
[自作日記2] CPUとチップセットと PCI Express の関係
![[自作日記2] CPUとチップセットと PCI Express の関係](/content/images/size/w1200/2024/04/gpu_machine_jisaku_02.png)
こんにちは!今日はCPUとチップセットについて学びたいとおもいます!
最終的にはAI開発に使えるGPUマシンをつくりたいのですが、GPUってパソコンのどのあたりに入れて使うものでしょうか。

はい、正解は、パソコンのPCI Express のスロットに挿して使います。
「知っとるわ」という声が聞こえました。
さすがです。
では、次の問いです。
GPU が挿さる PCI Express スロットのレーンはどこにつながってるのでしょうか?
1.「チップセット」
2.「CPU」
正解は2のCPUです。
この問いの答えが一瞬で出た方は、本記事を読みとばしていただいて問題ありません。
「?」となった方は、本記事に参考になる部分があるかもしれません。
ということで、GPU は PCI Express という拡張スロットに挿して使うことはご存じかもしれませんが、PCI Express は内部でどのようにつながっているのでしょうか。実はGPUパソコンを作るときにこの辺がけっこう重要になります。
今後、GPU2枚挿し、GPU4枚挿し、など本格的なGPUマシンを作るときにもこのあたりの知識が重要になりますので、学んでおいて損はないですね。
さあ、進めていきましょう!
先ほどの問いの続きから、ですが、
PCI Express には CPU と直接つながっているものと、チップセットからつながっているものの2種類があります。
まずはPCI Express から CPU やチップセットにつながっている伝送路= 「レーン」についてもう少しみていきましょう
PCI Express と CPU をつなぐレーン
前述のとおり、PCI Express は CPU から直接つながるものと、チップセットからつながるものがあります
-
PCI Express ⇔ CPU
-
PCI Express ⇔ チップセット
では、具体的に見ていきましょう。
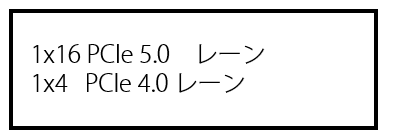
