
LLM サービング効率化の為のPagedAttention

こんにちは、株式会社Qualitegプロダクト開発部です。
今日は 商用LLM サービングに欠かせない PagedAttention 技術をご紹介します
はじめに
PagedAttention は当社にとって非常に重要な技術です
PagedAttentionを活用するとLLMでの文章生成において GPUメモリの利用効率をあげ 、そのぶん単位GPUあたりの同時に捌けるリクエストを増やすことができます。
当社は「ChatStream」という商用のLLMサービングプラットフォームを開発・提供しているため、多ユーザーからの同時リクエストによる高負荷環境でのLLMサービング(文章生成の提供)は、ドドド真ん中の課題ということになります。
PagedAttention登場以前の従来の並列生成はKVキャッシュとよばれる”リクエストごとに発生する大きなGPUメモリ消費”との戦いでした。
(KVキャッシュは transfomerのmodelを生で叩くときに past_key_values として登場します)
つまりモデルのパラメータとは別に発生する推論時のメモリ消費です。
これが同時に捌けるリクエスト数の限界を決めており、リクエスト数の限界=推論時消費メモリがGPUの搭載メモリを超えないギリギリのラインで、この限界に達する前に、生成リクエストを別のGPUノードに負荷を転嫁する必要があります。このリクエスト数限界を押し上げることが1リクエスト当たり(もしくは1トークンあたり)の推論コストを下げることにつながります。
当社も独自の工夫により、多ユーザーアクセス時でも安定した並列生成を行っていましたが、今回ご紹介する PagedAttentionはさらに効率的かつ手法であると同時に、これを実装した vLLM というサービングエンジンは PagedAttention だけでなく、テンソル並列をつかった計算ノード横断のモデル並列技法も実装されており、商用推論環境のベースエンジンとして大変期待の高いものとなっております。
当社 ChatStream は従来型(※)の Transformer を使用した並列生成と、PagedAttentionを使用したより効率的な並列生成の両アルゴリズムをサポートし、高いカスタマイズ性と幅広いニーズと応えられるようにしています。
※従来型もサポートしている理由は、豊富なプリセットサンプリングアルゴリズムやオリジナルのサンプリングアルゴリズムの資産を生かせるためと、大容量メモリを搭載した最新GPUや高負荷ではないローカルLLMサーブの用途では従来型でも十分な性能を出せるためです。
PagedAttention の衝撃
昨年2023年の夏頃、今回ご紹介する論文「Efficient Memory Management for Large Language Model Serving with PagedAttention」およびvLLM というライブラリがリリースされ、「LLMサービング」の重要なブレイクスルーがありました。
論文はこちらです
https://arxiv.org/abs/2309.06180
本邦では発表当初はそれほど騒がれていなかった気がします(そもそも当社のようにLLMサービングを主力事業にしている会社が少ないせいかもしれません)が当社にとってはいろいろな意味で大きな衝撃でした。というのも当社技術陣もTransformersのKVキャッシュの素直すぎる実装は理解しやすい反面もう少し小賢くできそうだなと腕まくりしてしてたところ、いきなり100tハンマーでドーンとやられた感じでしたが、現在はPagedAttentionをベースとして、さらに効率的なLLMサービング手法を開発・試行しております。
本編
ということで、今回は、当社プロダクトにとってもとてもインパクトの強かった本論文について当社の課題意識も交えながらなるべく平易な言葉で解説したいとおもいます。
概要理解を重視するのであえてシンプル化して説明している部分がありますので、詳細を理解したい方は論文原典または vLLM リポジトリ(https://github.com/vllm-project/vllm)を参照されることをお薦めいたします。
(私自身、論文中でサラっと触れられている部分は、ソースコードを読み込むことで理解がだいぶ深まりました)
PagedAttention が解決する課題は一言で言うとなんなのか?
