
[自作日記1] 現代の自作PCアーキテクチャを理解する
![[自作日記1] 現代の自作PCアーキテクチャを理解する](/content/images/size/w1200/2024/04/gpu_machine_jisaku_01.png)
PC自作にあたって、まずは、2023年現在のPCアーキというものを学んでおこうとおもいます。
CPUとマザーボードとチップセット
チップセット
マザーボードには、各パーツ間の通信を管理するための「チップセット」という重要なコンポーネントが搭載されています。
あるチップセットは対応できるCPUが決められており、そのチップセットに対応していないCPUはのせることができません。
逆にCPU側からみれば、あるCPUに対して、それに対応できるチップセットが限定されているともいえます。
あるCPUに対してチップセットは1つだけではなく、実装されている機能のレベルに応じて複数のチップセットが対応しています。
チップセットとCPUとCPUソケット形状
チップセットとCPUはお互いに対応関係が決まっていると説明しましたが、CPUをマザーボードにはめ込むときのソケット形状も物理的に一致しています。
例えば Z690 というチップセットは Intel Core i7 12700 という第12世代のCPUに対応しています。
また、 Intel Core i7 12700 のソケット形状は LGA 1700 で、
Z690 チップセットを搭載したマザーボードは当然 LGA 1700 形状のCPUをはめ込めるようになっていることになります。
第12世代CoreシリーズCPU用チップセットはインテル600シリーズと呼ばれるチップセットとなっており「Z690」「H670」「B660」「H610」など複数あり、これらはオーバークロックの対応有無など、機能面で異なります。
また、インテル700シリーズチップセットとして、「Z790」「H770」「B760」 などがあります。
実はインテル600シリーズも700シリーズチップセットともLGA1700ソケットを採用しており、
第12世代インテルCoreシリーズCPU、第13世代インテルCoreシリーズCPUどちらもはめ込むことができますが、すべてが動作するわけではなく、また、マザーボードによっては BIOS の更新が必要なものがあるため、マザーボードごとに対応を確認をする必要があります。

Credit [Jacek Halicki] / Wikimedia Commons / CC-BY-SA-4.0
ノースブリッジとサウスブリッジ
現在はCPUとチップセットにそれぞれの役割分担がありますが、ひと昔のPCではノースブリッジ、サウスブリッジとしてざっくりを役割が分かれている時代がありました。CPUとチップセットの役割分担を学ぶ上で、少しPCアーキの歴史を振り返ってみます。
ノースブリッジはマザーボードの上部に位置し、サウスブリッジは下部に位置するコンポーネントを指していました。ノースが上で、サウスが下という、一般的な地図とおなじような感覚で命名されていますね。
(Java Swing などでもノース、サウスのように指定していたので、このメタファーは昔はそれなりにわかりやすかったのでしょう。)
ノースブリッジ については、CPU、RAM、PCI Expressデバイス(例えばグラフィックカードなど)と直接通信を行うもので、この部分は高性能が求められるため、高速な通信が必要とされる部品と接続される役割を果たしてきました。
しかし、現在では、 ノースブリッジの機能は多くの場合、CPUに統合されており 、チップセットではなくCPUがこれらの高速通信の仕事を担当しています。
サウスブリッジ に関しては、IOデバイス(USB、オーディオ、シリアルデバイスなど)、BIOS、IDE、LANカードなどと通信を行います。これらは比較的低速で、大量のデータ転送を必要としないコンポーネントです。
現在、サウスブリッジの役割は主にチップセット によって担われています。
というわけで、高速通信をする仕事は CPU 、IOデバイスのように低速な仕事はチップセットのように棲み分けていると覚えておけばOKです。
PCI Express と「レーン」
PCI Expressは、グラフィックカードをはじめとする各種拡張カードをマザーボードに接続するためのスロットおよび通信規格です。この規格には「 レーン 」と呼ばれる伝送路が用いられており、データの送受信が行われます。
レーンは、単独で使用されることもありますが、 複数のレーンを束ねることにより、さらに高速な通信が可能 になります。このようにレーンを束ねることで、データ転送の効率を大幅に向上させることができ、高性能な拡張カードが求める大量のデータ転送を効率的に処理することが可能です。このため、PCI Expressは現代のコンピュータシステムにおいて重要な役割を担っています。
PCI Express には レーン という伝送路があり、 複数のレーンを束ねる と速くなる、と覚えておきましょう。
レーンのスピード
レーン1本あたりのスピードは PCI Express の 世代 ごとに規格によって以下のように、定められています。
- PCI Express は PCIe のように省略して記述することができます
- PCI Express には世代(バージョン) があり PCI Express version 1.0 を gen1, PCI Express version 2.0 をgen2 のように略記されることがあります。
