
[自作日記20] SW編: コードをGPUで動かす
![[自作日記20] SW編: コードをGPUで動かす](/content/images/size/w1200/2024/04/gpu_machine_jisaku_20.png)
早速、GPUで Pythonコードを動かしてみましょう
4.3 Jupyter Notebook で GPUを活用したPytorchコードを記述する
STEP1 端末(ターミナル)を開いて、PyTorchプロジェクト用のディレクトリを作る
以下のコマンドを入力します
mkdir pytorch_pj
cd pytorch_pj
STEP2 Jupyter Notebook の起動
ディレクトリに移動したら
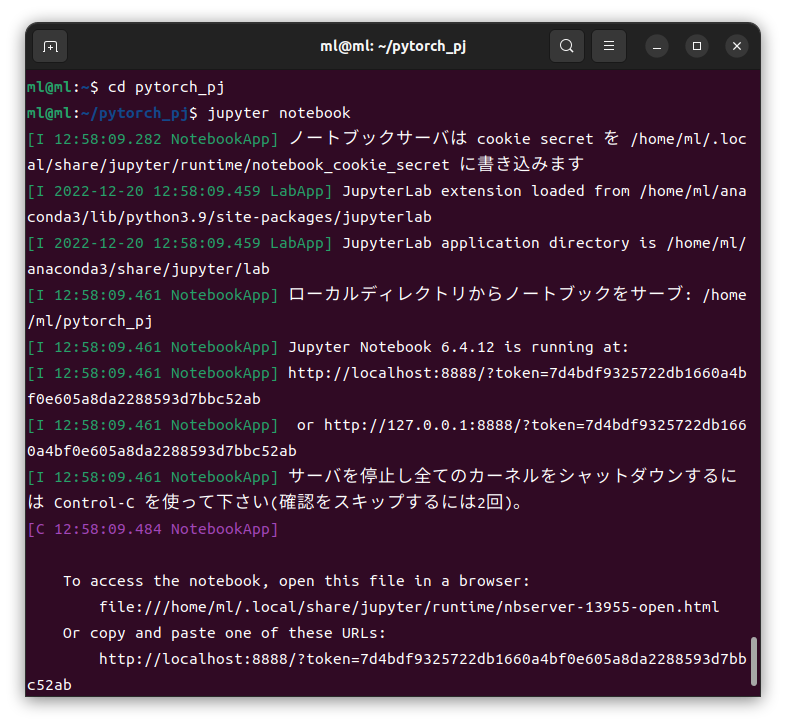
jupyter notebook
でJupyter Notebook(ジュピターノートブック)を起動します
Jupyter Notebook はPythonのコード作成と実行、実行結果表示、自由コメント(Markdown)編集の3つの機能をそなえたツールで、気軽に利用できるので、Jupyter Notebook上で試してみましょう
