
発話音声からリアルなリップシンクを生成する技術 第5回(前編):Transformerの実装と実践的な技術選択


こんにちは!リップシンク技術シリーズもいよいよ終盤となりました。
前回(第4回)では、LSTMの学習プロセスと限界について詳しく解説しました。限られたデータでも効果的に学習できるLSTMの強みを理解する一方で、長距離依存の処理に限界があることも明らかになりました。そして、この問題を解決する革新的なアプローチとして、すべての位置の情報を同時に参照できるTransformerのSelf-Attention機構を紹介しました。
第5回の今回は、
Transformerの具体的なネットワーク設計から始め、その実装上の課題を明らかにします。(前編※)
そして、LSTMとTransformerの長所を組み合わせたハイブリッドアプローチを紹介し、実際の製品開発における技術選択の指針を示します。最後に、感情表現への拡張という次なる挑戦についても触れていきます。(後編※)
※Transformerの仕組みは複雑であるため、第5回は前編と後編に分けて解説させていただく予定です。
1. Transformerベースのネットワーク設計
1.1 全体アーキテクチャ図
では、さっそく、Transformerベースのリップシンク変換ネットワークの構成を見てみましょう。

LSTMベースのネットワークと比較すると、入力(wav2vec特徴量)と出力26個の口形パラメータ※は同じですが、その間の処理方法が根本的に異なることが分かります。
最も大きな違いは、LSTMが時系列を順次処理するのに対し、Transformerはすべての時点を並列※に処理する点です。これにより、文頭と文末のような離れた位置の関係も直接学習できるようになります。
1.2 各層の役割
位置エンコーディング:順序情報の埋め込み
Transformerの最初の特徴的な要素は、位置エンコーディングです。Self-Attentionは位置に関係なくすべての要素を同じように扱うため、そのままでは「こんにちは」と「はちにんこ」の区別ができません。そこで、各位置に固有の位置情報を追加する必要があります。
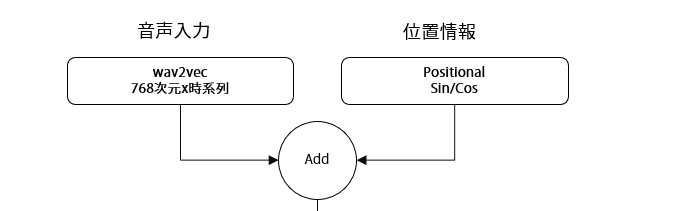
位置エンコーディングには、正弦波と余弦波を使った周期的な関数を使用します。位置pと次元iに対して、
PE(p,2i) = sin(p / 10000^(2i / d_model))
PE(p,2i+1) = cos(p / 10000^(2i / d_model))という式で計算されます。この方法により、各位置に一意の表現を与えながら、位置間の相対的な関係も保持できます。
位置エンコーディングの数式について
PE(p,2i) = sin(p / 10000^(2i / d_model))
PE(p,2i+1) = cos(p / 10000^(2i / d_model))
この数式だけ見ると難しく感じますが、ポイントは「波のパターンで位置を区別する」という点です。
- 正弦波と余弦波を組み合わせる理由
周期の異なる波を重ねることで、短い距離の違いも、長い距離の違いも表現できます。
