
DockerビルドでPythonをソースからビルドするとGCCがSegmentation faultする話

こんにちは!Qualitegプロダクト開発部です!
本日は Docker環境でPythonをソースからビルドした際に発生した、GCCの内部コンパイラエラー(Segmentation fault) について共有します。
一見すると「リソース不足」や「Docker特有の問題」に見えますが、実際には PGO(Profile Guided Optimization)とLTO(Link Time Optimization)を同時に有効にした場合に、GCC自身がクラッシュするケースでした。
ただ、今回はDockerによって問題が隠れやすいという点もきづいたので、あえてDockerを織り交ぜた構成でのPythonソースビルドとGCCクラッシュについて実際に発生した題材をもとに共有させていただこうとおもいます
同様の構成でビルドしている方の参考になれば幸いです
TL;DR
- Docker内でPythonを
--enable-optimizations --with-lto付きでソースビルドすると
GCCが internal compiler error(Segmentation fault)で落ちることがある - 原因は PGOビルド中(プロファイル生成段階)にGCCの最適化パスがクラッシュする可能性
- リソース不足ではなく、コンパイラ内部エラー(ICE)
- 解決策は 最適化フラグを外すこと
実行性能差は 数%〜20%程度(用途依存) で、CIやDockerでは安定性優先が無難
発生した問題
Dockerイメージ内で Python をソースからビルドしていたところ、make の途中で突然ビルドが失敗してしまいました
ログの本質的に重要な部分を抜粋すると次のような状態です
during RTL pass: sched2
In function 'zlib_Compress_flush':
internal compiler error: Segmentation fault
make[1]: *** [Makefile: profile-gen-stamp] Error 2
make: *** [Makefile: profile-run-stamp] Error 2
ポイントは以下です。
- internal compiler error
→ ユーザーコードではなく、GCC自身がクラッシュ - during RTL pass: sched2
→ GCCバックエンド最適化パス中の異常 - profile-gen-stamp の失敗
→ PGOの「プロファイル生成用ビルド」段階で停止
重要な事実:落ちたのは「PGOの第1段階」
当初、「PGOの2回目(-fprofile-use)」で落ちたのでは?と疑いましたが、
実際のログを精査すると -fprofile-generate が付いた段階、つまり
PGOの“プロファイル生成用ビルド”
で GCC が Segmentation fault を起こしていることがわかります
つまり、これは以下を意味します
- Python側のコード不具合ではない
- 実行フェーズにすら到達していない
- PGO + LTO が有効な状態で、GCCの最適化処理が破綻している可能性が高い
なぜ今まで問題なかったのか?
ちなみに、この問題は、ある日突然発生したように見えました。
が、実際には、以前から潜在的に存在していた可能性があります。
Dockerビルドキャッシュの影響
Dockerは RUN 命令単位でビルド結果をキャッシュします。
- Dockerfileが変更されない限り
→ Pythonのビルド工程はキャッシュから復元 - Dockerfileを少しでも変更すると
→ その行以降のキャッシュはすべて無効化
キャッシュが無効化された理由
Dockerfileに何らかの変更を加えると、その行以降のすべてのキャッシュが無効化されます。
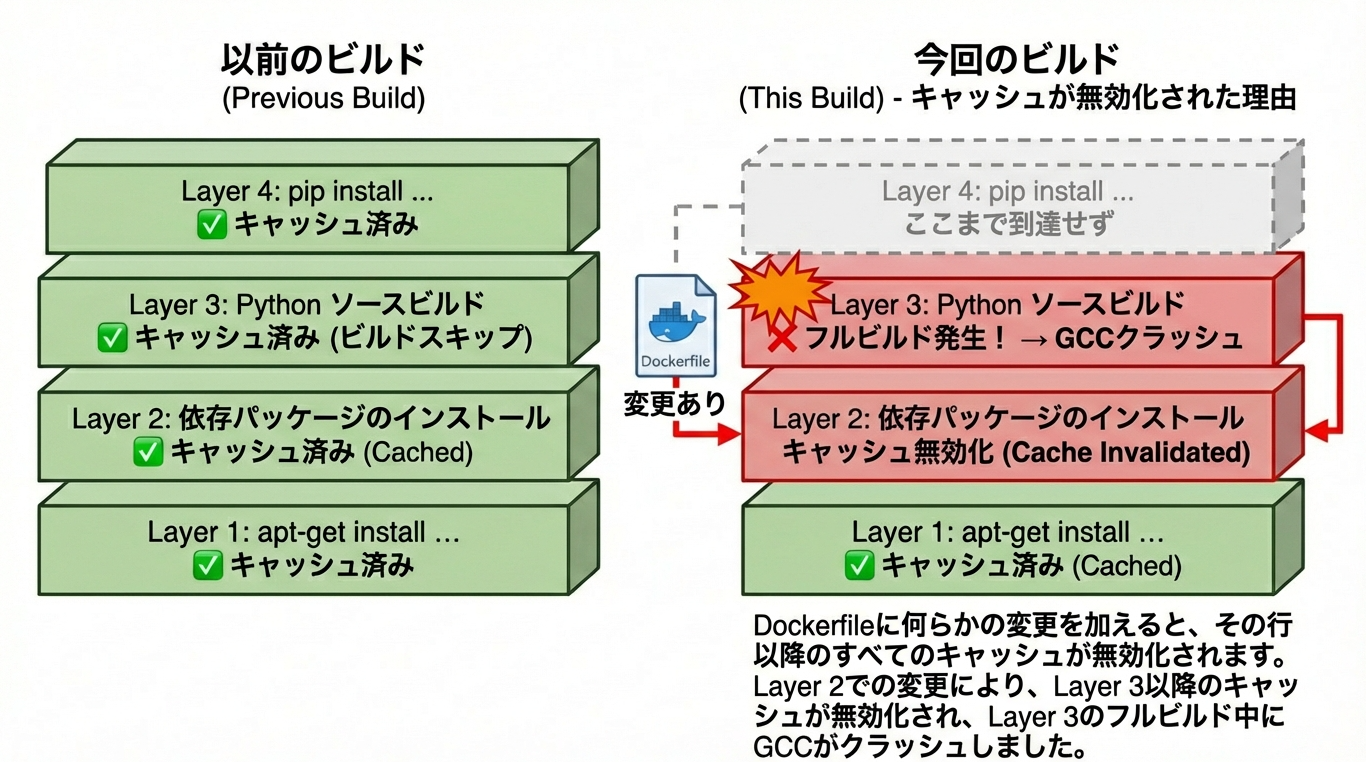
つまり、
「たまたまキャッシュが使われていただけで、
実際には壊れたビルド手順がずっと潜んでいた」
という状態でした
PGO(Profile Guided Optimization)とは
PGOは、プログラムの実行傾向を元に最適化を行う仕組みです。
Pythonの --enable-optimizations は、内部的に以下の流れを取ります。
- プロファイル生成用にビルド(
-fprofile-generate) - 生成したPythonを実行してプロファイル収集
