
GPUを使った分散処理で見落としがちなCPUボトルネックとtasksetによる解決法

こんにちは!
複数枚のGPUをつかった並列処理システムを設計しているときCPUについてはあまり考えないでシステムを設計してしまうことがあります。
「機械学習システムの主役はGPUなんだから、CPUなんて、あんまり気にしなくてよいのでは」
いいえ、そうでもないんです。
推論中のあるタイミングに急に動作が遅くなったりするときCPUが原因であることがけっこうあります。
概要(5分で分かる要点)
先日GPUを使った並列処理システムで、予期しないCPUボトルネックが発生し、パフォーマンスが大幅に低下する問題に遭遇しました。
複数のプロセスが異なるGPUを使用しているにも関わらず、処理が極端に遅くなる現象の原因は、処理パイプラインの一部に含まれるCPU集約的な計算処理でした。
問題の症状
- 単一プロセス実行時:正常な速度
- 複数プロセス並列実行時:処理時間が数倍に増加
- GPUリソースに競合なし(nvidia-smiで確認済み)
根本原因
処理パイプラインにGPUに適さないCPU集約的な計算(データ前処理、統計変換など)が含まれており、複数プロセスが同じCPUコアを奪い合うことで、キャッシュ競合とコンテキストスイッチが頻発していました。
解決方法
tasksetコマンドで各プロセスを特定のCPUコアに固定
→これにより、複数プロセスで同じCPUコアを奪い合うことを回避
うまいことやってよ!、って思いますが、
複数のプロセスが CPU の1番目のコアを使おうとしていました
こういう部分もちゃんと制御してやる必要があるんです!
# プロセス1をCPU 0-7に固定
taskset -c 0-7 python process1.py --gpu 0
# プロセス2をCPU 8-15に固定
taskset -c 8-15 python process2.py --gpu 1
適用のポイント
- Intel Coreシリーズ:P/Eコアの特性を考慮してCPU集約的タスクはPコアに配置
- Intel Xeonシリーズ:NUMAアーキテクチャを考慮し、同一ソケット内でコアを割り当て
- システムプロセス用のコアを確保:すべてのコアを占有せず、1-2コアは空けておく
このごく簡単な設定により、並列実行時のパフォーマンスが劇的に改善し、ほぼ理想的な並列化効率を達成できました。
コロンブスの卵ですね。
さて、ざっくり版はここまでです。
以下、問題原因の特定やメカニズム、CPU特性に応じた設定方法について詳細編につづきます
詳細版:技術的背景と実装方法
さて、概要はあんなかんじですが、
ここからは問題詳細と具体的な実装方法について解説いたします。
問題発生と原因の特定
問題の発見と初期の混乱
ある日、私たちのチームが開発していたマルチGPU処理システムで奇妙な現象が観察されました。
このシステムは、大規模なデータセットに対して並列処理を行うために設計されたもので、複数のGPUを搭載したサーバー上で動作していました。ここではGPU2枚の話にシンプル化してご説明いたします。
