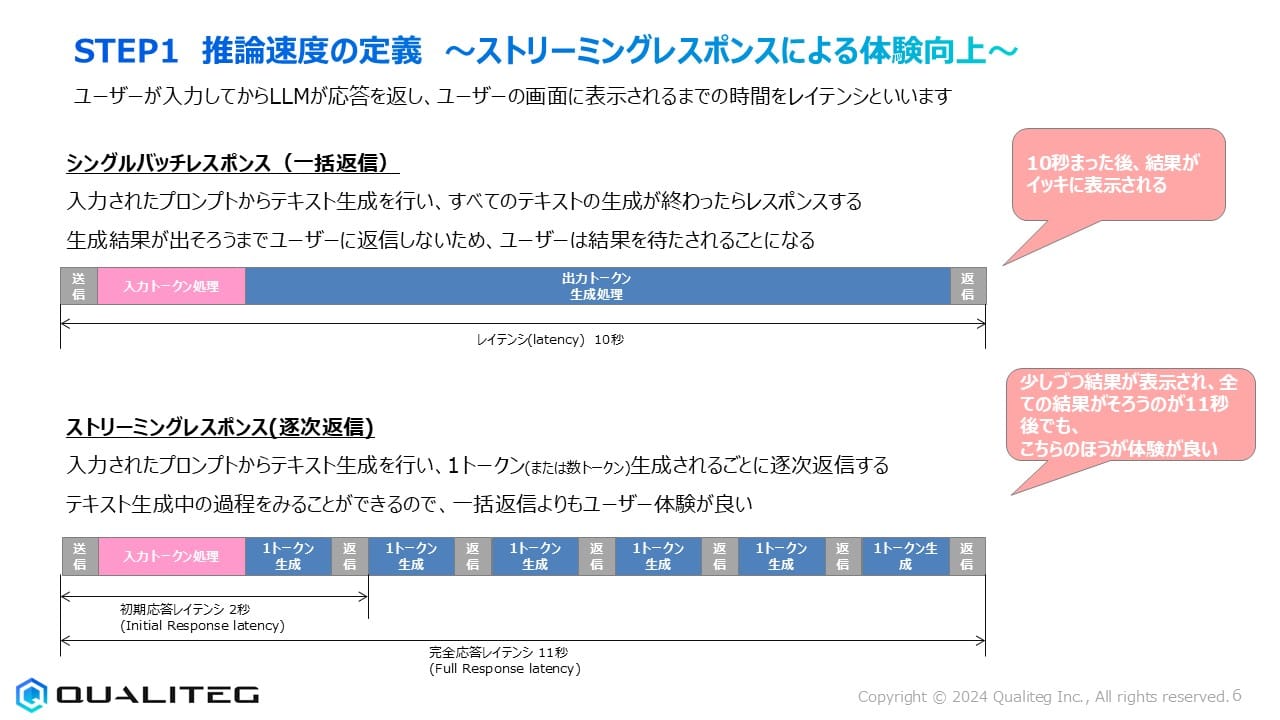
レスポンス方式には以下の2種類があります
シングルバッチレスポンス(一括返信)
入力されたプロンプトからテキスト生成を行い、すべてのテキストの生成が終わってからレスポンスする方式です。生成結果が出そろうまでユーザーに返信しないため、ユーザーは結果を待たされることになります。この場合、総レイテンシが約10秒かかると、結果がすべて一度に表示されます。
ストリーミングレスポンス(逐次返信)
入力されたプロンプトからテキスト生成を行い、1トークン(または数トークン)生成されるごとに逐次返信する方式です。テキスト生成の過程を見ることができるので、一括返信よりもユーザー体験が向上します。
初期応答レイテンシが約2秒で最初の結果が表示され始め、完全応答レイテンシが約11秒でも、ユーザーは少しずつ結果が表示されるのを見ることができるため、体感的な待ち時間が短く感じられます。

推論速度の単位と目標設定
同期型LLMサービスの場合、まず推論速度を設定することが重要です。
推論速度の単位
推論速度は「1秒間に何トークン生成できるか」を示す「トークン/秒」(英語表記ではT/sやtokens/sec)で表されます。これはLLMサービスの性能を表す際に最もよく使われるメトリクスです。
最低限目指したい推論速度
リクエストピーク時に15〜25トークン/秒の推論速度を実現できることが最低ラインとされています。ここで設定した推論速度をピーク時に実現できるよう、後続のステップでGPU構成を見積もっていきます。

主要LLMサービスの推論速度比較
各社のLLMチャットサービスの推論速度を比較すると
- ChatGPT(GPT4): 15〜25トークン/秒
- ChatGPT(GPT4o): 25〜50トークン/秒
- Claude3 Haiku: 120トークン/秒
- Groq(Llama70B): 300トークン/秒
目指すべき推論速度の目安
現実的な目標としては、ChatGPTのスピードがエンドユーザーの体験基準と考えると、GPT-4oと同程度の40〜70トークン/秒が実現したい推論速度の目安となります。
LLMの推論速度は以下のように分類できます
- 低速(〜30トークン/秒): GPT-4(15〜25)、DeepSeek-V2-Chat(25)
- 中速(30〜100トークン/秒): GPT-4o(40〜70)
- 高速(100〜300トークン/秒): Claude3 Haiku(120)、Fireworks Llama3 70B(200)
