
【LLMセキュリティ】ハルシネーションの検出方法


こんにちは、Qualiteg研究部です。
本日は、RAGにおけるハルシネーション検出に関する、こちらの論文について解説をしつつ、ハルシネーション検出をおこなうLLMについて考察をしてみたいと思います。
"Lynx: An Open Source Hallucination Evaluation Model" https://arxiv.org/pdf/2407.08488
概要
LYNXという、RAG(Retrieval Augmented Generation) システムにおいて参照なしで高品質なハルシネーション検出が可能なオープンソースのLLMの構築方法、仕組みに関する論文です。
RAGシーンにおいて、LLMが生成する回答が、質問やコンテキストに対して「忠実」であるかどうかを判定することで、ハルシネーションを検出することができます。
研究の成果である、ハルシネーション判定のために llama3ファインチューニングがほどこされたモデルは 以下に公開されています。
https://huggingface.co/PatronusAI/Llama-3-Patronus-Lynx-70B-Instruct
ハルシネーションの定義
- ハルシネーションとは、与えられた質問 xに対する LLM の回答 P(x) が、その質問に文脈化されたコンテキスト C(x) によって裏付けられていない場合を指します。
- 具体的には、回答がコンテキストと一致しない、または誤った情報を含んでいる場合がハルシネーションとみなされます
ハルシネーション検出手法
提案のモデルであるLYNXは、LLMが生成する回答が、質問やコンテキストに対して忠実であるかどうかを評価することに特化しており、これを使用することで、RAGシステムにおけるハルシネーション検出を行うことができます。LYNX自体がLLMであり、 Llama3-70Bがファインチューニングされたモデルとなっています。
後ほどふれますが、学習は英語のトレーニングデータセットで学習されているため、日本語でそのまま使用するには、日本語におけるファインチューニング等が必要となります。
ハルシネーション検出の学習プロセス
本論文で学習させる対象は基本的に以下の2つとなります
- あるテキストが ハルシネーションあり か 正常か の2値分類の学習
- ハルシネーションありのとき、「なぜハルシネーションなのか」の理由付けの学習
それでは、上のふたつをふまえつつ、実際の二値分類器の学習をみてみましょう
二値分類器の学習プロセス
データセットの準備
【データ収集】
質問応答データセットから、(質問、文脈、回答、ラベル)の形式でサンプルを収集します。
ここでは、RAGTruth、DROP、CovidQA、PubMedQAといった既存のQAデータセットからサンプルを収集しています。
ラベルは「0」(ハルシネーションなし、正常な回答)
または「1」(ハルシネーションあり)です。
【意味摂動(Semantic Perturbations)の生成】
「意味摂動」とは、元のテキストの意味を大きく変えないようにしつつ、微妙な変更を加えて、その内容が元のコンテキストと一致しないようにするプロセスです。この手法は、元の文が与える印象を保ちながら、文脈に対して不正確な情報を含むように変更することを目的としています。ここでは正解の回答に対して微細な変更を加え、文脈と矛盾する回答を作成し、ハルシネーションの例を作ります。このプロセスにより、モデルはハルシネーションの有無を識別する能力を高めることができます。
モデルのトレーニング:
【学習の目的】
モデルは、質問と文脈に基づいて、与えられた回答がそのコンテキストに「忠実」であるかどうかを判定させることが学習の目的となります。
【トレーニング種別】
学習は二値分類問題として扱われ、
「0」(ハルシネーションなし、正常な回答)
「1」(ハルシネーションあり)
を判定するようにトレーニングされます。
モデルの出力:
【分類結果】
具体的には、 モデルは、入力された質問、文脈、回答を評価し、「PASS」(忠実な回答)または「FAIL」(ハルシネーションを含む回答)として分類します。
【理由付けの提供】
さらに、2値に加え、「 忠実」性を判断するための理由付けを提供し、モデルの出力の解釈性を向上させています。
評価方法
【評価指標】
モデルの性能は、HaluBenchのようなベンチマークを用いて評価されます。
「理由付け」を可能にするファインチューニングのプロセス
さて、ハルシネーションか否かを単に2値分類するだけなら、LLM以前の手法、たとえば DeBERTa v3 などでも高精度を出すことが可能です。
ここでは、LLMをつかうことのメリットを考えてみましょう。
それは、単なる2値分類だけでなく、「理由付け」(なぜ、それがハルシネーションと判定されるのか)も含めて学習できるところにメリットがあるからです。
1. Chain of Thought(CoT)の利用
- 思考過程の学習
Chain of Thought(CoT)は、モデルが解答を導くための思考過程を明示的に示すことによって、ゼロショット学習の性能を向上させる手法です - プロンプト設計
トレーニングデータには、質問に対する理由付けのステップを含めます。これにより、モデルは解答の背後にある論理的根拠を学習します。
2.プロンプトの設定
- プロンプトの具体例
以下のように、プロンプトに対して詳細な指示を含めることで、モデルは回答の理由付けを提供することができます
PROMPT = """
Given the following QUESTION, DOCUMENT and ANSWER you must analyze the provided answer and determine whether it is faithful to the contents of the DOCUMENT. The ANSWER must not offer new information beyond the context provided in the DOCUMENT. The ANSWER also must not contradict information provided in the DOCUMENT. Output your final verdict by strictly following this format: "PASS" if the answer is faithful to the DOCUMENT and "FAIL" if the answer is not faithful to the DOCUMENT. Show your reasoning.
