
個人情報検出の精度を、どう正しく語るか ― Recall、信頼区間、代表性から考える評価設計
こんにちは。Qualiteg研究部です。
私たちは、個人情報(PII)や機密情報、要配慮個人情報を含むセンシティブな情報を検出・マスキングする技術(https://pii-fi.com)の開発に取り組んでいます。
その中で日々向き合っているのが、
「精度の数字を、どうすれば正直に、正しく語れるのか」
という問題です。
たとえば、検出器の Recall(再現率)が 0.95 だったとします。
これは高い数字に見えます。しかし、その数字はどの種類の文書で測ったものなのか。正解データはどう作ったのか。サンプル数は十分なのか。別の業務文書にも同じ数字を当てはめてよいのか。
精度の数字は、単独ではほとんど意味を持ちません。
「何を、どの条件で、どう数えたか」とセットになって、はじめて実務で使える数字になります。
本記事では、私たちが PII 検出の精度評価に取り組む中で得た、精度を誠実に語るための考え方を紹介します。アルゴリズムの中身ではなく、評価のしかたに焦点を当てます。
1. はじめに:「Recall 0.95 です」を信じていいか
開発の初期、私たちは社内で用意した合成データ(人工的に作ったテスト文書)で精度を測り、非常に高い数値を得ていました。
ほぼ取りこぼしゼロに近い、と。
しかし、実際の文書で測り直したところ、数値は大きく下回りました。
理由はシンプルで、合成データは「自分たちが想定したパターン」しか含んでおらず、現実の文書が持つ多様さ・崩れ・想定外を反映していなかったからです。
あとで振り返ると、その合成データには「同じ正解を少しずつ変えて大量に並べる」ような偏りがあり、見かけ上のスコアだけが高く出ていました。いわば自分で作った問題を自分で解いて満点を取っていたようなものです。
ここから得た教訓はとても明快で、
精度の数字は、何で・どう測ったかとセットでなければ意味を持たない。
「0.95 が出ました」は、それだけでは何も言っていないに等しい、ということです。
本記事は、この「何で・どう測ったか」を、どこまで詰めれば数字を信用してよいのか、という話だとお考えください。

2. なぜ「取りこぼし」が命なのか
個人情報の検出・マスキングでは、見逃し(取りこぼし)が一番こわい誤りです。
検出しすぎ(過検出)は、情報の可読性や業務上の利用価値を下げます。契約書・医療文書・問い合わせ履歴などで過剰にマスクすれば、業務判断に必要な情報が消えたり、監査・検索・分析に支障が出たりします。