- 超高速(300トークン/秒〜): Groq Llama3 70B(302)、Groq Llama3 8B(900)
自社LLMサービスの判定ラインとしては、15トークン/秒(C判定)、30トークン/秒(B判定)、70トークン/秒(A判定)といった基準が考えられます。
これらの推論速度の定義が、以降のGPUプロビジョニングプロセスの基盤となり、必要なGPUリソースの算出に直接影響します。
今回のまとめ:効果的なGPUプロビジョニングへの道
今回は、LLMサービス構築における推論基盤プロビジョニングの基本概念と、Qualitegが実践している7ステップGPUプロビジョニングプロセスの中でも特に重要なSTEP1「推論速度の定義」について詳しく解説しました。
同期型と非同期型のLLMサービスの違いを理解し、ユースケースに応じた適切な推論速度目標を設定することがプロビジョニングの第一歩です。ChatGPTやClaude3などの主要LLMサービスの推論速度を参考にしながら、ユーザー体験を左右する重要な指標として15〜70トークン/秒の範囲で目標を定めることが推奨されます。
次回は、STEP2「LLMサービスへのリクエスト数見積もり」、STEP3「使用モデルの推論時消費メモリ見積もり」について詳しく解説します。DAUからの総GPU時間と同時リクエスト数の算出方法、KVキャッシュの計算方法、そして実際の負荷試験の実施手順と測定項目について学びましょう。
GPUプロビジョニングプロセスは単なる技術的な計算ではなく、ビジネス要件とユーザー体験を満たすための戦略的なアプローチです。適切なGPUリソースを確保することで、コスト効率の良い安定したLLMサービスの提供が可能になります。
それでは次回またお会いしましょう!
LLM/AIセキュリティのことなら株式会社Qualiteg
私たちQualitegは、LLMの推論・サービング基盤を実際に設計してきたエンジニアリングチームを有しており推論エンジンを単なる箱として扱わず、アテンション計算やKVキャッシュの挙動など深い知見をベースにしたローカルLLM技術のご支援を提供しています。「VRAMに収まる構成はどこか」「vLLMとHugging Face、判断軸は何か」「既存モデルを自社ドメインへ適応させる最短経路は」「オープンLLMと商用LLMの使い分け」「セキュアなローカルLLM構成はどうすればいいか」「ローカルLLMとGPUの選び方」「GPUデータセンターの需要と市場予測」「AI市場予測」などコア技術からAI市場分析まで、お気軽にご相談くださいませ。