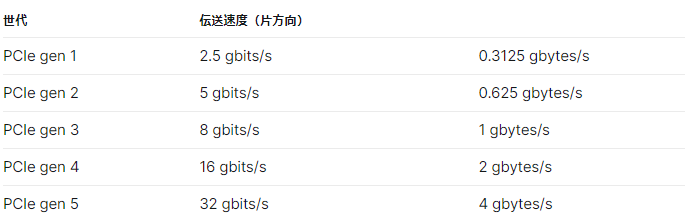
CPUとPCI Express が接続されているレーンは、たとえば、 第12世代のインテル Core シリーズCPU の場合、CPUから直接PCI Express に
接続されるレーンは 20本 あります。
その内訳は、
- PCIe gen 5 16レーン
- PCIe gen 4 4レーン
となっています。
「gen5 のレーンが 16本ってこと? gen4 のレーンが 4本ってこと? CPUからPCIExpressにのびているレーンの本数と規格が違うの?」
はい、そのとおりです。
レーンには1本ずつ規格があり、このレーンは PCIe gen5(=PCI Express の5世代目 という意味でしたね) 、このレーンは PCIe gen4 のようにそれぞれ規格がわかれています。
パソコンの中でCPUやチップセットにつながってるPCI Expressのレーンは全てがおなじ規格ではない、というのがまずポイントです。
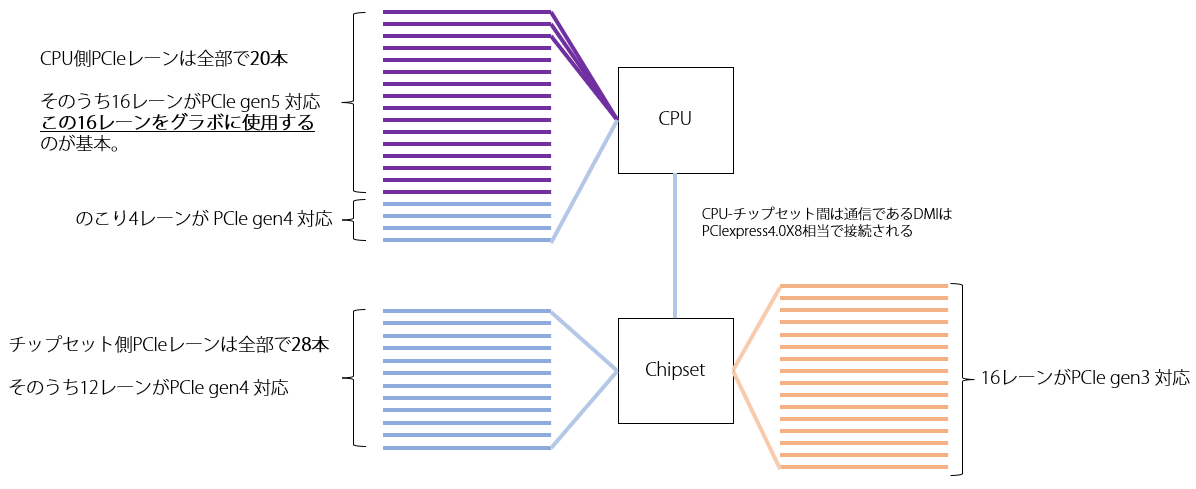
では、実際に インテルの12世代CPU に対応した Z690 チップセット というものの、ブロック図をみながら理解を深めていきましょう。
(ブロック図とは、システムの構成要素を図にしたものです。)
以下は Z690 チップセットのブロック図です。
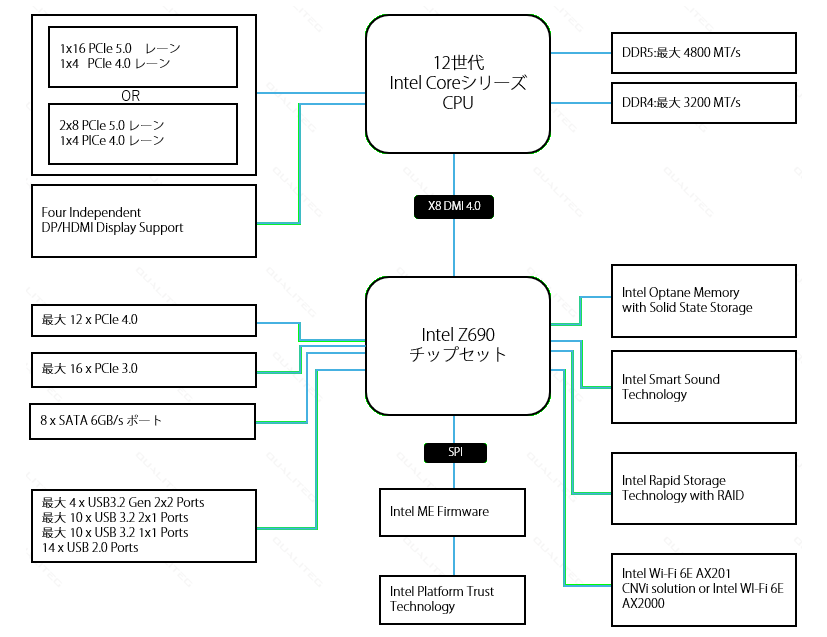
このブロック図を全部ただちに理解する必要はありません。
私たちは 、ふつうのパソコンではなく、「GPU搭載マシン」を作るので、GPUマシンにとって必要なところを学びます。
GPUにとって重要なのはこのブロック図の左上です。赤で示しました。
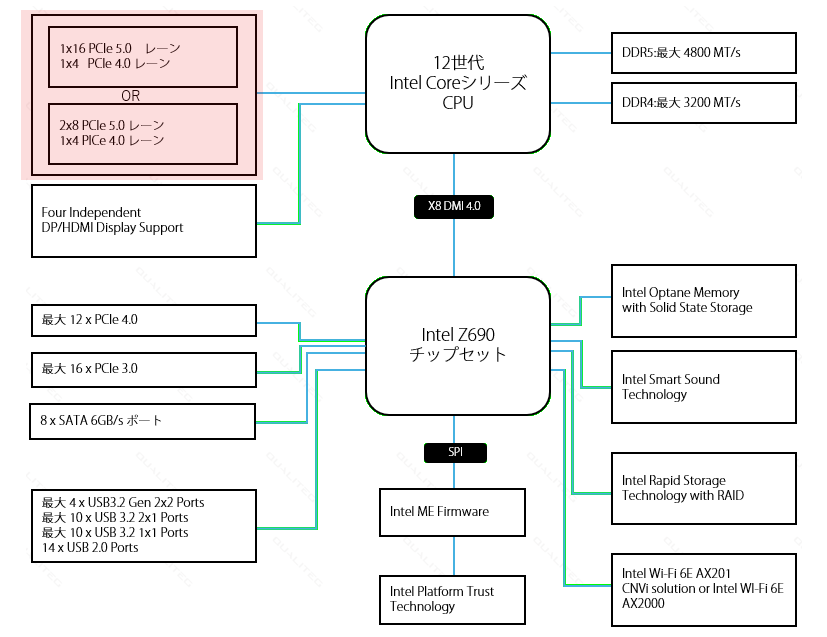
まずは、ここを読み解いていきましょう。
拡大するとこんなかんじです。
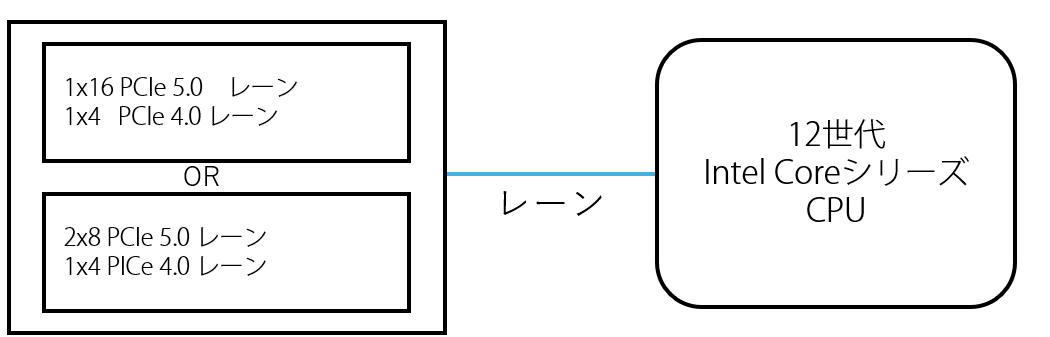
これは、 CPU と直接接続されている PCI Express について説明しています。
この左上あたりをみると、
のように書いてあります。