一方で見逃しは、個人情報や機密情報がそのまま残るため、外部共有や二次利用の場面ではより重大なリスクになりやすい誤りです。
つまり、2種類の誤りはコストが非対称です。
- 見逃し(取りこぼし)
個人情報・機密情報がそのまま残る。外部共有・二次利用では特に重いリスク。 - 過検出(取りすぎ)
可読性や業務上の利用価値を下げる。リスクの性質が見逃しとは異なる。
だからこそ私たちは Recall を最重要指標に置いています。
ただし、過検出を無制限に許してよいわけではありません。何でもかんでも隠してしまえば Recall は簡単に上がりますが、それでは使い物になりません。
「取りこぼしを限界まで減らしつつ、過検出も実用範囲に収める」
という綱引きの中で評価する必要があります。
そして私たちが Recall を高くすること以上に重視しているのが、「Recall を正しく測り、正しく言えること」です。
測り方が甘ければ、高い数字も砂上の楼閣だからです。
では、その「測り方」の土台から見ていきましょう。
3. 土台としての混同行列(Confusion Matrix)
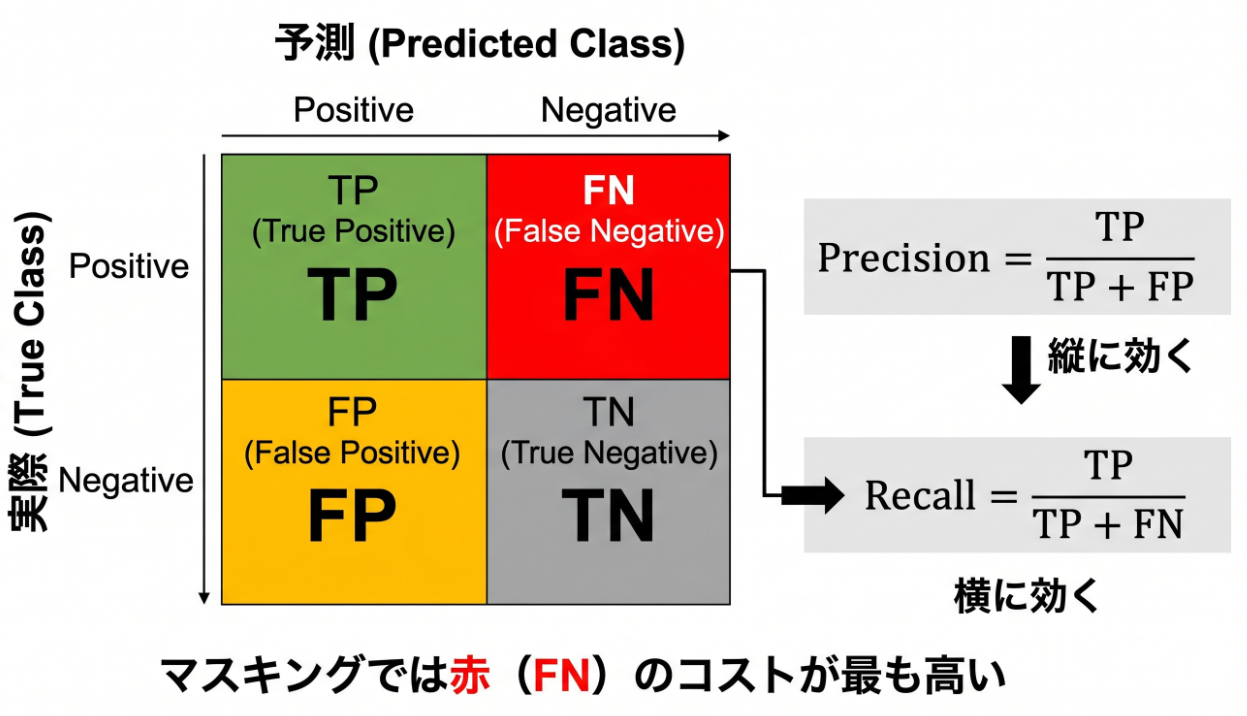
精度の議論は、すべて混同行列という単純な表から始まります。
検出結果を、「正解(実際に個人情報か)」と「予測(検出器が個人情報と判定したか)」の組み合わせで4つに分けたものです。
| 予測:検出した | 予測:検出しなかった | |
|---|---|---|
| 正解:個人情報である | TP(正しく検出) | FN(見逃し) |
| 正解:個人情報でない | FP(過検出) | TN(正しく検出せず) |
| 記号 | 日本語 | 意味 |
|---|---|---|
| TP(True Positive) | 真陽性 | 個人情報を正しく検出できた。 |
| FP(False Positive) | 偽陽性 | 個人情報でないものを誤って検出した(過検出)。 |
| FN(False Negative) | 偽陰性 | 個人情報を見逃した(取りこぼし)。流出につながる最重要の誤り。 |
| TN(True Negative) | 真陰性 | 個人情報でないものを、正しく検出しなかった。 |
ここから、よく使う指標が定義されます。
- Precision(適合率)= TP ÷(TP + FP):検出したもののうち、本当に個人情報だった割合。「過検出の少なさ」。
- Recall(再現率)= TP ÷(TP + FN):本来検出すべきもののうち、実際に検出できた割合。「取りこぼしの少なさ」。