Jupyter Notebook が起動しました
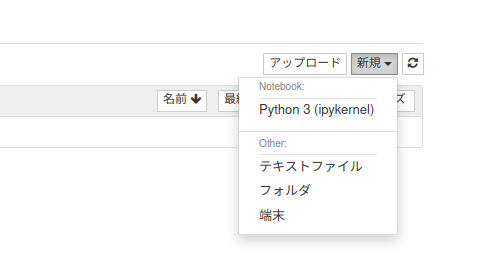
右上の 新規 をクリックして Python3 を選択します
STEP3 コードを記述
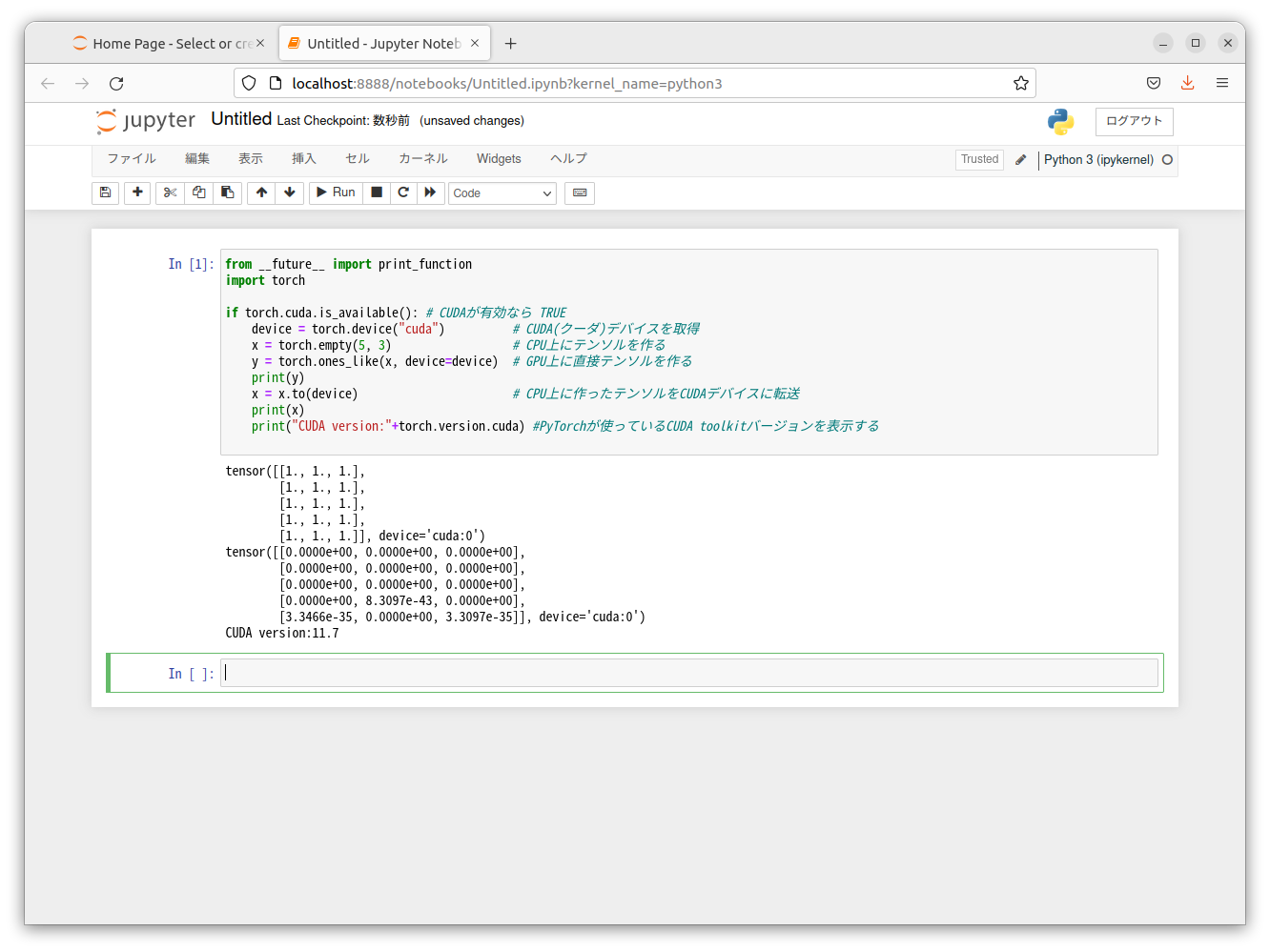
以下のコードを起動した 新しい Notebook に記述します
from __future__ import print_function
import torch
if torch.cuda.is_available(): # CUDAが有効なら TRUE
device = torch.device("cuda") # CUDA(クーダ)デバイスを取得
x = torch.empty(5, 3) # CPU上にテンソルを作る
y = torch.ones_like(x, device=device) # GPU上に直接テンソルを作る
print(y)
x = x.to(device) # CPU上に作ったテンソルをCUDAデバイスに転送
print(x)
