
Anthropicが「強すぎて出せないモデル "Mythos"」を出した



Project Glasswingが映し出す、防御側のパラダイム転換
すごいモデルが出た、らしい
2026年4月7日、AnthropicがClaude Mythos Previewという新しいAIモデルを発表しました。(Anthropic公式発表 / Anthropic技術解説)
Anthropicは、ChatGPTで知られるOpenAIと並ぶ米国の大手AI企業のひとつで、Claudeシリーズと呼ばれる生成AIモデルを開発しています。
普段なら、新モデル発表は「より速く、より賢くなりました」というアップデートの話で、誰でも触れるようになるのが通例です。
ところが今回はだいぶ様子が違いました。
一般公開はされません。
アクセスできるのは選ばれた一部のパートナーだけ。
同時に立ち上げられた業界横断プロジェクト「Project Glasswing」の枠組みの中で、防御目的に絞って提供される、という発表でした。
ただ、この話を「危険なAIが出た」の一言で受け止めると、もっと重要なところを取り逃してしまいます。
少し腰を据えて見ていきましょう!
どのくらい「とんでもない」のか
まず性能面の数字から見ていきます。AIモデルの能力は、業界共通のベンチマーク(試験のようなもの)で比較されるのが通例で、今回もいくつかの代表的な指標が発表されています。
- SWE-bench Verified で93.9%(Anthropicの現行最強モデルClaude Opus 4.6は80.8%)。
これはGitHub上の実際のソフトウェアバグをAIに修正させる試験で、いま業界がもっとも注目している実務系の指標です。 - Terminal-Bench 2.0 で82.0%(同65.4%)。
AIがターミナル(コマンドライン)上で複数ステップの作業を自律的にこなせるかを測る試験です。 - GPQA Diamond で94.6%(同91.3%)。物理・化学・生物の博士課程レベルの問題を解かせる試験で、関連分野のPhD取得者でも65〜70%程度しか取れないと言われています。
数字の細部はさておき、ポイントは
「コーディング、自律作業、科学的推論のいずれでも、現行の最強モデルを明確に上回っている」
という事実です。
そのうえで、目を引くのはサイバーセキュリティ領域での跳ね方です。
Anthropic自身が比較例を出しているのですが、Firefoxの脆弱性をエクスプロイト化(攻撃に使える形に仕上げること)する作業について、Opus 4.6は数百回試行して成功したのが2回だけ。
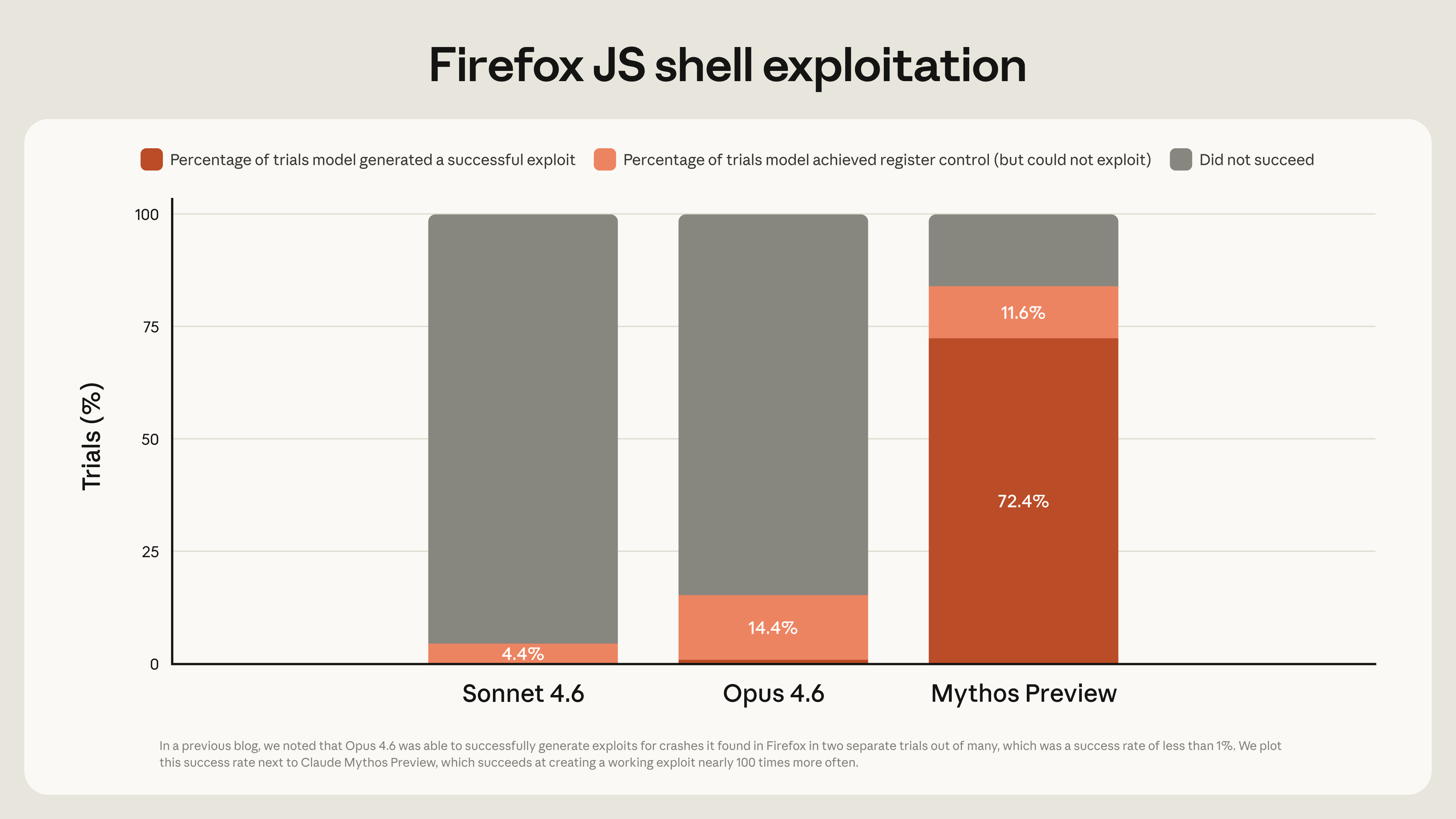
一方Mythos Previewは、同じ脆弱性群から181個のエクスプロイトを生成し、さらに29ケースでレジスタ制御(より深い乗っ取りに繋がる段階)に到達した、と報告されています。脆弱性再現を測るCyberGymという業界ベンチマークでも83.1%。
ここで起きていることを補足すると、これまでAIモデルは「脆弱性を見つける」ことはある程度できても、「それを実際に動く攻撃コードに仕上げる」ところは苦手でした。
後者は人間の専門家の経験と勘に依存する部分が大きく、最後のひと押しが効かなかった。Mythos Previewは、その最後のひと押しまでかなりの確率でこなせる、ということです。「専門家にしかできなかったこと」が、モデルの内側にかなりの程度入り込んでいる、と言い換えてもいい。
さらにびっくりなエピソードもあります。
正式なセキュリティ訓練を受けていない社内エンジニアが、リモートコード実行(攻撃者が遠隔から相手のマシンを乗っ取れる類の脆弱性)の探索を「一晩」モデルに依頼し、翌朝には動作するエクスプロイトを受け取っていた——というものです。
