
chatstream.net のクエリパラメータ仕様
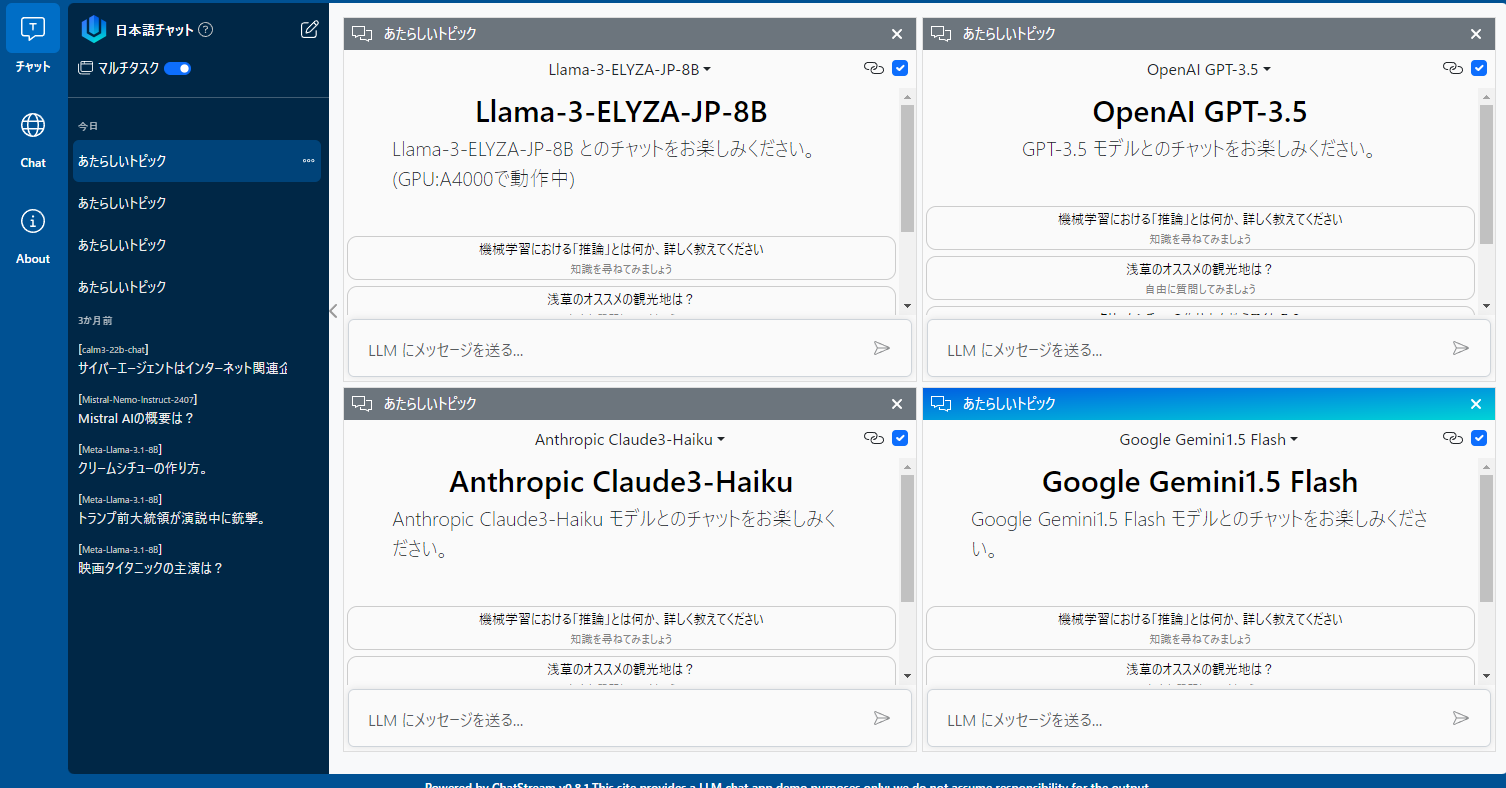
chatstream.net は(株)Qualiteg が運用するサービスで、世界中で公開されている最新のLLMをいちはやく体験することができます。
特定の LLM を開いてじっくりチャットをしたり、複数のLLM を開いて協調的につかってみたり、LLM同士で出力を比較させたり、LLMのもつポテンシャルを感じていただけるようになっています。
たとえば、PCブラウザでURLを開くと、4つのLLMを同時に開いて、同時にチャットを行うことができます。このようにお好みに応じてチャットを制御することができるのがURLパラメータです。
URLパラメータ
chatstream.net の動作はURLパラメータである程度制御することが可能です。
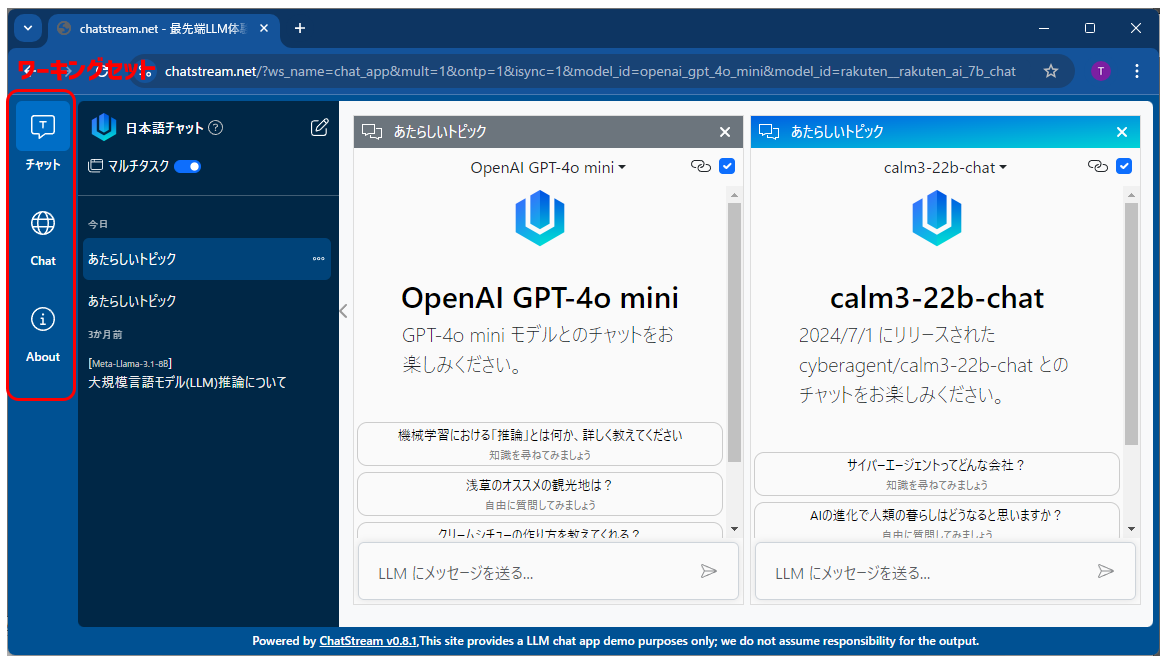
URLパラメータとは https://chatstream.net の後に ? を付与して例えば https://chatstream.net?model_id=openai_gpt_4o_mini のように ? につづいて キー=値 のようなクエリ文字列を指定することで chatstream.net のお好みに応じて制御することができます。
パラメータ一覧
【ws_name】
自動で選択状態にしたいワーキングセット名を指定します。
ws_name="chat_app"
ワーキングセットは、PC画面では左端(スマホでは下端)に表示されるボタンで切り替えることのできる作業単位です。現在は "chat_app","chat_app_en" を指定することができます。
【mult】
multi_topic_mode をあらわすクエリパラメータです。
mult=1
mult=1 を指定すると、マルチトピックモードとなり、PCで使用するときに、複数のLLMチャットを同時に開くことのできるモードになります。
(例)
mult=1 マルチトピックモード
mult=0 シングルトピックモード
mult無指定 デフォルト設定またはユーザーの記録
【ontp】
open_new_topic をあらわすクエリパラメータです。
新規トピックとして開きます。
ontp=1
(例)
ontp=1 自動的に新しいトピックを開く
ontp=0 (デフォルトに従う)
ontp無指定(デフォルト動作に従う)
【model_id】
自動的に開きたいmodel_idを指定します。
複数指定すると複数開くことができます
model_id=openai_gpt_4o_mini&model_id=rakuten__rakuten_ai_7b_chat
model_id 一覧(※一部モデルは法人版のみで有効)