print("CUDA version:"+torch.version.cuda) #PyTorchが使っているCUDA toolkitバージョンを表示する
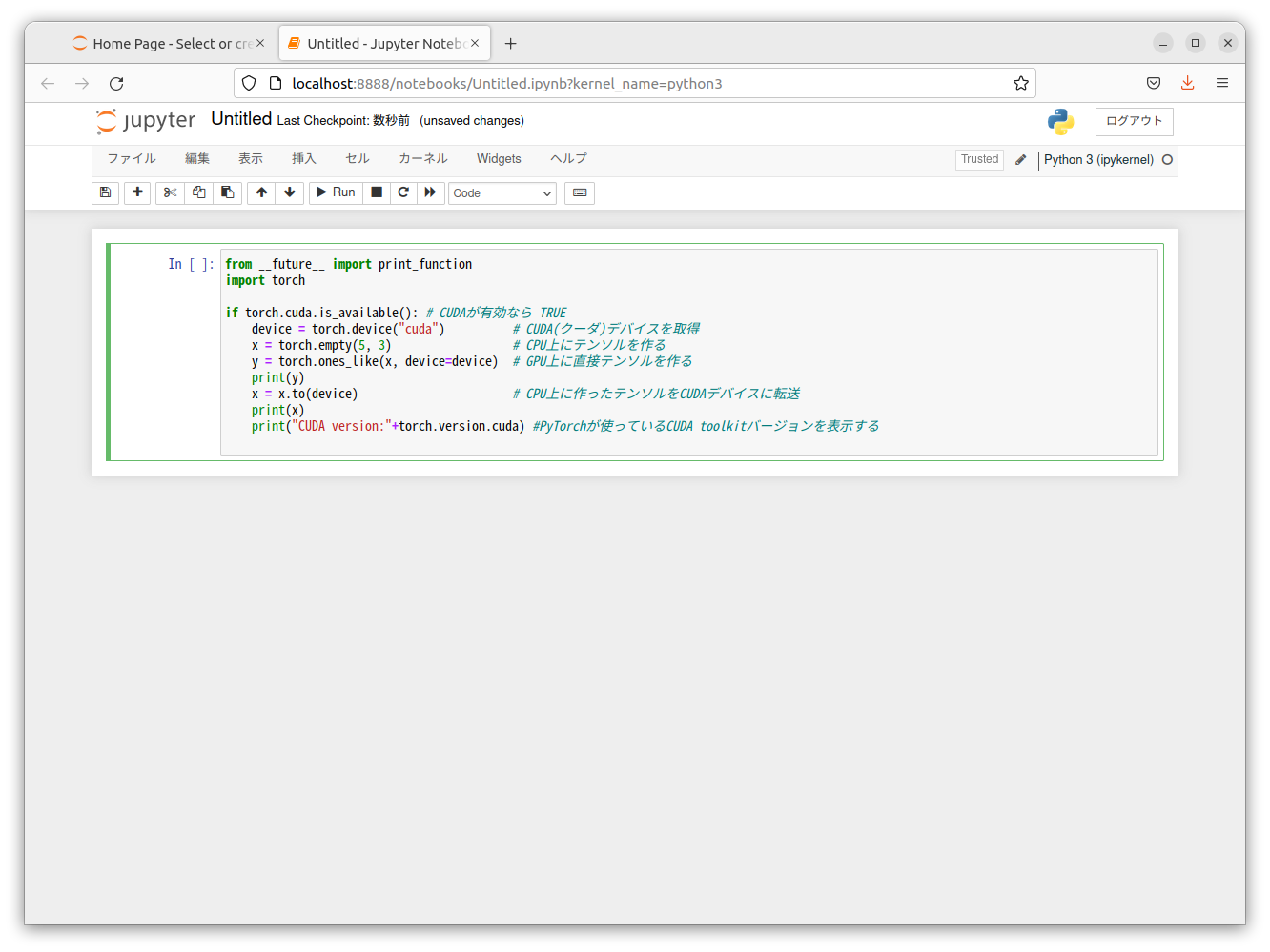
RUN をクリックします
無事、CUDA をつかって GPU で実行できたことが結果から確認できます
これで、セットアップはすべて終了です!
これで GPUを活用した AI 開発 の準備が完了しました!
Qualiteg 技術コンサルティング
自作の先に、研究・業務用のGPU環境を考えるなら。
GPUマシンを自分で組む知見は、そのまま研究・PoC・本番のインフラ選定に効きます。
私たちは自社で独自の GPU クラスターを構築・運用し、LLM プロダクトを開発しています。また研究用GPUワークステーションの調達から、インテル Core アーキテクチャ、インテル Xeon アーキテクチャなど、コンシューマーユースからプロユースまで幅広くご支援可能です。ワークステーションの調達・構築支援だけでなく、その先の学習環境の整備、最適な GPU 選定・推論最適化・分散構成まで、運用経験に基づいてアドバイスします。
LLMインフラ・基盤技術の支援を見る →navigation