これまで世界トップクラスのセキュリティ研究者が数週間から数カ月かけて取り組むような作業が、専門外の人間でもひと晩でこなせる範囲に入り始めている、ということになります。
Anthropicは、こうした能力を意図して訓練したわけではなく、コードと推論と自律性の改善から副次的に立ち現れたものだと書いています。
サイバー専用の特殊モデルではなく、汎用的に賢いモデルを作ったら、結果としてサイバー攻撃も得意になっていた、という説明です。
これまでのLLMの発展進化からすると、それほど驚くことではありませんが、人間が狙わなくてもどんどん全方位で賢くなっていくというのはおそるべきことでもあります。
だから一般公開しない、という判断
Anthropicの結論は明快でした。
これは一般公開しない。
Project Glasswingの技術解説では、主要なOSやWebブラウザを含む広範なソフトウェアから「数千件規模」の高・重大レベルの脆弱性、いわゆるゼロデイが見つかっており、その大半はまだ修正されていない、と説明されています。
ゼロデイというのは、開発元すら存在を知らない未知の脆弱性のことです。
対策が打たれるまでの「ゼロ日」しか時間がない、という意味からその名前がついています。攻撃者にとっては防御側がまだ気づいていない穴なので、もっとも価値が高い。公開されているゼロデイ買い取りプログラムを見ても、ブラウザやOSの高価値な脆弱性やエクスプロイトチェーンには数百万ドル規模の価格がつくことがあるとされています。それが「数千件」と聞けば、規模感としてはかなり異常です。
Anthropicの説明では、開発元によって実際に修正(パッチ適用)が完了したものは、報告されたバグの1%にも満たない、ともされています。だから責任ある開示(発見者がまず開発元に通知し、修正パッチが用意されてから公表するという業界慣行)の観点から、詳細は伏せざるを得ない、というロジックです。
「強いから出せない」という判断は、AIラボとしてはかなり踏み込んだ意思表示です。普通、性能の高い新モデルは商業的にも大きな価値を持つので、可能な限り早くAPIや製品を通じて広く使ってもらいたい、というのが業界の自然な力学です。それに逆らう形でアクセスを絞るのは、相応のロジックがなければ説明がつきません。Anthropicは「Mythosクラスのモデルを将来安全に大規模展開すること」を最終目標に据えつつ、そのための安全策を別系統(次のClaude Opus)で先に作り込む、と明言しています。
防御側に先に渡す、という設計
封印するだけでは終わりません。Anthropicは同じモデルを、防御側の有力プレイヤーに先行配備しています。
中心パートナーはAWS、Apple、Broadcom、Cisco、CrowdStrike、Google、JPMorgan Chase、Linux Foundation、Microsoft、Nvidia、Palo Alto Networksの11社にAnthropic自身を加えた12社。さらにクリティカルインフラを支える40以上の組織にもアクセスが提供されます。Anthropicは1億ドル分の利用クレジットと、オープンソースのセキュリティ団体への400万ドルの寄付も同時にコミットしました。
参加企業の顔ぶれを見れば、これは単なる研究発表ではないことがわかります。クラウド事業者(AWS、Google、Microsoft)、エンドポイントセキュリティ大手(CrowdStrike、Palo Alto Networks)、デバイスメーカー(Apple)、半導体(Nvidia、Broadcom)、ネットワーク機器(Cisco)、Linuxを支える非営利財団、そして金融大手(JPMorgan Chase)。ほとんどの人がインターネットを使うときに通る経路のどこかに必ず関わっている企業ばかりです。