- F1スコア:Precision と Recall の調和平均。両者のバランスを1つの数字で見るときに使います。
ここで、個人情報検出という抽出タスクならではの落とし穴を2つ挙げます。
(1) TN(正しく検出しなかった部分)は、事実上カウントできません。
文書の中で「検出されなかった箇所」は、文字単位・語単位で考えれば無数にあります。そのため、混同行列のうち TN を使う指標~たとえば Accuracy(正解率)~は、このタスクではほとんど意味をなしません。
「ほとんどの部分は個人情報ではない」ので、何も検出しなくても Accuracy は極端に高く出てしまうのです。
だから私たちは Accuracy を使わず、Precision・Recall・F1 で語ります。
(2) 「当たり/外れ」は、位置のずれをどう扱うかで変わります。
個人情報は文書中の「範囲(スパン)」として現れます。
検出した範囲と正解の範囲が、完全に一致するとは限りません。たとえば住所を、末尾の一文字だけ短く検出してしまうこともあります。こうした部分的なずれを「当たり」とみなすか「外れ」とみなすかで、数字は変わります。私たちは、まず「正しい種類のものを、おおむね正しい位置で捉えられたか(重なりで判定)」を基準にし、そのうえで「範囲がぴったり一致した割合(境界一致率)」を別途とって、品質を二段階で確認しています。
このように、同じ「Recall」でも、TN の扱い・位置ずれの扱いといった定義次第で数字は動きます。
だからこそ、数字の前にまず「どう数えたか」を共有することがとても重要となります。
4. ひとつの数字の罠:信頼区間(CI)
定義がそろったら、次は「その数字をどれだけ信用してよいか」です。
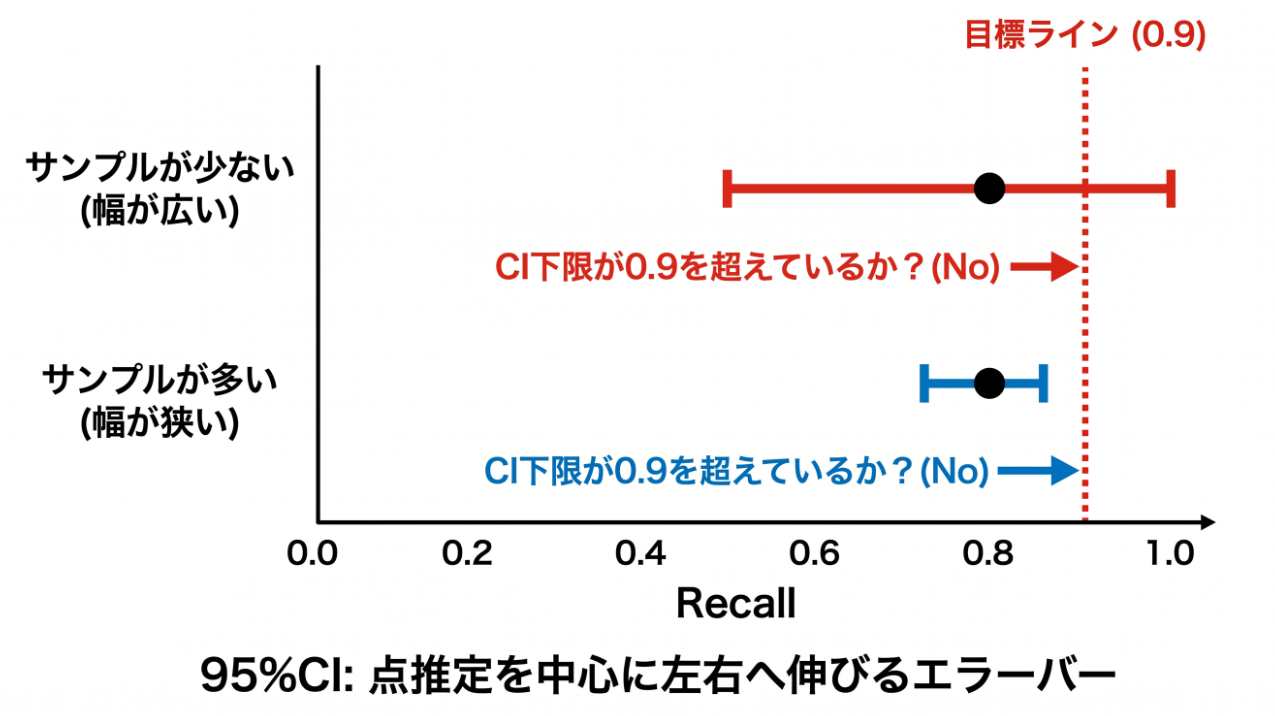
「Recall 0.95」と書くとき、それは一点の推定値にすぎません。
評価に使った文書が少なければ、たまたま良かった/悪かった、という揺れが大きく乗ります。
極端な話、5件しか測っていない 0.95 と、500件で測った 0.95 は、信用度がまったく違います。
そこで私たちは、数字を必ず信頼区間(Confidence Interval, CI)つきで扱います。
たとえば「0.95(95%信頼区間 0.88〜0.98)」のように、幅で語るのです。サンプルが増えるほど、この幅は狭くなります。
割合(Recall は「正解のうち当てた割合」という割合です)の信頼区間は、少数でも極端にならない計算方法を用いて求めます。
