
[自作日記11] マザーボードとケースの配線をする
![[自作日記11] マザーボードとケースの配線をする](/content/images/size/w1200/2024/04/gpu_machine_jisaku_11.png)
今回は、マザーボードをケースに装着し各種配線を行っていきます!

1. スペーサーネジをはめる
ケースにはスペーサーネジというものが付属しています。これをケースにハメていきます。スペーサーはマザーボードを ”浮かせた” 状態で固定するためのものです。
このスペーサーをケースにあいたネジ穴にはめていきます。ケースにはネジ穴があらかじめあいており、ネジ穴にはヒントが書いてあります。
今回のケースには ATX と Mini ATX のフォームファクタのマザーボードに対応しており、ネジ穴は、どのフォームファクタ向けのネジ穴なのかがヒントとして書いてあります。

フォームファクタとは
PCケースのサイズや形状の規格を指し、主にマザーボードとの互換性に基づいて定義されます。主なフォームファクタには以下のようなものがあります:
- ATX:
- 標準ATXは、最も一般的なフォームファクタで、多くの拡張スロットと豊富な接続ポートを備えています。サイズはおおよそ30.5cm x 24.4cmです。
- Micro-ATX(マイクロATX)は、標準ATXよりも小さく、サイズは約24.4cm x 24.4cm。拡張スロットが少ないが、よりコンパクトなPCを構築する際に選ばれます。
- Mini-ATXはさらに小さいフォームファクタで、非常に限られたスペースに適しています。
- Mini-ITX:
- サイズは約17cm x 17cmで、非常に小型のPCケースに収まる設計です。省スペースのPCやメディアセンター、小型サーバーなどに適しています。
- E-ATX(拡張ATX):
- 標準ATXよりも大きく、主に高性能なワークステーションやゲーム用PCに使われることが多いです。サイズが大きいため、より多くの拡張カードやその他のコンポーネントを収容することができます。
今回のPCケースは ATX フォームファクタですが、 それより小さなMini ATX のマザーボードもつけられるというわけです。
そのため、ATX 用のネジ穴と、Mini ATX 用のネジ穴が開いています。
今回のマザーボードは ATX 用なので、 ATX 用のネジ穴にスペーサネジを取り付けます。
ちなみに、万が一スペーサネジをとりつけずに、マザーボードをPCケースに直置きしまうと、漏電して、大変なことになりますので、絶対にスペーサネジをわすれないようにしましょう。
2.マザーボードをケース内に置く
スペーサを付けたら、マザーボードをケース内にそっと配置します
マザーボード上にあるネジ穴といましがたとりつけたスペーサーが同じ位置にくるように調整しておきます

付属のネジをつかってマザーボードを固定します
この付属ネジはころがって紛失しやすいので、きをつけましょう。

ちなみに、当社にはPC組立修理部屋があり、無くしやすいパーツ類は常に予備を在庫しています。ネジ類はそんなに比較的安価に手に入るので、予備は手元においておくと便利かもしれません。

3.マザーボードとケースの結線
マザーボードと結線されるのは周辺パーツだけではありません。
PCケースには、フロントパネルに電源スイッチ、USB端子、オーディオ端子などが設置されており、それらとマザーボードを結線する必要があります。
3-1 電源ボタン、リセットボタンなどを結線
ケース側から伸びたケースフロントパネルの電源ボタン一式ケーブルをマザーボードに接続します。
マザーボードのこのあたりが、フロントパネルの電源ボタン一式ケーブルを接続するジャンパーピンのありかです。

マニュアルをみてピンレイアウトを確認します。
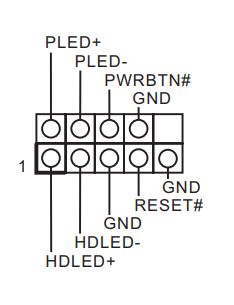
このピン配置だけみても、ピンとこないかもしれませんので、以下補足してみました
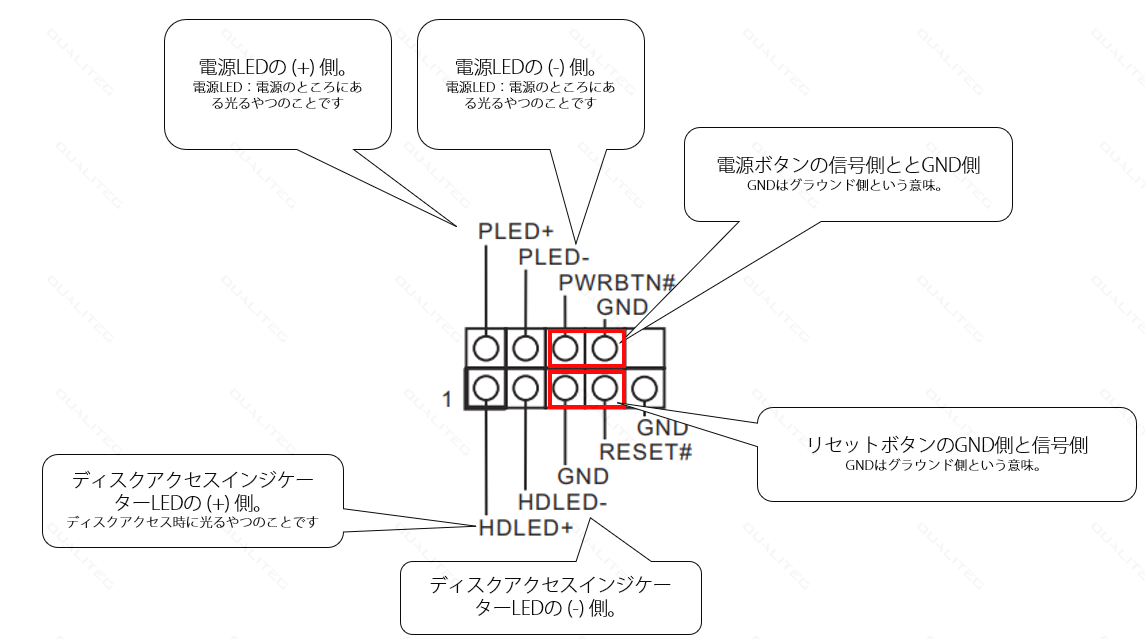
これを参考にして、PCケースの電源系ケーブルをマザーボードに挿していきましょう。少し細かい作業となります。

こんな感じで、マザーボード側にある電源用ジャンパーピンにPCケースからのびたフロントパネル電源コネクタを接続します。
さっきのピンレイアウトをちょうど逆からみたような形です。

反対側もこのように装着しました

3-2 USB3ケーブルの接続
次に、PCケース側からのびたUSB3ケーブルをマザーボードに接続します


3-3 USB2 ケーブルの接続
同様に、ケース側からのびた USB2ケーブルをマザーボードに接続します

3-4 SATAケーブルを挿す
5インチベイに入れたSATAリムーバルケースから伸びたSATAケーブルを、マザーボードのSATAコネクタに挿します。ここでは SATA A というコネクタに挿しました。たいていは、マザーボード上に表記されていて便利です。

3-5 オーディオケーブルを挿す
ケース背面からのびているオーディオケーブルをひっぱりだし

マザーボードのHD AUDIO1 に挿します。

オーディオケーブルまで接続できたので、PCケースのフロントパネル用のケーブルはこれでぜんぶ結線できました!
次回はグラフィックボードを設置します!
navigation