単一のプロセスで処理を実行した場合、期待通りの処理速度で動作し、GPUの使用率も適切な水準を維持していました。しかし、2つのプロセスを異なるGPU(CUDA:0とCUDA:1)に割り当てて同時に実行すると、特定の処理ステップにおいて処理時間が極端に増加するという現象が発生しました。具体的には、単独実行時に数秒で完了していた処理が、並列実行時には数十秒、時には分単位の時間を要するようになったのです。
当初、開発チームはGPUリソースの競合を疑いました。nvidia-smiコマンドを使用してGPUの状態を監視したところ、各プロセスは確実に異なるGPUを使用しており、GPUメモリの使用量も許容範囲内であることが確認されました。
原因の特定プロセス
GPUリソースに問題がないことが判明した後、私たちは処理パイプライン全体の詳細な分析に着手しました。
各処理ステップの実行時間を計測し、ボトルネックとなっている箇所を特定するため、プロファイリングツールを導入しました。
数日間の調査の結果、処理パイプラインの一部にCPU集約的な計算処理が含まれていることが判明しました。
この処理は全体の処理フローの中では全体の処理時間の数パーセント程度だったのですが、その内容を詳しく分析すると、大量の行列演算を含むデータの前処理段階で必要となる統計的な変換処理でした。具体的には、入力データの正規化、特徴量の抽出、そして複雑な数学的変換です。これらの処理は逐次的な性質を持ち、並列化が困難であったため、GPUではなくCPU用に書かれていました。
どうやらCPUで何かが起こってるということで、さらなる問題分析と問題の根本原因をスタディしました。
問題の根本原因 はCPUのリソース競合
問題の根本原因をさぐっていくと、どうやらCPUのリソース競合ということが最終的に発覚しましたので、以降はその解説をしていきたいとおもいます。
CPUアーキテクチャとコア数の理解
問題を深く理解するために、まず使用しているCPUのアーキテクチャとコア構成を確認する必要があります。
Intel Coreシリーズの典型的なコア構成
| 世代 | モデル | 総コア数 | 総スレッド数 | Pコア | Pコアスレッド | Eコア | Eコアスレッド |
|---|---|---|---|---|---|---|---|
| 第12世代 | Core i9-12900K | 16 | 24 | 8 | 16 | 8 | 8 |
| 第13世代 | Core i9-13900K | 24 | 32 | 8 | 16 | 16 | 16 |
| 第14世代 | Core i9-14900K | 24 | 32 | 8 | 16 | 16 | 16 |
第12世代以降のIntel Coreシリーズでは、高性能なPコア(Performance-core)と省電力なEコア(Efficiency-core)のハイブリッド構成を採用しています。この構成では、CPU集約的なタスクをPコアに割り当てることが重要です。
Intel Xeonシリーズの特徴