実務上は、単純な正規近似だけでなく、Wilson 区間や Clopper–Pearson 区間など、サンプル数が少なくても破綻しにくい方法を使います
(数式までは踏み込みません。本記事は評価思想の話なので、方法名の提示にとどめます)。
ここで強調したいのは、信頼区間が「表すもの」と「表さないもの」です。
- 信頼区間が表すもの
同じ性質の文書からもう一度サンプルを取り直したときの、数字の揺れ(サンプリング誤差)。 - 信頼区間が表さないもの
対象とする文書の種類(ドメイン)が変わったときのズレ
つまり、ある種類の文書で「0.88〜0.98」と出たとしても、それはまったく別の種類の文書での性能を、いっさい保証しません。
たとえるなら信頼区間は
「同じ池でもう一度釣りをしたときのブレ」を教えてくれますが、
「別の池でも釣れるか」は教えてくれない、
というイメージです。
ここを混同すると、「うちは 0.9 出ます」が独り歩きします。
5. ドメインが変わると、性能は別物になる
個人情報といっても、現れ方は文書の種類によって大きく異なります。契約書、業務報告、各種ログ、判例、医療系の記録……それぞれ語彙も書き方も、個人情報の出方も違います。
さらに、同じ「氏名」でも、フォーマルに整って書かれる文書もあれば、崩れた表記や省略が多い文書もあります。
私たちの経験から、横展開しやすいものとドメインごとに作り込みが要るものは、はっきり分かれます。
- 横展開しやすい→形式が明確な情報(カード番号、IPアドレス、各種コードなど)。形式が決まっているため、種類の違う文書でも比較的安定して扱えます。
- ドメイン依存が強い→人名・組織名・地名などの固有名詞。語彙や文脈への依存が大きく、文書の種類が変わると取りこぼし方も変わります。
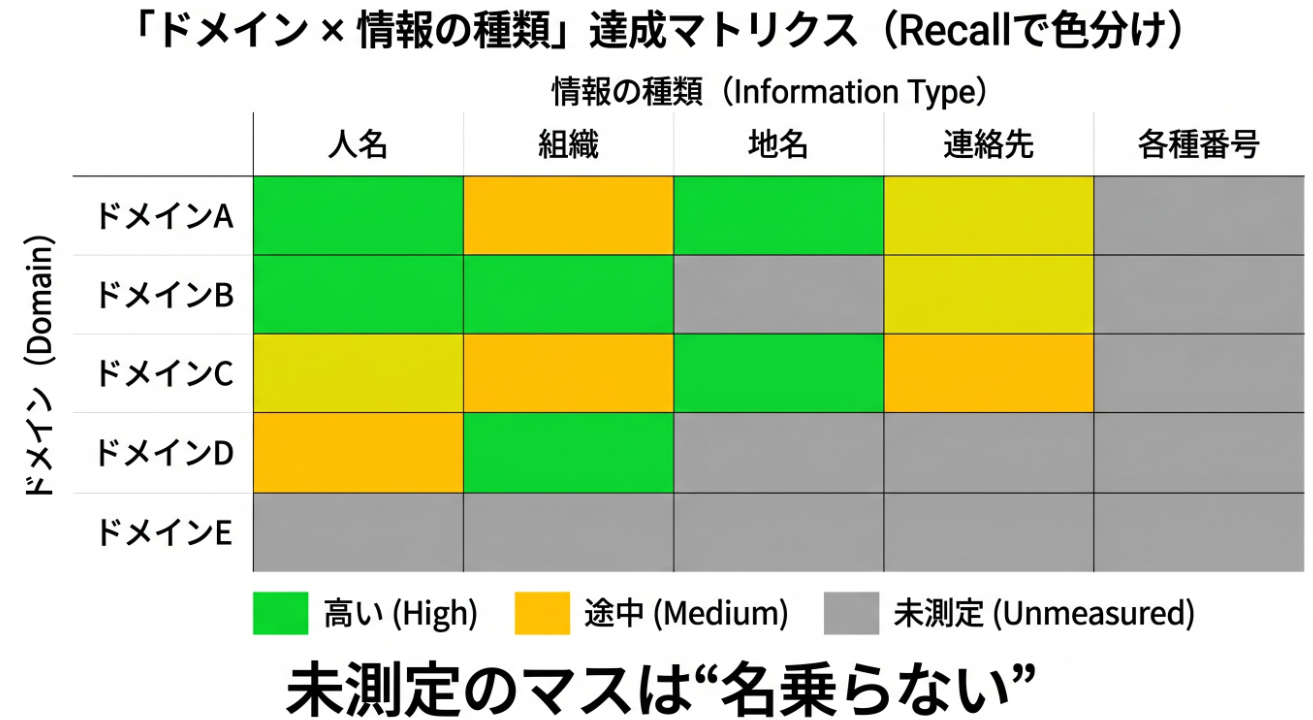
ですから「Recall」という一語は、実際には情報の種類ごと・ドメインごとに別の数字です。あるドメインで高くても、別のドメインにそのまま当てはめることはできません。多くの場合、当てはめれば下がります。
この事実は、製品を売る側にとっては不都合に見えるかもしれません。「どんな文書でも 0.9 です」と一言で言えたほうが楽だからです。
しかし、根拠なくそう言ってしまうことは、最初の章の「合成データで満点」と同じ過ちにつながります。
そこで、私たちは、(勇気をもって)言えることと言えないことの線を、はっきり引くことを選んでいます。
6. ドメインごとに、言える数字を増やしていく