- 収集した情報を使って再ビルド(
-fprofile-use)
今回の問題は 1番目の段階ですでにGCCがクラッシュしています。
PGOビルドの流れ

LTO(Link Time Optimization)との組み合わせ
さらに今回のビルドでは --with-lto を指定していました。
LTOを有効にすると、
- コンパイル単位をまたいだ最適化
- GCC内部の解析対象が大幅に増加
してくれます
さらに、
PGO + LTO を同時に有効化すると、
- プロファイル情報
- 中間表現(RTL)
- 複雑な最適化パス
が重なり、GCC内部の既知・未知のバグを踏み抜きやすい状態になってしまいます、結果的に。
今回の sched2 パスでのSegfaultは、まさにその典型例でした。。
解決策
そこで、今回のような問題への解決策としていくつかあげてみたいとおもいます
方法1: PGOとLTOを無効化(推奨)
結論からいうと、この方法1を採用しました。
configureのオプションについて変更を示します
変更前
./configure --enable-optimizations --with-lto
変更後
./configure
メリット
- 確実にビルドが成功する
- ビルド時間が大幅に短縮される(PGOは2回ビルド)
- CI/CDやDocker環境で安定
デメリット
- 実行性能が 数%〜20%程度低下する可能性
(用途・ベンチマークに強く依存ではあります)
多くのサーバ用途・バッチ用途では 実用上問題にならないケースがほとんどです。
方法2: LTOのみ無効化
./configure --enable-optimizations
- PGOは維持
- LTOによる複雑化を回避
ただし GCCのPGO関連バグ自体は残るため、環境によっては再発する可能性ありです
方法3: 並列度を下げる(非推奨)
make -j2
- メモリ圧迫を緩和できる場合はある
- しかし ICEは本質的に解決しない
- ビルド時間が著しく増加
方法4: ソースビルドを避ける
# deadsnakes PPAからインストール
RUN add-apt-repository ppa:deadsnakes/ppa \
&& apt-get install -y python3.13
- ディストリビューション提供のPython
- 信頼できるpre-builtパッケージ
を使うことで、この種の問題は完全に回避できます。
推奨するDockerfile例(安定性重視)
方法1を採用してビ安定的にビルドをしたいときは以下のようにします。今回はDockerつかってるのでDockerfileは以下のような感じになります
# ===========================================
# Python(ソースビルド・安定版)
# ===========================================
# 注意:
# --enable-optimizations / --with-lto は
# GCC内部エラー(ICE)を引き起こす可能性があるため使用しない
ARG PYTHON_VERSION=3.13.5
RUN wget https://www.python.org/ftp/python/${PYTHON_VERSION}/Python-${PYTHON_VERSION}.tgz \
&& tar xzf Python-${PYTHON_VERSION}.tgz \
&& cd Python-${PYTHON_VERSION} \
&& ./configure \
&& make -j$(nproc) \
&& make install \
&& cd .. \
&& rm -rf Python-${PYTHON_VERSION} Python-${PYTHON_VERSION}.tgz
教訓
1. Dockerキャッシュは問題を隠す
キャッシュは便利ですが、「壊れた手順がたまたま実行されていない」だけの場合があります。
定期的な --no-cache ビルドは重要です
2. 最適化フラグは安定性とトレードオフ
PGOやLTOは強力ですが、DockerやCIでは安定性優先が現実的です
3. internal compiler error は疑うべき
Segmentation fault + internal compiler error は
ほぼ確実に コンパイラ側の問題です。
コードを疑う前に、ビルドフラグを疑いましょう
それでは、次回またお会いしましょう!