たとえば、2番目と3番目の位置は高周波の波で区別しやすく、10番目と100番目の違いは低周波の波で効いてきます。 - なぜ 10000 を使うのか
波のスケールを指数関数的に変えていくための基準値です。
周波数が対数スケールで広がるので、「どんな長さの系列でも」位置を一意に表せる仕組みになっています。 - 相対関係も保持できる
sin/cos の周期的な性質により、「p と q の差」が角度の差として埋め込まれるので、モデルは「この2つは3ステップ離れている」といった情報を自然に学習できます。
Multi-Head Self-Attention層:全体を見渡す仕組み
さてさて、なんといってもコアはここでしょう。
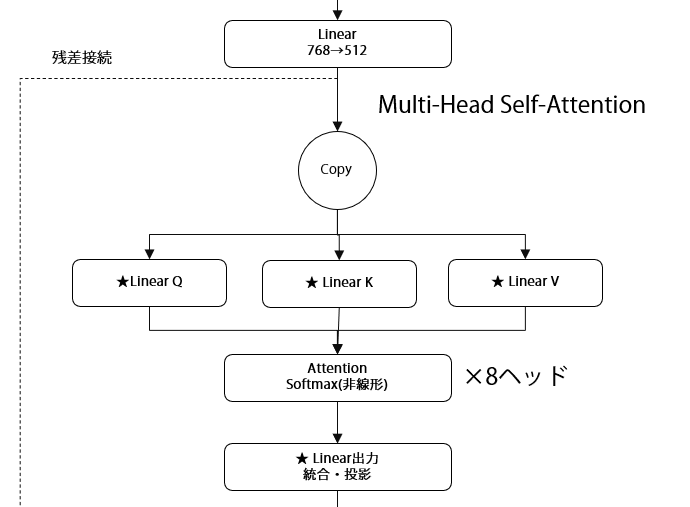
Transformerの心臓部ともいえるMulti-Head Self-Attention層は、8つの独立したAttentionヘッドから構成されます。各ヘッドは異なる観点から音素間の関係を学習します。
例えば、あるヘッドは隣接する音素の関係に注目し、別のヘッドは同じ調音点を持つ音素(「た」と「だ」など)の関係に注目するかもしれません。さらに別のヘッドは、文の始まりと終わりの関係に注目して、文全体のトーンを把握する役割を担うかもしれません。
8つのヘッド※の出力は最終的に統合され、多面的な音素間関係の理解を可能にします。これは、8人の専門家がそれぞれの視点から分析し、その結果を総合して判断を下すようなものです。
といっても、なかなかイメージしにくいとおもいますので、もう少しふかく見ていきましょう
そもそも Multi-Head Attentionの仕組みって?
上図で説明したとおり、リップシンク学習用のTransformerは8つの独立したAttentionヘッド※を持っており、それぞれが異なる観点で音素間の関係を見ています。
つまり、8つの「異なる観点」で音と口の形の関係を学習するということになります。
では、8つの観点とはどういうものなのか、以下の例で具体的にみていきましょう。
- ヘッド1:隣接関係「こ」→「ん」のような隣り合う音素の繋がりを重視滑らかな口の動きの遷移を学習
- ヘッド2:同じ調音点「た」と「だ」(舌の位置が同じ)「ま」と「ば」(唇を使う)似た口形を持つ音素間の関係を学習
- ヘッド3:母音の関係「あ」「い」「う」「え」「お」の母音部分に注目口の開き具合のパターンを学習
- ヘッド4:文の始まりと終わり文頭と文末の関係(イントネーション)全体的な発話の調子を把握
- ヘッド5:アクセント位置強調される音素を検出口の動きが大きくなる部分を特定
- ヘッド6:無音・休止句読点や息継ぎの位置口を閉じるタイミングを学習
- ヘッド7:子音クラスター「str」「spl」のような子音の連続複雑な口の動きの組み合わせ
- ヘッド8:長距離の韻律疑問文の上昇調文全体のリズムパターン
(※本稿の8つの観点は一例です。実際の学習では多種多様な観点をTry&Errorします)
なんで8つも観点が必要なのでしょうか。
それは上でも書いた通り、
「8人の専門家がそれぞれの視点から分析し、その結果を総合して判断を下すようなもの」