では、「どんな文書でも高精度です」と胸を張るには、どうすればよいのでしょうか。答えは、残念ながら近道がありません。
ドメインごとに、その種類の文書での“物差し”を用意し、ひとつずつ 0.9 に到達させる。測っていないドメインは、名乗らない。
最終的に目指す姿は、「ドメイン × 情報の種類」のマトリクスが、すべて目標値を満たし、かつ各マスに十分なサンプルと信頼区間が伴っている状態です。
このとき大切なのは、各ドメインで同じループを愚直に回すことです。
- そのドメインの文書に、人手で個人情報をもれなく印付けした評価データ(正解)を用意する
- 検出器を当てて、信頼区間つきで精度を測る
- 取りこぼし・取りすぎを種類別に分解して、原因に応じて作り込みを足す
- もう一度測る。このとき、ほかのドメインの精度を下げていないか(デグレしていないか)も必ず確認する
特に3番目と4番目が地味で重要です。
「全体で 0.9」ではなく、「どの種類で取りこぼしているのか」を分解しないと、改善の打ち手が決まりません。
そして、あるドメインを良くする変更が別のドメインを悪化させることは日常的に起きるため、改善のたびに過去の評価をすべて回し直して、後退がないことを確認する仕組みが要ります。
7. 「代表性が強い」と言うための論拠
評価データが「現実をちゃんと代表している」と主張するには、勘ではなく、集め方と数字の作り方で裏づける必要があります。
私たちが使っているチェックリストを、理由つきでご紹介します
- 母集団を定義する
そもそも「何を代表したいのか」を先に決める。範囲が曖昧なまま「代表的」とは言えません。 - 無作為(できれば層化)抽出
対象全体からランダムに選ぶ。種類ごとに割り当てて偏りを防ぐ「層化」を併用するとさらに良い。恣意的に選んだ評価データでは、どれだけ数字が良くても代表性は主張できません。 - 分布の一致を示す
評価データの内訳(文書の種類・長さ・情報の種類の比率)が母集団と近いことを数字で示す。 - 十分なサンプル数
信頼区間が実用的な幅に収まるだけの量を確保する。とくに出現頻度の低い種類の情報は、専用に多めに集める必要があります。 - リークがないこと
評価に使うデータを、検出器の調整や学習に使っていないこと。これを破ると「答えを知っている問題」を解くことになり、数字が楽観的に出ます。 - 時間的なホールドアウト
仕組みを作った後の、新しい文書で測る。過去に最適化した結果を、未来のデータで検証する形にします。 - 指標と正解を事前に固定
評価に合わせて後から条件をいじらない