| シリーズ | モデル | コア数 | スレッド数 | 備考 |
|---|---|---|---|---|
| Xeon Gold | 6354 | 18 | 36 | |
| Xeon Gold | 6348 | 28 | 56 | |
| Xeon Platinum | 8380 | 40 | 80 | |
| Xeon Platinum | 8480+ | 56 | 112 | 最大2ソケット対応 |
Xeonシリーズの大きな特徴は、マルチソケット構成のサポートです。
例えば、Xeon Platinum 8480+は最大2ソケット構成をサポートし、合計112コア224スレッドという強力な計算能力を実現でっきます
問題発生のメカニズム
CPUリソースの競合がどのように発生するのか、そしてなぜそれが深刻なパフォーマンス低下を引き起こすのかを詳しく解説します。
taskset適用前の状態
複数のCPU集約的なプロセスを同時に実行すると、以下のような状態が発生します
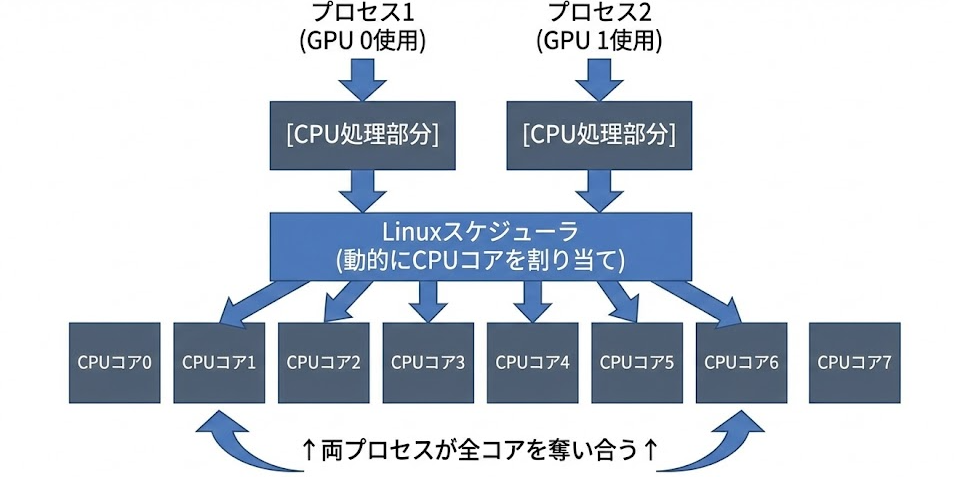
時間軸に沿って見ると、実際には以下のような激しいCPUコアの奪い合いが発生しています
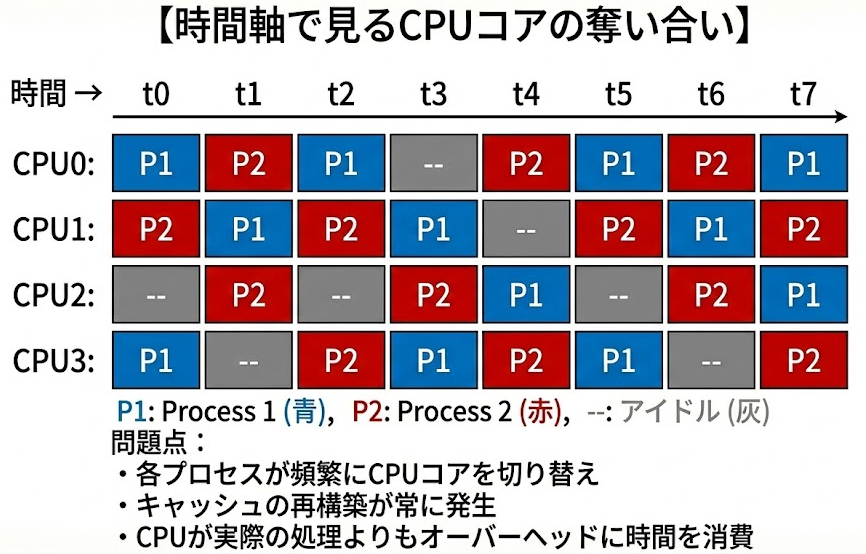
結果: キャッシュ競合、コンテキストスイッチ頻発
→ 処理速度が大幅に低下
taskset適用後の状態
tasksetコマンドを使用してCPUアフィニティを設定すると、状態は劇的に改善します
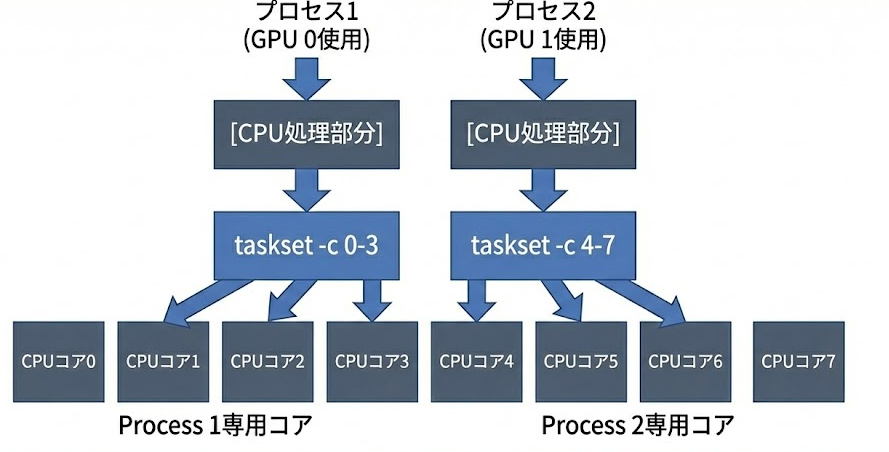
結果: キャッシュ競合なし、コンテキストスイッチ最小化
→ 各プロセスが安定した処理速度を維持
なぜこのような違いが生まれるのか - 動作原理の詳細
Linuxスケジューラの動作原理
Linuxカーネルに実装されているCFS(Completely Fair Scheduler)は、システム全体の効率を最大化するよう設計されています。このスケジューラは、実行可能なすべてのプロセスに対して「公平に」CPU時間を配分しようとします。具体的には、各プロセスの実行時間を追跡し、最も実行時間が少ないプロセスを次に実行するよう選択します。
通常のワークロードでは、この仕組みは非常に効果的です。しかし、CPU集約的な複数のプロセスが同時に実行される場合、スケジューラは各プロセスを利用可能なすべてのCPUコアに動的に割り当て続けます。この「動的な割り当て」が、実は深刻なパフォーマンス問題の原因となります。
キャッシュ階層とその影響
CPUリソースの競合が深刻な問題となる理由を理解するために、CPUのキャッシュ階層について見てみましょう
CPUキャッシュの階層構造
現代のCPUは、メインメモリへのアクセス遅延を隠蔽するために、多層のキャッシュメモリを搭載しています
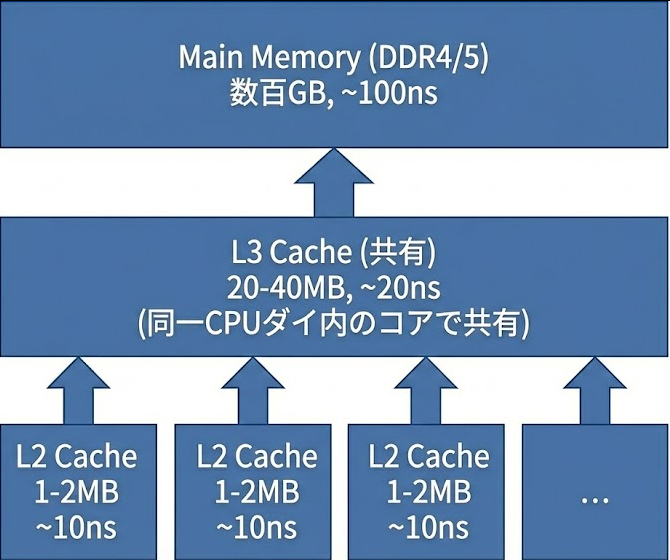
重要な特性
- L1/L2キャッシュ: 各CPUコア専用で、そのコアで実行されるプロセスのデータを保持
