
[ChatStream] 時間のかかるモデル読み込みにプログレスバーをつける
![[ChatStream] 時間のかかるモデル読み込みにプログレスバーをつける](/content/images/size/w1200/2024/04/progress.webp)
こんにちは (株)Qualiteg プロダクト開発本部です!
HuggingFace の LLMのモデル読み込み時間ってとても長いですよね、そんなときに、便利なツールをご紹介します。
HuggingFace の LLM モデルはダウンロードするときは、進捗がでるのですが、ひとたびダウンロードしたあとは、読み込むまで短くて数分、長くて数十分待たされます。これはディスクからモデルデータ(weights and bias)を処理しながらGPUのVRAMに読み込む処理に時間がかかるのですが、その読み込み状態がいったいいまどのくらいなのか、これがわからず、ヤキモキしたことは無いでしょうか。
そこでは ChatStreamの便利機能として、以下のように、このモデル読み込み時間のプログレス表示をすることができます。
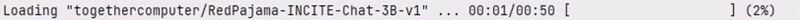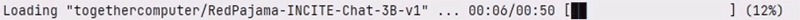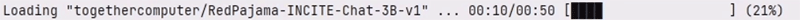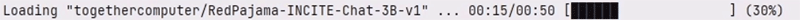
仕掛けはいたってシンプルで、初回の読み込み実行時に処理時間を計測しておき、2回目、また同じ処理が呼ばれたときはプログレスバーを表示します。
使い方も簡単で、モデルの読み込みを LoadTime でラップするだけで、プログレスバーつきで読み込むことができます
Before
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.float16)
↓
↓
After
from chatstream import LoadTime
model = LoadTime(name=model_path,
fn=lambda: AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.float16))()
モデル読み込みソースコード全体
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from loadtime import LoadTime
model_path = "togethercomputer/RedPajama-INCITE-Chat-3B-v1"
model = LoadTime(name=model_path,
fn=lambda: AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.float16))()
tokenizer = AutoTokenizer.from_pretrained(model_path) # tokenizerはモデル読み込みの後で取得します
ちなみに、本機能は、独立したライブラリとしても提供していますので、ChatStreamをご利用でなくても誰でも自由に使用することが可能です。
以下 loadtime パッケージのご紹介させていただきます
loadtime 使い方
インストール方法
pipを使ってLoadTimeをインストールできます
pip install loadtime
主な機能
-
リアルタイムトラッキング: LoadTimeは読み込みプロセスのリアルタイムトラッキングを提供します。
-
プログレスバー: プログレスバーを表示し、処理がどれだけ完了し、まだどれだけ残っているかを示します。
-
過去の読み込み時間キャッシュ:
前回処理した時間をキャッシュしておくため、キャッシュされた情報を使用して、プログレスバーを提供します。 -
カスタマイズ可能な表示: LoadTimeは、自分のメッセージで進捗表示をカスタマイズすることができます。
基本的な使い方
サンプルコードを示します
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from loadtime import LoadTime
model_path = "togethercomputer/RedPajama-INCITE-Chat-3B-v1"
model = LoadTime(name=model_path,
fn=lambda: AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.float16))()
tokenizer = AutoTokenizer.from_pretrained(model_path) # tokenizerはモデル読み込みの後で取得します
初期化パラメータ一覧
| パラメータ | 説明 |
|---|---|
| name | 長時間処理の名前を指定します。HuggingFace モデルの読み込み時はモデル名を指定します。 |
| message | 表示するメッセージを指定します。省略するとデフォルトのメッセージとなります。 |
| pbar | True に設定すると、プログレスバーとパーセンテージが表示されます。 |
| dirname | キャッシュ保存先のディレクトリ名を指定します。 |
| hf | True に設定すると、HuggingFace のモデル読み込み用の時間表示に使用します。まだモデルデータがディスクにダウンロードされていないときは、HuggingFace のローダーがダウンロード進捗を表示するため、本ライブラリからは表示しません。 |
| fn | 長時間処理をする関数を指定します。 |
| fn_print | 表示を行う関数を指定します。省略時はコンソールに出力されます。 |



