
発話音声からリアルなリップシンクを生成する技術 第3回:wav2vec特徴量から口形パラメータへの学習

こんにちは!
前回までの記事では、
について解説してきました。今回はいよいよ、これらの技術を統合して実際に音声から口の動きを生成する核心部分に踏み込みます。
本記事で扱うのは、wav2vecが抽出した768次元の音響特徴量を、26個の口形制御パラメータの時系列データに変換する学習プロセスです。これは単なる次元削減ではありません。音の物理的特性を表す高次元ベクトルから、人間の口の動きという全く異なるモダリティへの変換なのです。この変換を実現するには、音韻と視覚的な口形の間にある複雑な対応関係を、ニューラルネットワークに学習させる必要があります。
特に重要なのは、この対応関係が静的ではなく動的であるという点です。同じ音素でも前後の文脈によって口の形が変わり、さらに音が聞こえる前から口が動き始めるという時間的なズレも存在します。これらの複雑な現象をどのようにモデル化し、学習させるのか。本記事では、LSTMとTransformerという2つの強力なアプローチを比較しながら、実践的な観点から最適な手法を探っていきます。
1. 問題の本質:なぜ口形予測は難しいのか
1.1 同じ音素でも文脈で変わる口形
リップシンクの難しさを理解するために、まず「ん」という音素を例に考えてみましょう。日本語話者なら誰でも発音できるこの音ですが、実は状況によって口の形が大きく異なります。
「さんぽ」と発音するとき、「ん」の段階で既に唇が閉じ始めます。これは次に来る「ぽ」が両唇破裂音であり、唇を完全に閉じる必要があるからです。一方、「さんか」の「ん」では、唇は閉じません。次の「か」は軟口蓋破裂音で、口の奥で調音されるため、唇を閉じる必要がないのです。
この現象は調音結合(coarticulation)と呼ばれ、人間の自然な発話において普遍的に観察されます。我々の脳は無意識のうちに次の音を予測し、効率的な口の動きを計画しているのです。
この予測的な動きこそが、自然なリップシンクを実現する鍵となります。
1.2 音声に先行する口の動き
さらに興味深いのは、口の動きが実際の音声に先行するという現象です。高速度カメラで人間の発話を撮影すると、音が聞こえる50〜100ミリ秒前から口が動き始めることが観察されます。
特に顕著なのが破裂音です。「ぱ」という音を発するとき、まず唇を閉じて口腔内の圧力を高め、その後唇を開放することで破裂音が生まれます。つまり、音が聞こえる瞬間には既に唇は開き始めているのです。この時間的なオフセットを正確にモデル化しないと、音と口の動きがずれて見える不自然なリップシンクになってしまいます。
1.3 調音結合という複雑な現象
調音結合は単に隣接する音素間の影響だけでなく、より広範囲にわたる現象です。例えば「ありがとうございます」という発話を考えてみましょう。
今回からの記事では、少し複雑な仕組みの解説が増えるので、「クオ先生」と「マナブ君」にご登場いただき、二人の会話を通して理解を深めていきましょう!
このような複雑な現象を扱うため、我々は高度な機械学習モデルを必要とします。次章では、この課題に対する最初のアプローチとして、LSTMによる時系列モデリングについて詳しく見ていきましょう。
2. LSTMによる時系列モデリング
2.1 なぜ単純なニューラルネットワークではダメなのか