- L3キャッシュ: 同一CPUダイ内のすべてのコアで共有(Intel Coreの第12世代以降ではP/Eコアで分離される場合あり、Xeonではソケット単位)
- アクセス速度の差: L1キャッシュ(4ns)からメインメモリ(100ns)まで、25倍以上の速度差
キャッシュ競合による性能劣化のメカニズム
この階層構造を理解した上で、複数プロセスが同じCPUコアを奪い合う場合に何が起きるかを見てみましょう:
1. キャッシュの汚染と無効化
プロセスがCPUコアを切り替える際の動作を時系列で追うと以下のようになります。
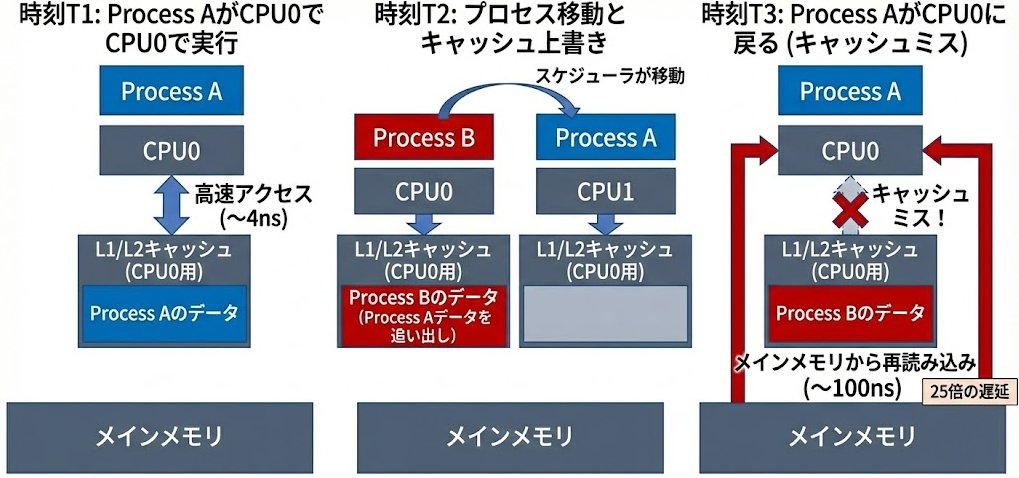
このように、プロセスがコア間を移動すると、キャッシュの局所性が失われ、低速なメインメモリへのアクセスがふえて性能が大幅に低下します
2. キャッシュスラッシングの発生
また、頻繁なプロセス切り替えが発生すると、以下のような悪循環に陥ります
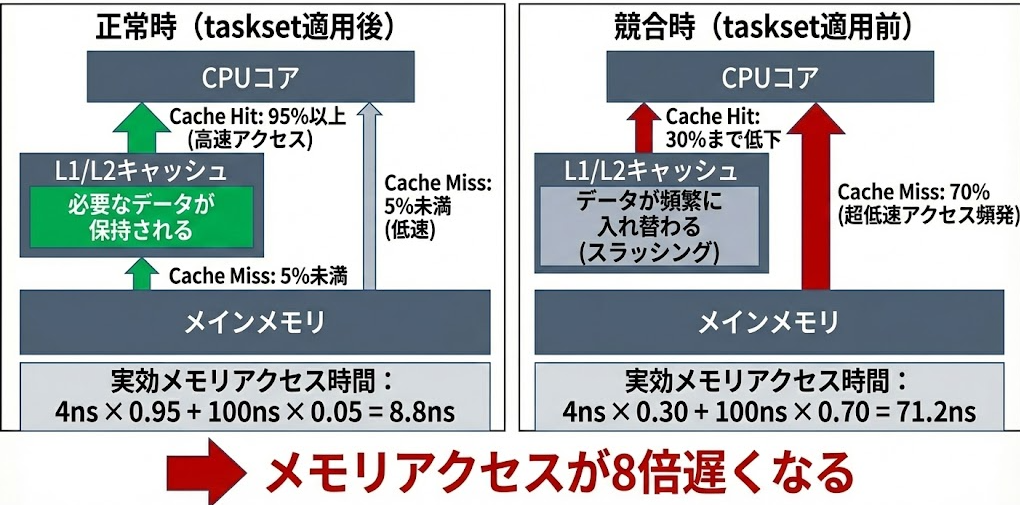
メモリ帯域幅の競合
さらに、CPU集約的な処理が大量のデータを扱う場合、メモリ帯域幅の競合も発生します。キャッシュミスが増加すると、メインメモリへのアクセスが増加し、メモリ帯域幅も圧迫されます
- 理論帯域幅: DDR4-3200で約51.2GB/s
- キャッシュヒット時: メモリ帯域使用率 5%程度
- キャッシュミス多発時: メモリ帯域使用率 70%以上
複数プロセスが同時にキャッシュミスを起こすと、メモリコントローラでの競合も発生し、さらなる遅延が生じます。
こういった要因が組み合わさることで、単純に2つのプロセスを実行した場合でも、処理時間が2倍以上に増加する現象が発生してしまうことがあります。
ということで、tasksetによるCPUアフィニティの設定は、これら問題をさくっと一発で解決する、シンプルかつ効果的なアプローチとなります。
Xeonシリーズにおける考慮事項
さて、Intel Xeonシリーズを使用する場合、特にマルチソケット構成では、NUMA(Non-Uniform Memory Access)アーキテクチャを意識しないと沼にはまることになります。
NUMAアーキテクチャとは
NUMAは、複数のCPUソケットを搭載したシステムにおけるメモリアクセスの最適化技術です。各CPUソケットは自身専用のメモリコントローラとローカルメモリを持ち、これらの組み合わせを「NUMAノード」と呼びます。
重要な特性として、CPUは自身のNUMAノードに属するローカルメモリへのアクセスは高速(約70-100ns)ですが、他のNUMAノードのメモリ(リモートメモリ)へのアクセスは、QPI(QuickPath Interconnect)やUPI(Ultra Path Interconnect)を経由する必要があるため、1.5~2倍のレイテンシ(約150-200ns)が発生します。
なぜNUMA最適化が重要なのか
NUMA構成を無視してプロセスを配置すると、以下の問題が発生し沼ります。