従来の課題
- その1:LLMの計算過程で過去の層の出力をキャッシュして計算を高速化するKVキャッシュというテクニックがある。LLMの計算において過去の計算結果を使いまわすことで計算は高速化できるが、従来の方式では、このKVキャッシュにつかうGPUメモリ(テンソル)はモデルが扱える「最大トークン数ぶん」の「連続した領域」を「 事前」にアサインしていた。
つまり、従来手法だとあるリクエストに対する文章生成において、本来そんなに消費する必要がないときも余分にメモリを確保していた。そのため、KVキャッシュがメモリを大量に使用し、推論のたびに大量の”ムダ”なメモリを消費していた。 - その2:また、LLMによる推論シーンでGPU本来の良さである、大量並列計算の恩恵を十分に受けるためのバッチ演算がうまく活用できなかった。(※)
※なぜ、そのような課題があったのかは記事内で解説します。
PagedAttentionによる課題の解決・改善
PagedAttentionは、上記課題をどう解決したかを完結に説明します
【その1の課題について】
- 1-1 従来「最大トークン数ぶん」確保したKVキャッシュ用のメモリを、PagedAttention は「必要なぶん」だけ確保するようにしました。
- 1-2 従来、KVキャッシュとして使用されるテンソルはGPUメモリの「連続した領域」に格納する必要だったが、PagedAttentionはKVキャッシュを「ブロック」に分割することで、連続したメモリ空間に配置する必要はなくなりました。
- 1-3 従来、KVキャッシュ用のメモリは、「事前」に確保していたため、LLMへのリクエストによっては結局つかわない余分なメモリが存在したが、PagedAttentionは「必要なタイミング」に応じてブロックを増減させることができるため、事前に確保する必要がなくなりました。
【その2の課題について】
- 2-1 従来のバッチ処理では、複数の文章を入力したときに、プロンプトとなるトークン列の長さをそろえる必要があるため、不要なパディングを発生させていたが、PagedAttention では、特別なGPUカーネルを導入し、入出力時のパディングを不要にした
- 2-2 従来はちょうど同時にリクエストされた場合以外は、次のリクエストが来ても前のリクエストが終わるまで待つ必要があったが、PagedAttentionではこの「リクエスト単位」の待ち合わせが「イテレーション単位」となり細やかにリクエストの出し入れができるようなることで、待ち時間が短縮される。
あまり一言でいえませんでしたが、ざっくりいうとこのような感じです。
自己回帰モデルの特徴と必要メモリ見積もりの難しさ
LLMは 自己回帰モデル(autoregressive model)であり、それまでに生成したトークン列(シーケンス)を再び入力することで新しいトークンを生成します。
これを繰り返しを英語では「イテレーション」といいますが、イテレーションによって目的の文章を生成していくわけですが、この繰り返される計算過程で、過去に計算した結果の再利用をすることで計算時間の短縮化をすることができます。このときにもちいられるのが KVキャッシュ です。シンプルにいうと、KVキャッシュはトークン数だけ準備されます。
ここで問題になるのは、自己回帰モデルの特徴でもありますが、文章生成を開始してから終わるまで、いったいどれだけイテレーションすればいいか事前にはわからないことです。
事前にわからないので、KVキャッシュに使うためのメモリは事前にどれだけ確保しておけばいいのだろう、という課題が発生します。
最もシンプルなのは、「そのモデルが扱える最大のトークンサイズ」を生成開始時点で確保してしまおう という作戦です。これを「素直実装」となづけましたが、実際にその作戦が実装されており、素直すぎるため、生成時に大量のKVキャッシュ用メモリを消費してしまいました。
実験室でやる程度なら、問題ありませんが、我々のように商用LLMのホスティングをする者としては大きな課題となる、というわけです。