をすると、より高度なリップシンクが実現でき(そう)るからです。
つまり、
- 1人の専門家(1ヘッド)だと、1つの観点しか見られない
- 8人の専門家(8ヘッド)なら、同時に複数の観点から分析できる
- 最終的に8つの分析結果を統合して、より正確な口形を生成できる
ということになり、これにより、単純な音素の並びだけでなく、文脈、イントネーション、リズムなど、複雑な要素を同時に考慮した自然なリップシンクが可能になります。

第1の専門家「隣接関係の鑑定士」
「こ」から「ん」への移り変わりのような、お隣同士の音のつながりを見ています。まるで、手をつないで歩く子供たちの関係を観察する保育士さんのようです。
第2の専門家「音の双子探し名人」
「た」と「だ」のように、舌の位置が同じ音を見つけるのが得意です。双子を見分ける産院の看護師さんみたいな存在ですね。
第3の専門家「母音の調律師」
「あいうえお」の母音に注目します。ピアノの調律師が音程を整えるように、口の開き具合を調整するんです。
第4の専門家「物語の編集者」
文の始まりと終わりの関係を見ています。小説の冒頭と結末を考える編集者のような役割です。
第5の専門家「強弱の指揮者」
アクセントの位置を検出します。オーケストラの指揮者が強弱を付けるように、どこで口を大きく開くかを決めています。
第6の専門家「間の取り方の達人」
句読点や息継ぎを見つけます。落語家さんの「間」のような、沈黙の美学を理解している専門家です。
第7の専門家「早口言葉の解析者」
「str」や「spl」のような子音の連続を扱います。アナウンサーの滑舌訓練を指導する先生のような存在です。
第8の専門家「イントネーションの音楽家」
疑問文の上がり調子など、文全体のメロディーを感じ取ります。作曲家が旋律を作るような感覚で、音の流れを把握します。
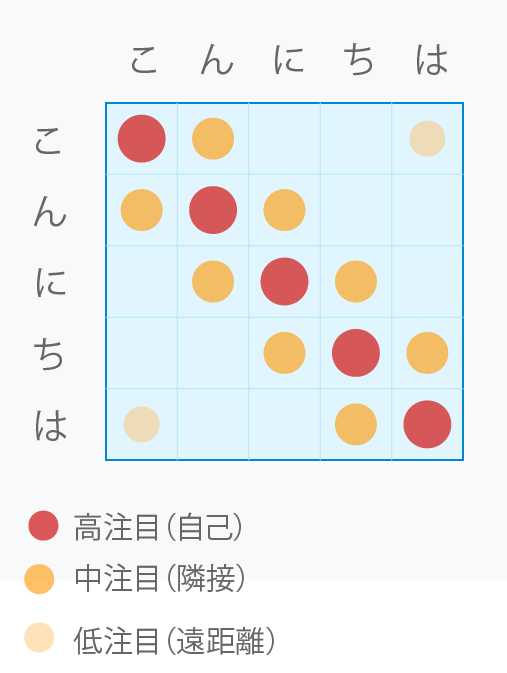
Attentionマトリックスとは
Attentionマトリックスは、「各要素が他のすべての要素をどれだけ注目(参照)するか」を数値化した表です。各行(Queryごと)はSoftmaxで正規化され、和が1の確率分布になります(一般に対称ではありません)。
リップシンクの文脈では、「各音素が他の音素をどれだけ参考にして口形を決めるか」を表します。
例えば「こんにちは」の5音素※なら、5×5=25個の組み合わせすべてについて、関連性の強さを数値で表現したものです。
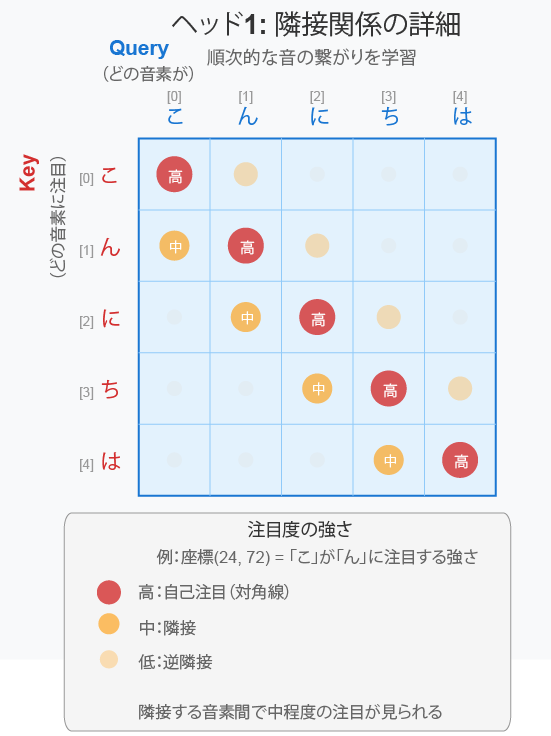
※実際の学習入力は”音素”ではなく wav2vec などの連続特徴フレームとなります)例えば以下のマトリクスは、
- 5×5のグリッド:「こ」「ん」「に」「ち」「は」の各音素間の関係を表現
- 赤い丸(濃い):対角線上の自己注目(各音素が自分自身に注目)
- オレンジの丸(中程度):隣接する音素間の注目
- 薄いオレンジの丸:文頭と文末など、離れた位置の音素間の注目
をあらわしています。
実際のTransformer学習における登場人物 Q,K,Vについて
さて、この部分に着目しましょう。
ここにある、Q,K,Vとはなんでしょうか?