(いわゆる「のぞき見」をしない)。 - 正解そのものの信頼性
複数人での印付けの一致度を確認する。物差しが歪んでいては、その上の数字はすべて疑わしくなります。 - 安定性
サンプルを足しても数字が大きく動かないことを確認する
(次章の評価曲線)。 - 別のサンプルで再現
独立にもう一組を用意し、同じ数字が出ることを確かめる。
これがいちばん強い証拠です。
これらをどこまで満たしているかを正直に開示することこそが、「代表性が強い」という主張の中身です。
逆に言えば、これらに触れずに出された精度の数字は、額面どおりには受け取れない、ということでもあります。
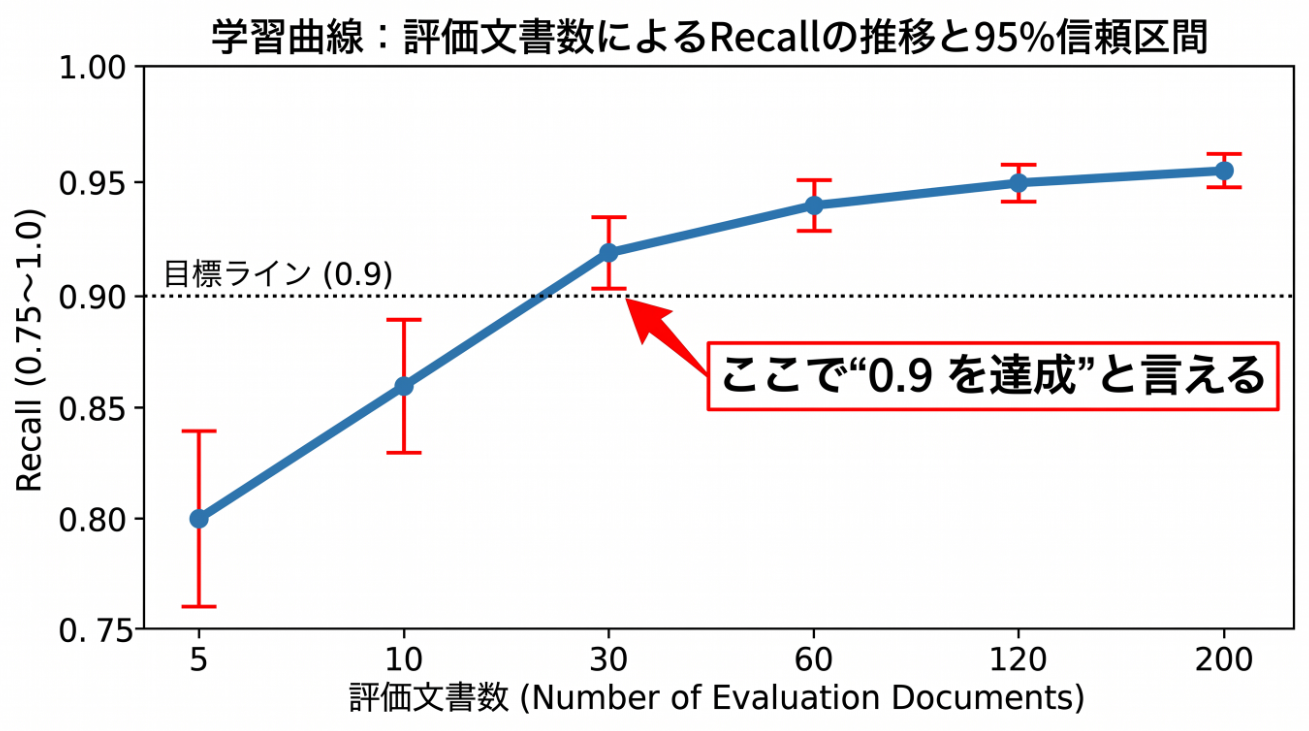
8. 評価曲線:「もう十分測れた」を、勘ではなく曲線で判断する
「何件評価すれば、その数字を信じてよいのか?」
この問いに、私たちは評価曲線で答えます。
評価データを少しずつ増やしながら、Recall の点推定と信頼区間を記録していくのです。
下表は、評価サンプルを増やすと推定値と信頼区間がどう動くかを示すための説明用の例示値です。実測ログそのものではなく、傾向を分かりやすくするために値を整えています
(実データでは n=120 と n=200 の点推定がここまできれいに一致することはまずありません)
| 評価文書数 | 評価対象スパン数 | Recall(点推定) | 95%信頼区間 | 区間の半幅 |
|---|---|---|---|---|
| 5 | 約60 | 0.88 | 0.78 – 0.94 | ±0.080 |
| 10 | 約120 | 0.90 | 0.84 – 0.95 | ±0.055 |
| 30 | 約360 | 0.93 | 0.90 – 0.95 | ±0.027 |
| 60 | 約720 | 0.95 | 0.93 – 0.96 | ±0.017 |
| 120 | 約1,440 | 0.955 | 0.947 – 0.963 | ±0.008 |
| 200 | 約2,400 | 0.955 | 0.949 – 0.961 | ±0.006 |
ポイントは3つあります。
- 点推定が落ち着いていく
少数のうちは上下に振れますが、増やすにつれて一定の値へ収束します。最初の 0.88 と、十分集めた後の 0.955 は、どちらも「同じ検出器の Recall」ですが、信用度がまったく違います。 - 信頼区間が締まっていく
幅がどんどん狭くなり、やがて区間の下限そのものが目標ラインを超えます。上の表では、30件あたりで下限が 0.9 に到達しています。 - やがて頭打ちになる