PagedAttentionの理解を深める
さて、自己回帰モデルを思い出したところで、理解をふかめるために、具体例でみていきましょう。
1-1 従来「最大トークン数ぶん」確保したKVキャッシュ用のメモリを、PagedAttention は「必要なぶん」だけ確保するようにしました。
まず↑からみていきます。
ここでは GPT2 をベースにした日本語モデル rinna/japanese-gpt2-small をつかった文章生成、という具体例で確認していきましょう。
まず、 rinna/japanese-gpt2-small のコンテクストサイズをみてみましょう
以下のコードで確認します
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt2-small", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt2-small")
max_position_embeddings = model.config.max_position_embeddings
print("モデルのコンテクストサイズ(最大シーケンス長):", max_position_embeddings)
結果は 1024 でした。このモデルでは 1024トークンまで生成できることを示します。
このモデルで以下のような文章生成をします
「夏目漱石の代表作は」に続く文章を生成したとき「吾輩は猫である」を出力する例で考えてみます。
(実際には、GPT2ですので、こんなに都合よく出力してくれません)
このとき、「素直実装」では以下のようになります。

コンテクストサイズ1024ぶんだけメモリを確保したのに、たったの13トークンしか生成しなかったので、残りの1011トークンぶんの未使用=ムダが発生してしまいました。
実装で確認すると以下のようになります
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt2-small", use_fast=False)
tokenizer.do_lower_case = True
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt2-small")
device = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(device)
model.eval()
prompt = "夏目漱石の代表作は"
inputs = tokenizer(prompt, return_tensors='pt', padding=True).to(device)
input_ids = inputs['input_ids']
max_length = 20
outputs = input_ids.clone() # 入力IDをクローンして出力用に保存
use_cache = True # False にすると過去キャッシュが利用できなくなり、計算がおかしくなる
# 初回の出力生成とKVキャッシュ(past_key_values)の取得
out = model(input_ids=input_ids, use_cache=use_cache)
logits = out.logits
past_key_values = out.past_key_values # 初回の出力でKVキャッシュを取得
last_token_logits = logits[0, -1, :]
token_id = torch.argmax(last_token_logits).unsqueeze(0).unsqueeze(0) # スカラーを [1,1] テンソルに変換
outputs = torch.cat((outputs, token_id), dim=1)
# 2回目以降の出力生成。KVキャッシュ(past_key_values)を利用した生成とKVキャッシュの更新
for idx_itor in range(1, max_length):