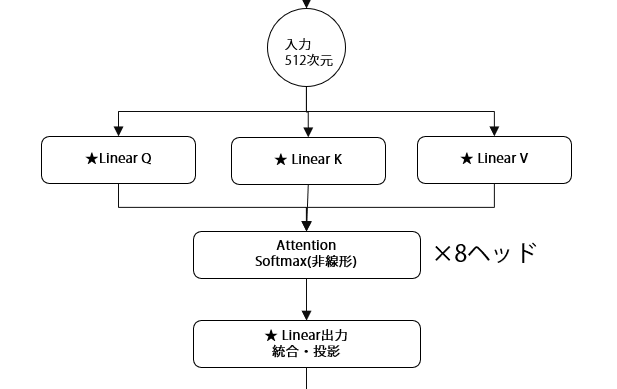
Self-Attentionでは、入力データを3つの異なる役割に変換します
- Q (Query:質問)
「私は誰と関係が深いですか?」と問いかける役割
=「誰が見ているか」(質問者) - K (Key:鍵)
「私はこういう特徴を持っています」と応答する役割
=「誰を見ているか」(マッチング対象) - V (Value:値)
「私が持っている実際の情報はこれです」と提供する役割
=「何を受け取るか」(実際の情報)
これらは全て同じ入力から作られますが、異なる重み行列(Linear層)によって、それぞれ異なる表現に変換されます。
実装上は、系列長 T、各ヘッドの次元を d_k, d_v とすると、 Q, K ∈ ℝT×d_k、V ∈ ℝT×d_v となります。 入力ベクトル X ∈ ℝT×d_model に対して、学習可能な射影行列 W_Q, W_K, W_V を掛けることで生成され、マルチヘッドの場合はさらにヘッドごとに分割して処理されます。たとえば「こんにちは」のケースで考えてみましょう。ヘッド1は前に紹介したとおり、音と音の間の隣接関係を学習するためのものでした。
このとき、Q=Query,K=Key は以下のように考えることができます
- Query軸(横・青):「どの音素が」注目するか
- Key軸(縦・赤):「どの音素に」注目されるか
「誰が」「誰を」見ているかの関係をあらわしており、
- Query:「見る側」(主語)
- Key:「見られる側」(目的語)
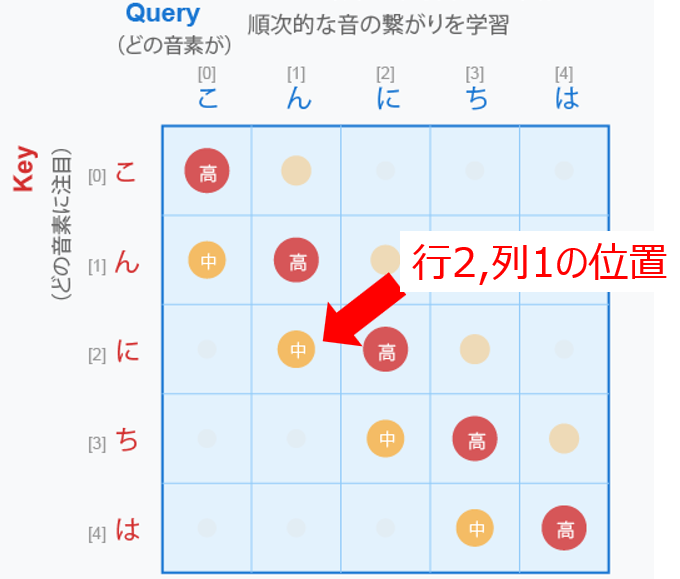
となります。たとえば、上手で、Query「ん」が Key「に」を 注目しているという部分は、以下のようになりますね
このQuery,Keyで注目計算について、具体的なプロセスでみてみましょう
STEP1.QueryとKeyで注目度を計算します
- 「ん」が「に」をどれくらい見るか → 注目度70%
- 「ん」が「は」をどれくらい見るか → 注目度10%
STEP2.次に、その注目度でValueを重み付けして取得します
- 「に」の情報(Value)を70%の重みで受け取る
- 「は」の情報(Value)を10%の重みで受け取る
STEP3.重み付けされた情報を合成します
- 最終的な「ん」の新しい表現になる
つまり↓のような感じです
Query「ん」:「次の口の形を決めるために、誰を参考にしよう?」
Key:「関連性をチェック」
- 「に」→ 次の音だから重要!(70%)
- 「こ」→ 前の音だから少し重要(20%)
- 「は」→ 遠いからあまり重要じゃない(10%)
Value:「実際の口形情報」
- 「に」の口形情報 × 70%
- 「こ」の口形情報 × 20%
- 「は」の口形情報 × 10%
↓
これらを合成して「ん」の最適な口形を決定
さて、そもそも、なぜKeyとValueを分けなければいけないんでしょうか?