これが冒頭にかいたとおり CPU から PCI Express のレーンが 20 本のびている 件です。 16本の PCIe 5.0 レーンと 4本の PCIe 4.0 レーンの合計 20本のレーンが CPU と直接接続されています。
つまり、 合計20本あるレーンのうち
・gen5 規格 のPCI Express のレーンを16本束にしたスロット
・gen4 規格 のPCI Express のレーンを4本束にしたスロット
が使えるよ。といっています。
そして、通常、CPU からのびてる、この gen5 規格 のPCI Express のレーンを16本束にしたスロット が グラフィックボード(GPU) 用に使用されます!
PCIe 5.0 は前回の記事に示した通り、大変高速ですので、GPUのような高速データ転送を要求される用途向きというわけです。
理解をより深めるために、レーン1本ずつを視覚的に示してみました
GPUが主眼なので、GPU が接続される CPU ⇔ PCI Express に着目しましたが、基本的には、他のレーンも同じです。
PCI Express には、チップセット側と接続されているレーンもあり、上の図のようになっています。
この仕組みが理解できると、マザーボードやチップセットのスペックシートが読み解けるようになります。
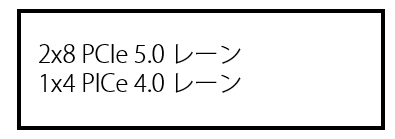
さて、さきほどのブロック図の左上には↓という表記も書いてありました。これはどういうことでしょうか。
自作の先に、研究・業務用のGPU環境を考えるなら。
GPUマシンを自分で組む知見は、そのまま研究・PoC・本番のインフラ選定に効きます。
私たちは自社で独自の GPU クラスターを構築・運用し、LLM プロダクトを開発しています。また研究用GPUワークステーションの調達から、インテル Core アーキテクチャ、インテル Xeon アーキテクチャなど、コンシューマーユースからプロユースまで幅広くご支援可能です。ワークステーションの調達・構築支援だけでなく、その先の学習環境の整備、最適な GPU 選定・推論最適化・分散構成まで、運用経験に基づいてアドバイスします。
LLMインフラ・基盤技術の支援を見る →そちらは、次回にご説明いたします。
これはグラボ二枚挿しにも関係のある内容となっていますのでご期待くださいませ!
それでは、また次回お会いしましょう
navigation