| 世代 | 伝送速度(片方向) | |
|---|---|---|
| PCIe gen 1 | 2.5 gbits/s | 0.3125 gbytes/s |
| PCIe gen 2 | 5 gbits/s | 0.625 gbytes/s |
| PCIe gen 3 | 8 gbits/s | 1 gbytes/s |
| PCIe gen 4 | 16 gbits/s | 2 gbytes/s |
| PCIe gen 5 | 32 gbits/s | 4 gbytes/s |
表のように第5世代の PCI Expressだと、レーンが1本で 4GByte/s の通信速度となっています。
PCI Expressの 世代があがるごとに2倍の伝送量になっていますね。
複数レーンをたばねたときの伝送速度一覧
たとえば、PCIe gen 5でレーンを16本束ねた伝送路を PCIe gen5 x16 などと書きます。
これは 64GB/s でデータを伝送できる、ということになります
以下に、レーンを束ねた本数と、伝送速度をまとめました。
x4 (4レーン使用時の帯域)
| 世代 | 伝送速度(片方向) | |
|---|---|---|
| PCIe gen 1 | 10 gbits/s | 1.25 gbytes/s |
| PCIe gen 2 | 20 gbits/s | 2.5 gbytes/s |
| PCIe gen 3 | 32 gbits/s | 4 gbytes/s |
| PCIe gen 4 | 64 gbits/s | 8 gbytes/s |
| PCIe gen 5 | 128 gbits/s | 16 gbytes/s |
x8 (8レーン使用時の帯域)
| 世代 | 伝送速度(片方向) | |
|---|---|---|
| PCIe gen 1 | 20 gbits/s | 2.5 gbytes/s |
| PCIe gen 2 | 40 gbits/s | 5 gbytes/s |
| PCIe gen 3 | 64 gbits/s | 8 gbytes/s |
| PCIe gen 4 | 128 gbits/s | 16 gbytes/s |
| PCIe gen 5 | 256 gbits/s | 32 gbytes/s |
x16 (16レーン使用時の帯域)
| 世代 | 伝送速度(片方向) | |
|---|---|---|
| PCIe gen 1 | 40 gbits/s | 5 gbytes/s |
| PCIe gen 2 | 80 gbits/s | 10 gbytes/s |
| PCIe gen 3 | 128 gbits/s | 16 gbytes/s |
| PCIe gen 4 | 256 gbits/s | 32 gbytes/s |
| PCIe gen 5 | 512 gbits/s | 64 gbytes/s |
新しい世代ほど速く、たくさん束ねるほど速くなるということですね。
コラム:1Bytes/s の伝送路で 4k 画像は1秒間で何枚送信できる?
4K画像 1枚は 3,840×2,160 = 8,294,400 ピクセルあり、 各ピクセルでRGB各8ビット(1バイト)だとすると 無圧縮状態で 8294400*3 = 24883200 バイト(24MBytes)となります。 ここで 1GBytes は 1024*1024*1024 = 1073741824 バイトなので、 1073741824 ÷ 24883200 = 43.15 つまり、1GByte の伝送路だと 1秒間に4K 画像を 43 枚伝送できることになります。(理論値では) PCIe gen 5 x 16 の場合は 64 gbytes/s なので、4K 画像なら 43*64 = 2761 枚ということになる。 画像を送るだけなら、 2761 FPS を出せるということになります。
PCI スロットの形状
PCIe スロットの形状には以下のような規格があります。
PCI Express x1 スロット
PCI Express x4 スロット
PCI Express x8 スロット
PCI Express x16 スロット
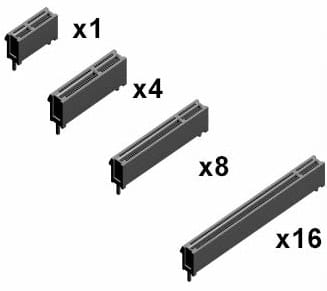
Credit Erwin Mulialim / Wikimedia Commons / CC BY-SA 3.0
これらは、あくまでスロットの物理的なサイズで分類したもので、
物理的な形状が PCI Express x16スロットでも、
内部では x8 のレーン帯域しか対応していない PCI Express スロットもあります。
また、物理的な形状が x16なPCIe拡張ボードでも、
その拡張ボードが x8レーン帯域しか使わないという場合もあります。
スロットの形状と、内部での使用レーン数は必ずしも一致しないということ覚えておきましょう
PCI スロット数
E-ATX、ATX フォームファクタ(ケース)の場合、PCI expressのスロット数は 7 スロットとなります。
今回はここまでです!
おつきあいありがとうございました!
次回は、実際のチップセットのブロック図をみながら理解を深めていきたいとおもいます。
navigation




{kind=link}