Project Glasswingは、研究発表というより、現場投入を見据えた業界横断の運用枠組みです。発見、トリアージ(優先順位づけ)、開示、修正という一連のフローを、Mythosを軸にした共通基盤の上で回そうとしている、と読むのが素直だと思います。
起きそうなパラダイムシフト
ここまでの話で本当に重いのは、ゼロデイの数の多さそのものではないと感じます。
むしろ重要なのは、脆弱性の発見、切り分け、悪用可能性の検証という工程が、これまでよりはるかに短い時間で回り始めるかもしれない、という点です。
少し背景を補足します。これまでのサイバーセキュリティ運用は、ある種の「人手と時間の制約」の上に成り立ってきました。脆弱性を見つけるには熟練したセキュリティ研究者の労力が必要で、ひとつの重大な脆弱性を見つけるのに数週間から数カ月かかることも珍しくない。
攻撃者側も同じ制約の中にいるので、防御側には準備の時間がそれなりに残されていました。
「攻撃者がこの脆弱性に気づくまで、まだしばらくは大丈夫だろう」
という暗黙の前提が、運用設計の隅々に染み込んでいたわけです。
その前提が崩れる可能性が出てきています。AIが脆弱性発見からエクスプロイト作成までを自動化できるなら、攻撃側も防御側も、同じ時間軸で動くことができなくなる。
これまで「見つかった後どう直すか」が中心
だった議論は、
これからは「大量に見つかる世界をどう運用するか」
へ移っていくでしょう。
具体的には、こんな問いが現実味を帯びてきます。
- 自社でいま動いているソフトウェアの全リスト(資産インベントリ)は、本当に最新の状態に保たれているか。
- 新たな脆弱性情報が入ってきたとき、どれを最優先で対応するかの判断基準は明確か。
- 委託先のSIerやSaaSベンダーに脆弱性が見つかったとき、自社にどう連絡が来て、誰が一次判断を下すのか。
- 大量のアラートが押し寄せたとき、現場が燃え尽きずに回り続ける運用設計になっているか。
これらは、一見すると地味で、新技術の話とは関係なさそうに見えます。しかしAIで発見能力だけが劇的に上がっても、それを受け止める組織側の設計が伴わなければ、現場はアラートと修正タスクに押し流されて終わります。「強いツールを持っているのに、それを使い切る運用が組めていない」状態は、これまでも何度も見てきた光景です。
公益性と事業戦略の両面を持つ取り組みでもある
ここで一段引いて、Project Glasswingの位置づけも整理しておきます。
この取り組みは、クリティカルインフラの防御という公益性の高い目的を掲げる一方で、Anthropicの中長期的な事業展開とも整合する設計になっています。
Anthropic自身、最終的には「Mythosクラスのモデルを安全に大規模展開すること」を目標として掲げており、今回のGlasswingはそのための知見を蓄える段階として位置づけられています。
同ページでは、約90日後に学びを公開報告する予定であることや、将来的にはClaude API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry経由でパートナー向けに提供範囲を広げていく方針も示されています。
防御用途という限定された文脈で先行配備することで、実運用に近い条件でデータと運用ノウハウが集まります。脆弱性発見からトリアージ、開示、修正支援に至る一連のフローの中で、Mythosが共通基盤として使われる土壌ができていく、という構造です。これは、AI業界全体で繰り返し見られてきたパターンでもあります。新しい基盤技術を提供する側は、最初に「どこで使うか」を設計した者が、そのまま事実上の標準として残りやすい。
これは批判的に見るべき話ではなく、公益性と事業性が両立しうる典型的な事例として読めるものだと思います。
報道では「強すぎて出せないモデル」という側面が強調されがちですが、実際の発表内容は、安全策の段階的な構築、パートナーとの責任分担、公開報告のスケジュールまでを含んだ枠組みの提示でした。