out = model(input_ids=token_id, past_key_values=past_key_values, use_cache=use_cache)
logits = out.logits
past_key_values = out.past_key_values # pase_key_values を明示的に更新。モデルによっては明示更新しなくても内部で更新されるものもある。
last_token_logits = logits[0, -1, :]
token_id = torch.argmax(last_token_logits).unsqueeze(0).unsqueeze(0) # スカラーを [1,1] テンソルに変換
outputs = torch.cat((outputs, token_id), dim=1) # outputsに新しいトークンIDを追加
# 生成された文章の表示
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"{generated_text}")
以下で use_cache = True にすることで、KVキャッシュを残すように動作します。
out = model(input_ids=input_ids, use_cache=use_cache)
さらに、
past_key_values = out.past_key_values
で、KVキャッシュを取り出せます。
out = model(input_ids=token_id, past_key_values=past_key_values,
↑は2回目以降の生成です。ここで引数に past_key_values を渡し、それまでの計算結果を渡すことで、その分の計算コストを省略し、新たなトークン入力による影響分だけの計算コストで済みます。よって、ここでは新たなトークン token_id のみを入力しています。
ちなみに、サンプリングはシンプルに argmax をとっています
token_id = torch.argmax(last_token_logits)
さて、これは HuggingFace transformer での実行ですが、果たして本当に、論文の提起通りに最初の入力時点でメモリをコンテクストサイズまで拡張して確保しているかというと、答えは「NO」です。
実際には、シーケンスが長くなるにつれ、使用メモリが増えていくようになっています。
1-2 従来、KVキャッシュとして使用されるテンソルはGPUメモリの「連続した領域」に格納する必要だったが、PagedAttentionはKVキャッシュを「ブロック」に分割することで、連続したメモリ空間に配置する必要はなくなりました。
↑について、
従来の実装ではKVキャッシュのテンソルデータを「普通に」確保していますので、 PytorchテンソルをそのままKVキャッシュの大きさで確保・使用することになります。すると必然的にGPUのメモリ空間にシーケンシャルにテンソルデータが配置され、以下の Beforeのような形となります。一方提案手法では、あらかじめKVキャッシュを以下のAfterのように、ブロック化することで、GPU内のメモリに連続的に配置しなければいけない制約から逃れることができました。

(ただし、ブロックサイズが大きすぎると結局同じ問題=断片化が発生するのでブロックサイズは16~256程度が良いとされています)
この点について、HuggingFaceのtransformers の実装はどうでしょうか。
この点についてはtransformeres のKVキャッシュは依然として通常の Pytorchテンソルなので、GPUの連続したメモリ領域が抑えられてしまう、という点では「YES」です。
( transformers ほか、推論のエンジンとなる部分の実装は日々進化しており、明らかな問題が放置されることはありません。ライブラリがどの程度進化したかを理解するには常に最新をコードレベルでキャッチアップしておくのが吉だとおもいます)