- メモリアクセスの不均衡
プロセスがSocket 0のCPUで実行されているが、メモリがSocket 1に配置されている場合、すべてのメモリアクセスがUPIリンクを経由することになり、大幅な性能低下を引き起こします。 - メモリ帯域幅の競合
複数のプロセスが異なるソケットから同一のメモリバンクにアクセスすると、UPIリンクの帯域幅(最大約41.6GB/s)がボトルネックとなります。ローカルメモリの帯域幅(DDR4-2933で約140GB/s)と比較すると、大幅に制限されます。 - キャッシュコヒーレンシのオーバーヘッド
異なるソケット間でデータを共有する際、キャッシュの一貫性を保つためのスヌープ処理が発生し、レイテンシがさらに増加します。
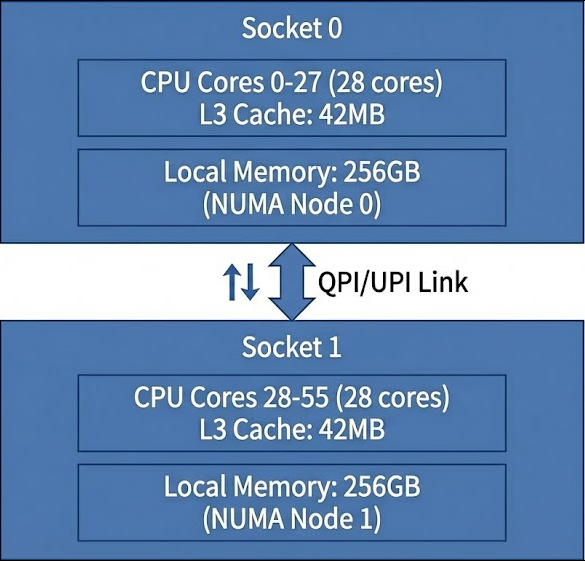
ということで、XEONの場合尾は、プロセスをNUMAノード単位で割り当てることが重要となります
# プロセス1:NUMA Node 0のCPUとメモリを使用
numactl --cpunodebind=0 --membind=0 taskset -c 0-27 python process1.py --gpu 0
# プロセス2:NUMA Node 1のCPUとメモリを使用
numactl --cpunodebind=1 --membind=1 taskset -c 28-55 python process2.py --gpu 1
NUMAノードをまたぐメモリアクセスは、ローカルメモリアクセスと比較して約1.5~2倍のレイテンシが発生します。そのため、各プロセスが使用するCPUコアとメモリを同一のNUMAノード内に配置することで、メモリアクセスのレイテンシを最小化し、パフォーマンスを大幅に向上させることができます。
問題解決へ
さて、いろいろCPUについて調べて、この問題を解決法がみえてきました。
解決法はシンプルで、どのプロセスをどのコアに割り振るか、を制御するという方法です。そのためにtasksetコマンドを活用することができます。tasksetは、Linuxにおいてプロセスを特定のCPUコアセットに固定(アフィニティの設定)するための強力なツールです。
それでぇあ、それぞれの環境において、どのようにtasksetを使うかみていきましょう。
Intel Coreシリーズでの実装例
Intel Core i9-13900K(8 Pコア + 16 Eコア)を使用する場合の実装例
# Pコアの確認(通常0-15がPコア+HTT)
lscpu --all --extended | grep "Core"
# プロセス1:Pコアの前半を使用
taskset -c 0-7 python heavy_process1.py --gpu 0
# プロセス2:Pコアの後半を使用
taskset -c 8-15 python heavy_process2.py --gpu 1
# 軽量なバックグラウンドタスクはEコアへ
taskset -c 16-31 python background_task.pyIntel Xeonシリーズでの実装例