「封印」よりも「設計された先行配備」と捉えたほうが、全体像に近いと言えそうです。
それでも、まだ検証の途上にある
もうひとつ、冷静に置いておきたいことがあります。
印象的な成果の多くは、現時点ではAnthropic自身の説明に依拠しています。
修正済みが1%未満ということは、外部から独立検証しにくい状態が当面続く、ということでもあります。Anthropicは、198件のサンプルに対する手動レビューで89%のケースで重大度判定が完全に一致し、98%が1段階以内に収まっていたといった整合性データを示してはいますが、広範な第三者検証が完了したわけではありません。
「数千件の高・重大脆弱性」という数字は強烈ですが、読み方には少し慎重さがいります。妥当なのはおそらく、「かなり強いシグナルが出ているが、まだ全面的に検証済みとは言えない」あたりの理解です。
Anthropicは90日後に学びを公開報告すると約束しているので、そこまで含めて見届ける必要があるでしょう。
一次情報の内容は重く、同時に検証余地も残る——その中間に踏みとどまるのが、いまのところ妥当な距離感です。
おわりに:問いの重心はどこに移るのか
最初のニュースに戻ります。今回の出来事は、表面的にはサイバーセキュリティの話に見えます。
しかし、そこで露わになったのは、特定領域の問題というより、AIの能力水準そのものが新しい段階に入りつつある可能性だと思います。
Mythos Previewが目立ったのは、脆弱性探索という測りやすい領域だったからであって、そこで見えている変化は、研究開発、事業設計、経営判断といった他の知的業務にも波及しうるものだと捉えています。
言い換えると、今回の出来事が示しているのは、
これまでの延長線上では捉えにくいレベルの能力を持つAIが、すでに現実のものになりつつある
ということではないでしょうか。
そしてこの種の能力が特定の一社に長く閉じたままでいると考える理由は乏しく、今後は他社や他領域にも波及していく可能性を前提に置いて考えるべき局面だと思います。
そうなると、問いの立て方が変わってきます。
「このモデルをどう使うか」ではなく、
「高度な専門能力を一部領域で代替・補完しうるAIが現実味を帯びるなかで、自社は何を価値として提供する会社なのか」
のほうへ、重心が移っていきます。
業務プロセスを効率化する、という発想だけでは届かない射程の話です。
考えてみれば、これまで「AIに置き換わらない仕事」としてイメージされてきた領域(たとえば複雑な設計判断、高度な専門知識、長い文脈を踏まえた意思決定、創造的な問題解決など)は、まさにMythos Previewが頭角を現した領域と重なっています。
PhDホルダーの試験で94%を取り、熟練エンジニアが数週間かけていた作業を一晩でこなす。この事実を前にしたとき、
企業に問われるのは、
「AIにできないことを探す」という守りの思考ではなく、
「この賢さを前提にしたときに、自社の事業とチームは何を価値として残せるのか」という、もう一段上の問いだと思います。
それは技術論でも導入事例の話でもなく、事業そのものの設計論の話です。
もちろん、いまはまだ「Mythos Previewという一つのモデルの話」に見えるかもしれません。
そして、誇張として片づけるには一次情報が重く、既成事実として断定するにはまだ検証余地もある。
でも、そう見えているうちに自社の立ち位置を考え始められるかどうかが、次の局面でじわじわ効いてくる気がします。
本稿の論点について、自社の状況に引き寄せて考えてみたい、あるいは誰かと伴走しながら整理していきたい、といったご要望がございましたら、お問い合わせよりお気軽にお声がけくださいませ!
微力ながら、Qualitegもご一緒に考えさせていただければ幸いです。