1-3 従来、KVキャッシュ用のメモリは、「事前」に確保していたため、LLMへのリクエストによっては結局つかわない余分なメモリが存在したが、PagedAttentionは「必要なタイミング」に応じてブロックを増減させることができるため、事前に確保する必要がなくなりました。
↑については、これまでの説明に含まれていますので追加の説明は割愛します。
ブロックには論理ブロックと物理ブロックがあり、両者はブロックテーブルでひもづける
もう1つテクニカルな点を説明しておきますと、ブロック化についての設計では、いきなりGPUメモリにブロックを置くのではなく、いったん論理ブロックで抽象化しておき、論理ブロック単位でシーケンスを復活・ブロック化し、実際の保存先は物理ブロック単位でGPUメモリに保存するアプローチをとっています。論理ブロックと物理ブロックのひもづけたブロックテーブルで行います。データベースのクロスリファレンスのような位置づけですね。
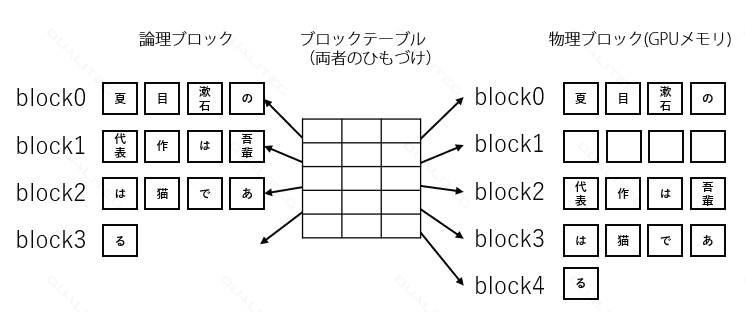
次は、課題その2のほうをみていきましょう
【その2の課題について】
2-1 従来のバッチ処理では、複数の文章を入力したときに、プロンプトとなるトークン列の長さをそろえる必要があるため、不要なパディングを発生させていたが、PagedAttention では、特別なGPUカーネルを導入し、入出力時のパディングを不要にした
2-2 従来はちょうど同時にリクエストされた場合以外は、次のリクエストが来ても前のリクエストが終わるまで待つ必要があったが、PagedAttentionではこの「リクエスト単位」の待ち合わせが「イテレーション単位」となり細やかにリクエストの出し入れができるようなることで、待ち時間が短縮される。
こちらについては、まず2-1からみていきます。
LLMサービングとバッチ処理
まず、LLMサービングにおいてGPUのバッチ演算はなぜうまく機能しないのかを考えてみましょう。
それを考えるために、まず、GPUにLLMのforward計算(つまり推論)するときのバッチ処理のおさらいをしておきましょう。
バッチ処理はすなわち、入力トークンリストを束(バッチ)にして計算し、出力トークンリストの束として出力します。
理解を深めるために、ここでも、実際の例で考えてみます。
バッチ処理の問題その1:パディングの問題
さきほどと同様、LLMに「夏目漱石の代表的な作品は」を入力したときに
出力が「吾輩は猫である」となるシーンで考えます。
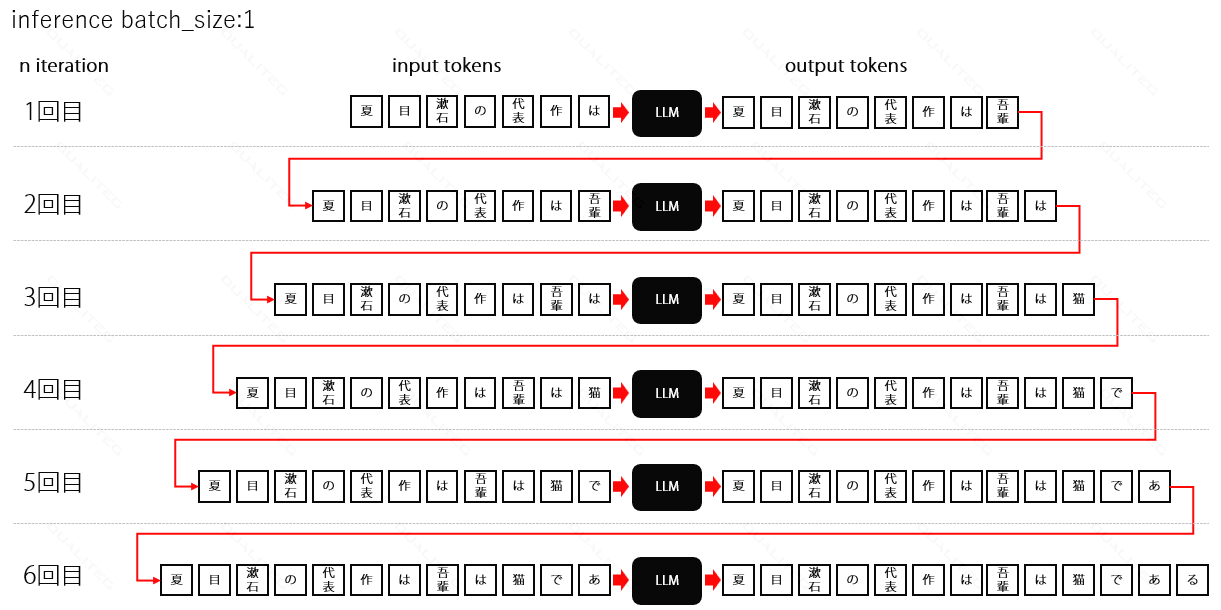
バッチでないシングル入力だと以下のようなイメージです
(模式図のため特殊文字や終端トークンは省きます)

「夏目漱石の代表作は?」 がトークナイズされLLMに入力された後、出力として(入力プロンプトも含め)「吾輩は猫である」が応答されます。
1~6の数字は生成イテレーションで6回のイテレーションで6トークンを生成し「吾輩は猫である」を得ています。
バッチサイズ1での生成イテレーションを模式的にあらわすと以下の図のようになります。
transformers でこれを書くと以下のようになります
import torch
# モデルとトークナイザーのロード
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt2-small", use_fast=False)
tokenizer.do_lower_case = True
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt2-small")
if torch.cuda.is_available():
model = model.to("cuda")
model.eval()
prompts = ["夏目漱石の代表作は"]
inputs = tokenizer(prompts, return_tensors='pt', padding=True).to(model.device)