--
QUESTION (THIS DOES NOT COUNT AS BACKGROUND INFORMATION):
{question}
--
DOCUMENT:
{context}
--
ANSWER:
{answer}
--
Your output should be in JSON FORMAT with the keys "REASONING" and "SCORE":
{{"REASONING": <your reasoning as bullet points>, "SCORE": <your final score>}}
"""
(プロンプト原版)
あなたは、質問、文脈、回答が与えられた状況で、回答が文脈に対して忠実であるかどうかを判断する必要があります。回答が文脈に忠実であれば「PASS」、そうでなければ「FAIL」として評価し、その理由をJSON形式で提供してください。
質問:
{質問}
文脈:
{文脈}
回答:
{回答}
出力フォーマット:
{
"REASONING": "<理由付けを箇条書きで提供>",
"SCORE": "<最終評価(PASSまたはFAIL)>"
}
3. モデルのファインチューニング
- データセット構築
各サンプルには、質問、文脈、回答、及びその回答が忠実であるかどうかのラベルに加え、理由付けのステップを含むデータを用意します - ファインチューニングの方法
教師付き学習を通じて、モデルが分類結果だけでなく、その判断に至った理由を出力するように訓練します。これにより、モデルは単なる分類結果だけでなく、その背後にある論理的根拠も提供できるようになります。大きなモデルでこのファインチューニングするほど、より意図にそった論理的根拠を提供できるようになるところがLLMの万能性ですね。
使用方法
- ハルシネーション検出のコード
以下のコードで prompt に上記で示したプロンプトを入力すると、ハルシネーション検出が可能です。
model_name = 'PatronusAI/Llama-3-Patronus-Lynx-8B-Instruct'
pipe = pipeline(
"text-generation",
model=model_name,
max_new_tokens=600,
device="cuda",
return_full_text=False
)
messages = [
{"role": "user", "content": prompt},
]
result = pipe(messages)
print(result[0]['generated_text'])
- 出力フォーマット
モデルが与えられた質問、文脈、および回答を評価し、分類結果(PASS/FAIL)とその理由付けをJSON形式で出力します
{
"REASONING": [
"回答は文脈の事実と一致している",
"文脈内の情報に基づいて、回答が適切である"
],
"SCORE": "PASS"
}
ベンチマーク結果
商用の最高峰モデルに対しても良好なベンチマーク結果を残しています。
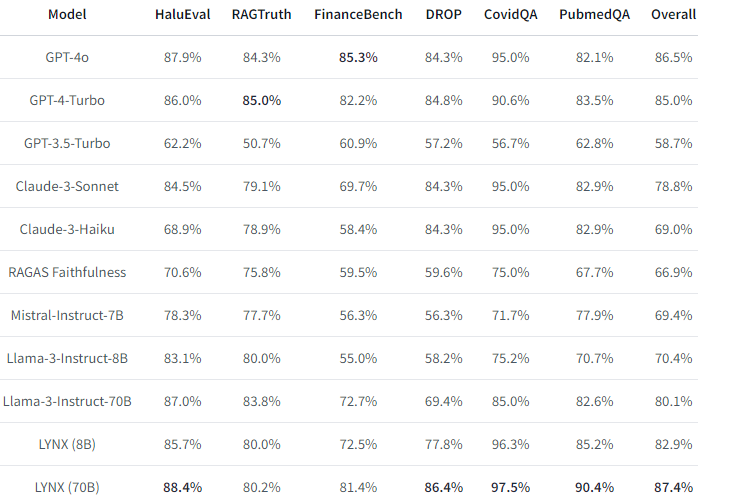
まとめ
今回はハルシネーションを検出することのできるLLM "LYNX" についてご紹介しました。教師データをつかってハルシネーションあり、か、正常化を2値学習をさせつつ、さらに、その詳細な理由付けも含めて学習させることで、ハルシネーションの発生有無だけでなく、なぜそれがハルシネーションなのかも詳細に知ることができるアプローチが成功することがわかりました。
このアプローチは、特に複雑な判断が必要とされるドメイン(例:法律、医療、金融)においても応用可能となるでしょう。
LLM-Audit のご紹介
Qualiteg では、LLMのセキュリティソリューション「LLM-Audit™」を開発・提供しております。
LLMがビジネス活用されるにつれ、LLMへの各種攻撃が活発化しています。
一方で、これまでのWebセキュリティとはまた異なったLLMへの攻撃についてはまだ知見も乏しく防衛手段も確率していません。
(株)Qualiteg では、LLMサービス開発・運営を通して得た経験・知見を集めた LLM防衛ソリューション 「LLM-Audito™」をご提供しています。
これにより、悪意ある入力プロンプトのブロック、LLMによる不適切な出力の監査を強力に実行しLLMの安全、安心を実現することができます。
OpenAI API 互換サーバーとして貴社LLMをラッピングするだけで利用できますので非常に小さな導入コストで高度化したLLMセキュリティを実現することが可能です。
LLMセキュリティやLLM-Audit™ にご関心がおありの場合は以下までご連絡くださいませ。またLLMセキュリティコンサルティングや製品デモについてもどうぞお気軽にこちらのお問い合わせフォームまでご連絡くださいませ。