120件と200件で点推定がほぼ動いていません。これは「このドメインについては、もう十分に測れた」というサインです。ここから先は、別のドメインへ投資したほうが効果的だと判断できます。
私たちは、点推定が 0.9 を超えた時点ではなく、信頼区間の下限が 0.9 を超えた時点を、そのドメインで「0.9 を達成した」と呼ぶことにしています。
これは保守的な基準ですが、個人情報という領域では、このくらい慎重でちょうどよいと考えています。
9. よくある落とし穴
最後に、私たちが実際につまずいた/よく見かける落とし穴を、いくつか共有いたします。
- 「水増し」された高スコア
似た正解を大量に並べた評価データは、実力以上の数字を出します。多様性のない評価は、評価とは言えません。 - 評価データのリーク
調整・学習に使った文書を評価にも使ってしまうと、暗記した答えを採点することになり、数字が現実離れします。 - 正解の質
人が印付けした「正解」自体に抜けや揺れがあると、検出器が正しく当てているのに「外れ」と数えてしまうことがあります。
物差しの品質管理は、検出器のチューニングと同じくらい重要です。 - 平均が隠す偏り
全体平均が高くても、特定の種類の情報だけ大きく取りこぼしていることがあります。種類別・ドメイン別に分解して見る習慣がないと、致命的な穴を見落とします。
10. まとめ:誠実な数字が、製品の信頼をつくる
さて、ここまでいろいろ見てきましたが、個人情報検出の精度について、私たちが社内で徹底している原則は、突き詰めるとシンプルです。
- 混同行列に立ち返り、何を TP/FP/FN と数えたかを明確にする。
- 測ったドメインだけを名乗る。
- 必ず信頼区間つきで語り、その下限で達成を判断する。
- 一つのドメインの数字を、ほかへ外挿しない。
高い数字を一度出すことより、その数字がどこまで信用できるかを、正直に示せることのほうが、結局は製品の信頼につながります。
「Recall 0.9」と書くなら、それは「どの種類の文書で・どう数えて・どれだけのデータで・どれだけの幅で」測ったものなのか
そこまで含めて語れて、はじめて意味を持ちます。
私たちはこの考え方で、ドメインをひとつずつ広げながら、地道に精度を積み上げています。
派手ではありませんが、日本語×個人情報(PII)・機密情報・要配慮個人情報というセンシティブな領域では、これがいちばん確かな道だと考えています。
ここまでお読みいただきありがとうございました。
また次回お会いしましょう!