それはKeyとValueが同じだと、「関連性の判断」と「取得する情報」が同じになってしまうからです(あたりまえですね)
つまり、分けることで
- Key:関連性判断用の特徴
- Value:実際に伝達したい豊富な情報
を別々に学習できます。
これにより、より柔軟で表現力の高い注目メカニズムが実現できるというわけです。
Q、K、V:郵便配達の三要素
Q(Query:質問)は「宛先を探す人」です。「この手紙を届けたいんだけど、誰が受け取ってくれるかな?」と尋ねます。
K(Key:鍵)は「住所札」です。「私はここに住んでいます!」と自分の居場所を示します。
V(Value:値)は「実際の荷物」です。届けたい大切な中身そのものです。
実際のAttentionマトリックスが表現するもの
さて、このあたりは理解がなかなか難しいのでくどいようですが、もういちどさきほどのAttentionマトリックスにもどってみましょう
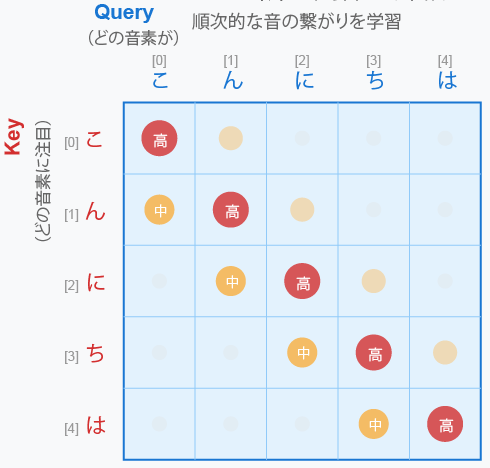
実際の計算において結局このマトリックスはなにかというと、QとKの内積によって計算された注目度スコアを視覚化したもととなります。
Attention Score = Q × K^T / √d_k
(d_k:各ヘッドの Key の次元数)
このマトリックスで
- 横軸(Query):各音素が「質問者」として、他の音素をどれだけ見ているか
- 縦軸(Key):各音素が「対象」として、他の音素からどれだけ見られているか
- 各セルの値:その音素ペアの関連性の強さ(注目度)
となるわけです。
こんどは例えば、「ん」と「に」の関係でみると、マトリックスの座標(1, 2)、つまり横軸「ん」×縦軸「に」のセルは
- 「ん」のQuery と 「に」のKey の類似度を表す
- 値が大きい = 「ん」を処理する際に「に」の情報が重要
- この注目度に応じて、「に」のValue(実際の情報)を取得する
となります。
くどいようですが、では、なぜKQVに分ける必要があるのかもういちど説明いたします
もし単一の表現だけを使うと、「関連性の判断」と「伝達する情報」が同じになってしまいます。(さきほども書きました)
これらを、分離することで
- Q-Kペア:どの要素同士が関連するかを学習(注目パターン)できる
- V:実際に伝達したい豊富な情報を別途保持できる