outputs = inputs.input_ids
max_length = 20
for _ in range(max_length):
with torch.no_grad():
outputs_logit = model(input_ids=outputs)
next_token_logits = outputs_logit.logits[:, -1, :] # モデル出力から、最後のトークン位置のロジットを取得
next_tokens = torch.argmax(next_token_logits, dim=-1, keepdim=True) # もっとも確率の高いものをとるシンプルなサンプリング
outputs = torch.cat([outputs, next_tokens], dim=-1) # 出力にトークンを追加
# 生成された文章の表示
for i, output in enumerate(outputs):
print(f"{i + 1}: {tokenizer.decode(output, skip_special_tokens=True)}")
バッチ入力の場合はどうなるでしょう
LLMのバッチ入力とは、すなわちに、一回のリクエストで複数の文章を並列に生成することができます。
以下の2つの生成を同時にやることを考えます。
- 「夏目漱石の代表作は」→「吾輩は猫である」
- 「君達は」→「どう生きるか」
これを図にしてみると、以下のようになります
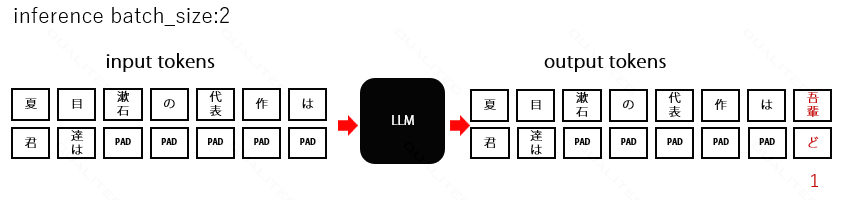
ここに PAD が登場しているのがわかります。
図のように、2つのプロンプトのサイズ(入力トークンサイズ)をそろえる必要がありますが、このとき、「君達は」のほうに足りないトークン数分を埋めていく処理をパディングといいます。このパディングがムダだよね、という指摘が2-1 の課題意識でした。
(上記コードでは端折りましたが、アテンションマスクを明示的に指定することで、パディング部分を意図的に無視することは可能です)
バッチ処理の問題その2 タイミング問題
もう1つの指摘は、LLMサービングの実際を考えたとき、同じタイミングでちょうどよく文章生成のリクエストが来ることはあるでしょうか。
最も理想的(GPU的に効率的に計算ができて各ユーザーへの応答がはやい)なのは、ちょうど同時リクエストがあって、バッチ生成ができるときです。
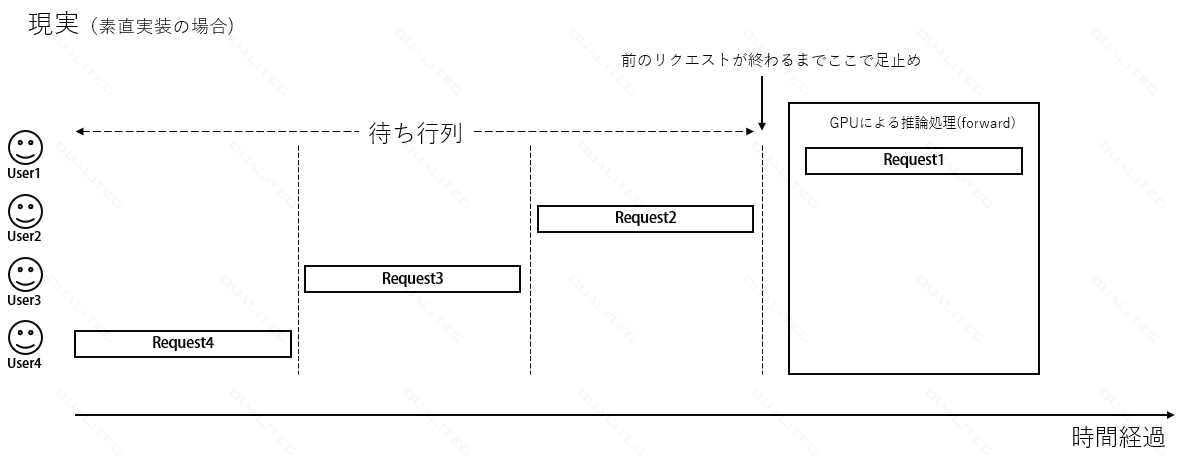
以下は、4人のユーザーがちょうど同じタイミングにリクエストを送信してきた場合です。GPUはバッチサイズ4で生成処理をしています。右にむかって時間が経過していきます。
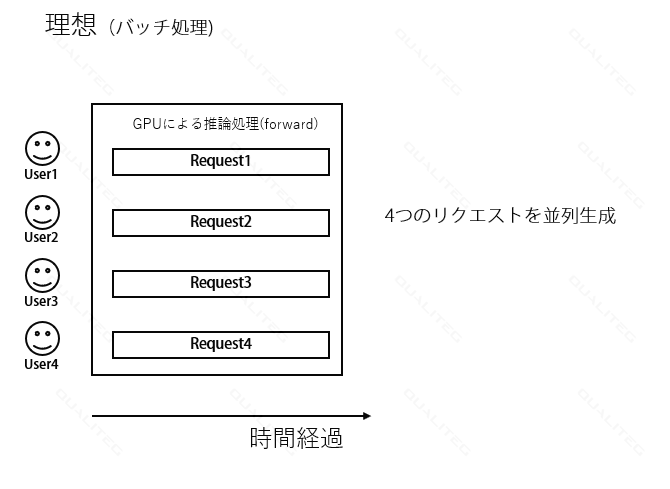
バッチ推論なので、大変GPU的にもUX的にも都合がいいですが、ここまで都合がよいのはよほどの多ユーザー同時アクセスなとき以外、ほぼ発生しません。
つまり、通常、中程度の同時アクセス時が多く、リクエストの処理タイミングが完全一致することはありません。
その場合、「素直に」実装するとリクエストのタイミングがズレたら、あるリクエストをさばいているときには別のリクエストには待ってもらう必要があります。
以下は Request1の生成処理をシングル(バッチサイズ1)で行っている様子です。User1は生成出力を得られますが、User2~User4は自分のRequestが処理されるまで待ちぼうけです。(もちろんシングルGPUに話をシンプル化している為です)
(株)Qualiteg の ChatStreamの従来アプローチ
ここでちょっとだけこの課題に対する当社アプローチをご紹介します。
この課題に対して当社の ChatStream では、以下の点に着目し、同時アクセス処理の効率化を図っていました。
- リクエストをイテレーション単位に分割
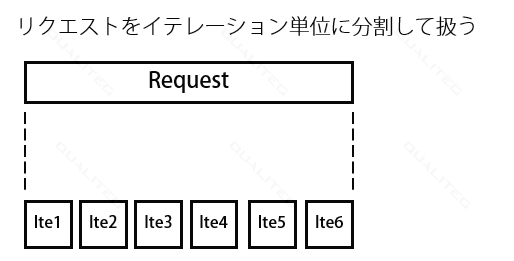