Xeon Gold 6348(28コア×2ソケット)を使用する場合
# NUMAノードの確認
numactl --hardware
# プロセス1:Socket 0のコアを使用(NUMA最適化)
numactl --cpunodebind=0 --membind=0 \
taskset -c 0-27 python process1.py --gpu 0
# プロセス2:Socket 1のコアを使用(NUMA最適化)
numactl --cpunodebind=1 --membind=1 \
taskset -c 28-55 python process2.py --gpu 1Windows Subsystem for Linux (WSL)環境での実装
WSL環境でも同様の最適化が可能です。
@echo off
setlocal enabledelayedexpansion
rem システムのCPU情報を取得
for /f "tokens=*" %%a in ('wsl -e lscpu ^| grep "Model name"') do set CPU_MODEL=%%a
echo CPU Model: %CPU_MODEL%
rem CPUコア数を確認(WSL経由)
for /f "tokens=*" %%a in ('wsl -e nproc') do set TOTAL_CORES=%%a
echo Total CPU cores: %TOTAL_CORES%
rem NUMAノード数を確認
for /f "tokens=*" %%a in ('wsl -e lscpu ^| grep "NUMA node(s)" ^| awk "{print $3}"') do set NUMA_NODES=%%a
echo NUMA nodes: %NUMA_NODES%
rem CPUモデルに応じた最適な設定を選択
if "%NUMA_NODES%"=="2" (
echo Detected dual-socket system, using NUMA optimization
rem Socket 0のコア範囲を計算
set /a CORES_PER_SOCKET=%TOTAL_CORES%/2
set /a SOCKET0_END=%CORES_PER_SOCKET%-1
rem Socket 1のコア範囲を計算
set /a SOCKET1_START=%CORES_PER_SOCKET%
set /a SOCKET1_END=%TOTAL_CORES%-1
rem NUMA最適化付きでワーカーを起動
start "Worker 1 (NUMA 0)" wsl -e bash -ic "numactl --cpunodebind=0 --membind=0 taskset -c 0-%SOCKET0_END% python worker.py --gpu 0 --worker-id 1"