例えば、「ん」と「に」の音素的な類似性(K)は低くても、順序的な重要性(Q-Kの学習結果)は高く、その際に「に」から受け取る口形情報(V)は別の特徴を持つ、といった複雑な関係を表現できます。
マトリックスから実際の処理へ
再度以下のネットワーク図をおさらいすると、
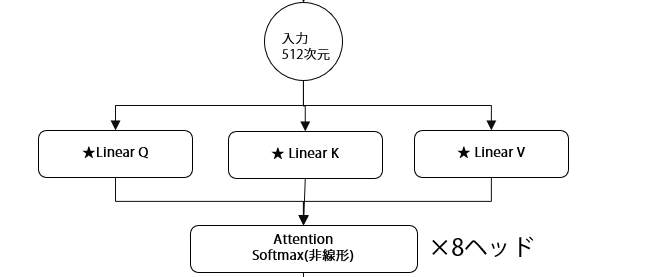
- 注目度の計算:Q×K^T でマトリックスを作成
- 正規化:Softmaxで各行の合計を1に(確率分布化)
- 情報の取得:注目度を重みとしてVを加重平均
- 結果:各音素の新しい表現(文脈を考慮した表現)
つまり、このマトリックスは「どの音素がどの音素の情報をどれだけ参照するか」の設計図であり、実際の情報(Value)はこの設計図に従って組み合わされるのです。
8つの異なる観点とAttentionマトリックス
さて、いまはヘッド1の例でみてきましたが、この節の最後に8つの異なる観点のマトリックスを視覚化してみましょう
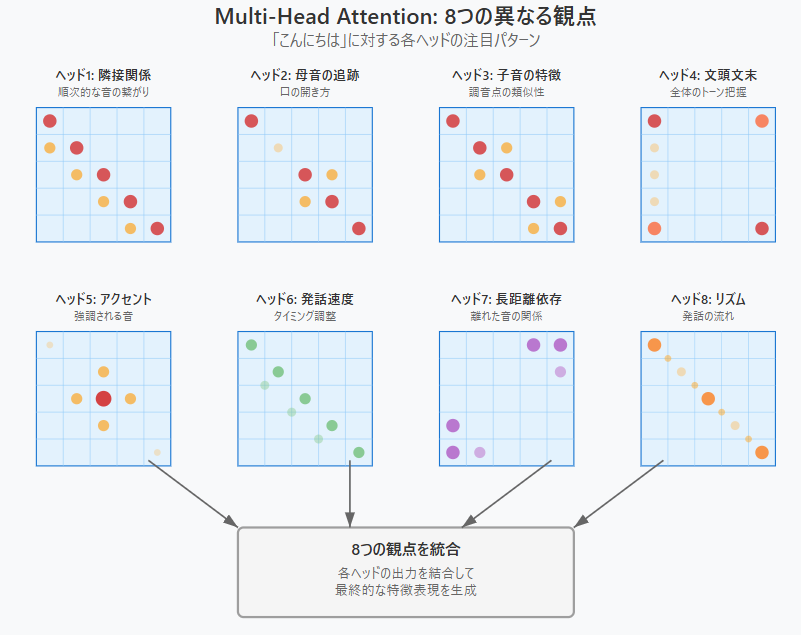
各ヘッドの特徴
各ヘッドは以下のとおりです
- ヘッド1(隣接関係): 対角線と隣接する音素に注目
- ヘッド2(母音の追跡): 母音部分と同じ母音(「に」と「ち」のi音)に注目
- ヘッド3(子音の特徴): 同じ子音(「ん」と「ん」)や類似子音に注目
- ヘッド4(文頭文末): 始まりと終わりの関係を重視
- ヘッド5(アクセント): 強調される音(「に」)を中心に注目
- ヘッド6(発話速度): 均等なタイミング調整のパターン
- ヘッド7(長距離依存): 離れた位置の音素間の関係
- ヘッド8(リズム): 波状のリズムパターン
そして、各マトリックスで色と大きさで注目度を表現しています
- 大きく濃い円 = 強い注目
- 小さく薄い円 = 弱い注目
- 色の違い = 注目の種類の違い
これらが最終的に統合されて、自然なリップシンクを生成します。
実際のAttentionマトリックスの計算:レシピの完成
8つのヘッドの統合:オーケストラの演奏
次回予告
さて、続編となる後編では、Feed-Forward層の役割とLSTMとの構造的な違いを明らかにした上で、Transformerが抱える実装上の課題に焦点を当てます。
それでは、次回またお会いしましょう!