- シングルバッチだがイテレーション単位で他リクエストの割り込みを認める
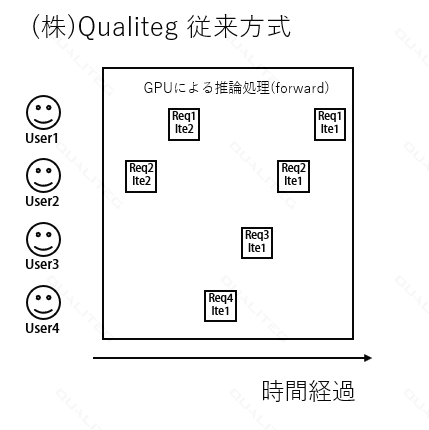
これにより、リクエストの長さは関係なく、現在変換中のリクエスト数とメモリ使用量を監視・制御することで同時アクセスへの対応を行っていました。
この手法は Qualiteg classic hf-transformer = QCHT と呼んでいます。
これにより同時アクセス性は高まり、応答性もあがりましたが、課題もありました。それは、やはりKVキャッシュの問題です。この方式も結局リクエストにより生成されるシーケンスが長くなればなるほど、それだけ多くのメモリを使用することになります。
当然ながらメモリを使いすぎると、処理が落ちてしまうので、ある程度安全なレベルまでしかメモリを消費させないようにしなければいけません。
このとき、メモリの見積もりを保守的にやる場合、モデルのコンテクストサイズまたは、アプリで決めた最大コンテクストサイズを上限として、1リクエストにたいして、最大コンテクストサイズ(シーケンス長)使用されても良いメモリ量を見積もる手法が考えられます。
この場合、
GPU総メモリ量=モデルデータそのものが占有するメモリ量+同時ユーザー数×最大コンテクストサイズ×1トークンあたりのKVキャッシュメモリ量+そのほかのメモリ量 となります。
いったん、その他のメモリ量を忘れると、
GPU総メモリ量=モデルデータそのものが占有するメモリ量+同時ユーザー数×最大コンテクストサイズ×1トークンあたりのKVキャッシュメモリ量
で計算できます。
実際の値の計算方法を別の記事で説明しようとおもいますが、この手法だと、大きなGPUメモリに小さなパラメータサイズのモデルをのせないかぎり同時ユーザー数を稼げないという問題が発生します。
そこで、当社では以下の方法をハイブリッドで使用していました。
- 最低確保メモリ量を決める
- 生成中のメモリ量を監視し、規定量に達した場合、リクエスト受付を停止する(※)
- 生成条件(アクセス時間、トークン数など入力データのプライバシーによらないもの)をもとに、統計処理および機械学習処理をおこない、1.最低確保メモリ量を更新する。
※リクエスト受付を停止した場合、商用環境では別のLLMサービングノードにリクエストが割り振られます。すべてのサービングノードを使い切った場合は、待ち行列に入ります。待ち行列もいっぱいになった場合は too many requests になります。つまりこの取り組みは、いかに、少ないサービングノードで too many requests にならないようにするかが、私たちの腕の見せ所です!
提案手法によるバッチ化問題の解決法
提案手法についてもリクエスト単位処理をイテレーション単位処理について言及されております。その解決法の具体的なアプローチは GPUカーネルの処理になりますので、カーネルの特殊処理お説明は本稿ではスキップとさせていただきますが、どの程度スループットが向上するのかはまた記事をあらためて書きたいとおもいます。
まとめ
PagedAttention の考え方について簡単にご紹介、ご説明いたしました。
当社含め、LLMサービングの新技術は日々開発されており、進化も早いですが、今回ご紹介した PagedAttention は論文やサンプルコードだけでなく、商用環境でも採用が始まっている高性能な vLLM という実装として公開されている点が大きな意義ではないでしょうか。
今回、当社の LLM サービング技術も少しご紹介したしましたが、 PagedAttentionで前進したLLMサービング技術に加え、さらに効率的なGPU運用に結び付けていく予定です。
PagedAttentionはKVキャッシュの効率的な運用にフォーカスしていますが、vLLM はそれだけでなく、モデル並列など大規模LLMサービングを意識した昨日を多くもサポートしているためこれからますますエンジンとしての利用が広がっていくとおもいます。