start "Worker 2 (NUMA 1)" wsl -e bash -ic "numactl --cpunodebind=1 --membind=1 taskset -c %SOCKET1_START%-%SOCKET1_END% python worker.py --gpu 1 --worker-id 2"
) else (
echo Detected single-socket system, using simple core partitioning
rem CPUコアを2つのグループに分割
set /a HALF_CORES=%TOTAL_CORES%/2
set /a SECOND_HALF_START=%HALF_CORES%
set /a SECOND_HALF_END=%TOTAL_CORES%-1
rem シンプルなコア分割でワーカーを起動
start "Worker 1" wsl -e bash -ic "taskset -c 0-%HALF_CORES% python worker.py --gpu 0 --worker-id 1"
start "Worker 2" wsl -e bash -ic "taskset -c %SECOND_HALF_START%-%SECOND_HALF_END% python worker.py --gpu 1 --worker-id 2"
)
echo All workers started successfullyCPUアーキテクチャに応じた動的な設定を行うバッチファイルの例
まとめと今後の展望
GPUを活用した分散処理システムの開発において、GPU側の最適化に注目することは当然重要ですが、処理パイプライン全体を俯瞰し、隠れたボトルネックを見つけ出すことも同様に重要だと気づかされました。
特にCPUについては
「GPUとの帯域幅が充分あって、そこそこの性能のCPUのせときゃいいでしょ」
くらいの認識で、あまり深く考えてこなかったので今回の件は本当に学びになりました。
今回の事例のように処理パイプラインの一部に含まれていたCPU集約的な処理が、複数プロセスの並列実行時に深刻なボトルネックとなるシーンは結構あるんじゃないかとおもいます。
tasksetコマンドを使用したCPUアフィニティの設定は、こういう問題に対するシンプルかつ効果的な解決策でした。
特にIntel XeonシリーズのようなマルチソケットシステムでNUMA最適化と組み合わせることで、劇的なパフォーマンス向上を実現できそうです。
一方、Intel Coreシリーズの最新世代をつかうときはPコアとEコアのハイブリッド構成を理解し、適切にタスクを配置することが重要になります。
当社GPUサーバー群は現状基本インテルアーキテクチャを採用してますが、
AMDのチップレット設計、ARMサーバーの普及など、今後は、なにがあるかわかりませんのでこういうCPUの動作原理もちゃんとおさえて今後のものづくりに生かしていきたいとおもいます!
それでは、最後までお読みいただきありがとうございました!
また次回お会いしましょう!