| モデル名 | モデル表示名 | model_id |
|---|---|---|
| llama3.1 | Meta-Llama-3.1-8B | meta_llama_3_1_8b_instruct |
| node(chatstream.net用mistral_nemo) | Mistral-Nemo-Instruct-2407 | mistral_nemo_instruct_2407 |
| node:0(default) | calm3-22b-chat | calm3_22b_chat |
| node(chatstream.net用elyza8B) | Llama-3-ELYZA-JP-8B | llama_3_elyza_jp_8b |
| node:0(default) | RakutenAI-7B-chat | rakuten__rakuten_ai_7b_chat |
| node(chatstream.net用GPT4o_mini) | OpenAI GPT-4o mini | openai_gpt_4o_mini |
| node(chatstream.net用GPT3.5_newtech) | OpenAI GPT-3.5 | openai_gpt_3_5_175b |
| node(chatstream.net用Claude3Haiku) | Anthropic Claude3-Haiku | anthropic_claude3_0_haiku |
| node(chatstream.net用Gemini1.5Flash) | Google Gemini1.5 Flash | google_gemini1_5_flash |
| Anthropic Claude 3.5 Sonnet | Anthropic Claude 3.5 Sonnet | anthropic_claude_3_5_sonnet |
| Google Gemini1.5 Pro | Google Gemini1.5 Pro | google_gemini1_5_pro |
| OpenAI gpt-4o | OpenAI GPT4o | openai_gpt4o |
注
・確実に複数 開きたいときは、 mult=1 を明示的に指定してください。
・確実に自動的に開きたいときは ontp=1 を明示的に指定してください。
【isync】
input_sync をあらわすクエリパラメータです。
複数のLLMへの入力を同期させることができます
isync=1
isync=1 入力同期が有効
isync=0 入力同期はしない
isync無指定 デフォルトの設定に従う
【noip】
noip は no_iphone をあらわすクエリーです。
iPhone専用の描画モードを無効にします