最初に思いつくアプローチは、各時点のwav2vec特徴量を入力として、対応する口形パラメータを出力する単純な全結合ニューラルネットワークかもしれません。しかし、このアプローチには致命的な欠陥があります。
単純なニューラルネットワークは各時点を独立に処理するため、時系列の文脈を全く考慮できません。前述の「さんぽ」の例で言えば、「ん」の時点で「次は『ぽ』が来る」という情報を使えないのです。結果として、すべての「ん」に対して同じ口形を出力してしまい、極めて不自然なリップシンクになってしまいます。
2.2 RNNの基本的な考え方と限界
この問題を解決するために登場したのがRNN(Recurrent Neural Network)です。RNNは「記憶」を持つニューラルネットワークで、過去の情報を保持しながら時系列データを処理できます。
RNNの基本的なアイデアは、現在の出力を計算する際に、現在の入力だけでなく前の時点の内部状態も使用するというものです。これにより、過去の文脈を考慮した予測が可能になります。
しかし、RNNには「勾配消失問題」という深刻な課題があります。時系列が長くなるにつれて、過去の情報の影響が指数関数的に減衰してしまうのです。
2.3 LSTMが解決する「記憶」の問題
LSTM(Long Short-Term Memory)は、この勾配消失問題を解決するために設計された特殊なRNNです。LSTMの革新的な点は、情報の流れを制御する「ゲート機構」を導入したことです。
これらのゲート機構により、LSTMは必要な情報を長期間保持し、不要な情報を適切に忘却できます。リップシンクの文脈で言えば、「この発話は疑問文である」という情報を文末まで保持しつつ、個々の音素の詳細は適切なタイミングで忘れるということが可能になります。
2.4 双方向LSTMの必要性:過去と未来の両方を見る
標準的なLSTMは過去から現在への情報の流れしか扱えません。しかし、リップシンクにおいては未来の情報も重要です。「さんぽ」の「ん」で唇を閉じ始めるのは、未来に「ぽ」が来ることを知っているからです。
双方向LSTM(Bidirectional LSTM)は、この問題を解決します。時系列を順方向(過去→未来)と逆方向(未来→過去)の両方から処理し、各時点で両方向の情報を統合します。
双方向LSTMにより、各時点で過去と未来の両方の文脈を考慮した口形予測が可能になります。これが、自然なリップシンクを実現する上で重要な要素となるのです。
3. LSTMベースのネットワーク設計
3.1 全体アーキテクチャ図(wav2vec→口形パラメータ)
ここで、実際のネットワーク構成を視覚的に理解するため、上記のアーキテクチャ図を見てみましょう。この図は、音声波形から口形パラメータまでの変換プロセス全体を示しています。大きく分けて、入力処理、メインネットワーク、出力生成の3つのステージから構成されています。
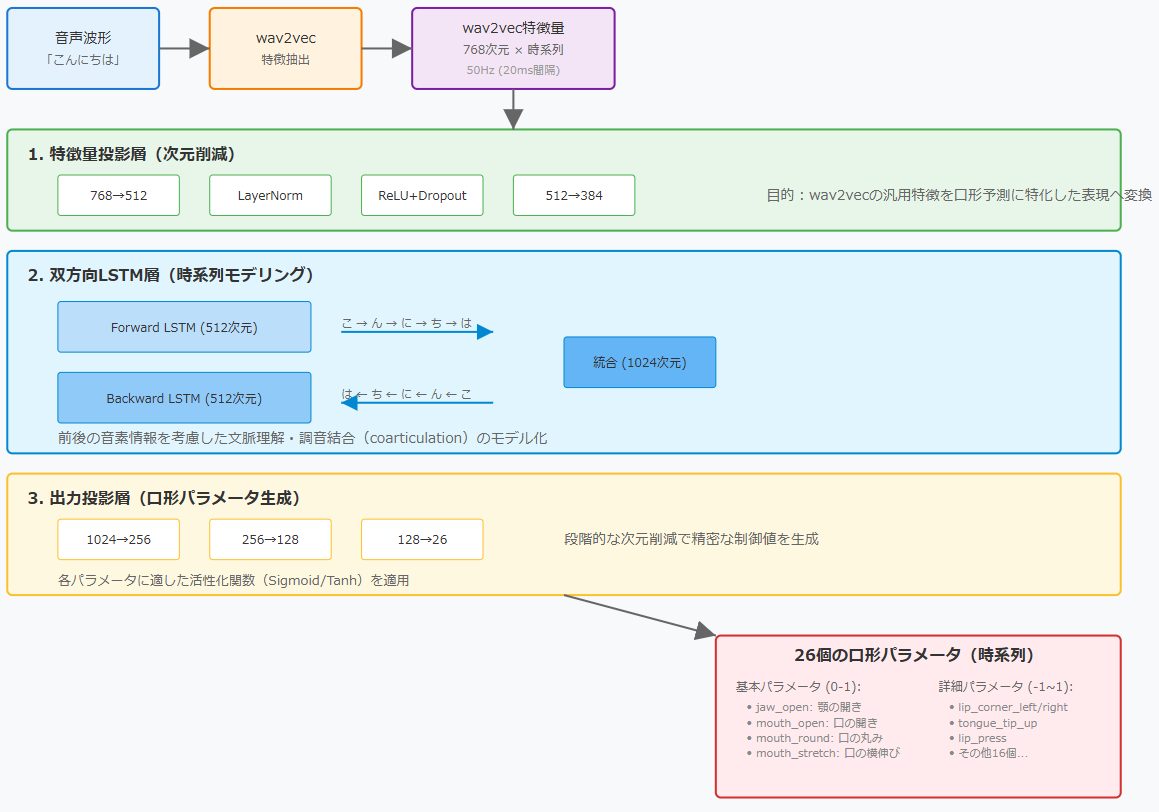
3.2 各層の役割
特徴量投影層:768→384次元への次元削減
wav2vecから出力される768次元の特徴量は、音声に関するあらゆる情報を含んでいます。話者の特徴、感情、環境音、そして我々が必要とする音韻情報などが混在しています。しかし、リップシンクに必要なのは主に音韻情報と、それに関連する韻律情報です。
この層の役割は、768次元という高次元空間から、口形予測に必要な情報だけを抽出し、384次元という扱いやすい次元に圧縮することです。単純な線形変換だけでなく、LayerNormalizationによる正規化、ReLU活性化関数による非線形変換、そしてDropoutによる過学習防止を組み合わせることで、ロバストな特徴抽出を実現しています。
双方向LSTM層:時系列パターンの学習
この層がネットワークの心臓部です。Forward LSTMとBackward LSTMがそれぞれ512次元の隠れ状態を持ち、合わせて1024次元の文脈情報を生成します。
Forward LSTMは「こ→ん→に→ち→は」の順に処理し、各時点で「これまでに何を言ってきたか」という情報を蓄積します。一方、Backward LSTMは逆順に処理し、「これから何を言うか」という情報を提供します。これらを統合することで、各時点で過去と未来の両方の文脈を考慮した表現が得られます。
3層のLSTMを重ねることで、より複雑な時系列パターンを学習できます。第1層は基本的な音素遷移を、第2層は調音結合のパターンを、第3層はより長距離の依存関係を捉えると考えることができます。
出力投影層:384→26次元への変換
最後の出力層は、LSTMが生成した1024次元の文脈表現を、26個の口形パラメータに変換します。ここでも段階的な変換(1024→256→128→26)を行うことで、急激な情報圧縮を避けています。
特に重要なのは、各パラメータの特性に応じた活性化関数の使い分けです。jaw_openやmouth_openなど、0から1の範囲を取るパラメータにはSigmoid関数を、lip_corner_leftのような-1から1の範囲を取るパラメータにはTanh関数を適用します。
3.3 なぜこの構成が効果的なのか
このネットワーク構成が効果的な理由は、人間の発話メカニズムを模倣しているからです。
まず、特徴量投影層は人間の聴覚系に相当します。耳に入ってきた音から、発話に関する情報だけを抽出する過程です。次に、双方向LSTM層は脳の言語処理領域に相当します。過去の文脈と未来の計画を統合して、適切な運動指令を生成します。最後に、出力投影層は運動制御系に相当し、抽象的な指令を具体的な筋肉の動きに変換します。
このように設計されたLSTMネットワークは、限られたデータでも効率的に学習でき、自然なリップシンクを生成できます。
まとめ
本記事では、wav2vec特徴量から口形パラメータへの変換という、リップシンク技術の核心部分について解説を始めました。
なぜこの問題が難しいのか、その本質に迫りました。同じ「ん」という音でも「さんぽ」と「さんか」では口の形が異なる調音結合の例を通じて、文脈の重要性を理解しました。また、音声より50〜100ミリ秒先行して口が動き始める現象も、リップシンクの複雑さを物語っています。
この時系列問題への最初のアプローチとして、LSTMを詳しく解説しました。RNNの勾配消失問題を、LSTMのゲート機構(忘却・入力・出力ゲート)がどう解決するか、クオ先生とマナブ君の対話を通じて学びました。特に双方向LSTMにより、過去と未来の両方の文脈を考慮できることが重要です。
そしてさいごにLSTMベースのネットワークの一例をご紹介しました。768次元のwav2vec特徴量を384次元に圧縮する投影層、時系列パターンを学習する双方向LSTM層、26個の口形パラメータを生成する出力層という構成までご説明いたしました。
さて、次回は、より実務的な内容である「データ準備と学習プロセス」、そしてLSTMの限界とTransformerという新しいアプローチについてもみてきたいとおもいます。
それではまた次回お会いしましょう



