
「Windowsターミナル」を Windows Server 2022 Datacenter エディションに手軽にインストールする方法
こんにちは!
本稿はWindows Server 2022 Datacenterエディションに「Windowsターミナル」をインストールする方法のメモです。
ステップバイステップでやるのは少し手間だったので、Powershellにペタっとするだけで自動的にインストールできるよう手順をスクリプト化しました。
管理者権限で開いた Powershell に以下、スクリプトをペタっとすると、後は勝手に「Windowsターミナル」がインストールされます。
(ただしスクリプトの実行結果の保証も責任も負いかねます)
なにが手間か
何が手間かというと、Windows Server 2022 では、StoreもApp Installer(winget)もデフォルトではインストールされていないため「Windowsターミナル」をマニュアルでインストールしなければなりませんでした。
そこでペタっとするだけのスクリプト化
管理者権限で開いたPowershellに以下のスクリプトをペタっとすると「Windowsターミナル」が無事インストールされます。
パッケージのダウンロード先には [ユーザー名]/downloads を指定していますので、「ダウンロード」フォルダのなかに、ダウンロードされたファイルと展開されたファイルが残ります。インストール後に削除しても問題ありません。
# VCLibsのダウンロードとインストール
Invoke-WebRequest -Uri "https://aka.ms/Microsoft.VCLibs.x64.14.00.Desktop.appx" -OutFile "$env:USERPROFILE\Downloads\Microsoft.VCLibs.x64.14.00.Desktop.appx"
Add-AppxPackage -Path "$env:USERPROFILE\Downloads\Microsoft.VCLibs.x64.14.00.Desktop.appx"
# UI Xaml 2.8 のダウンロード
Invoke-WebRequest -Uri "https://www.nuget.org/api/v2/package/Microsoft.UI.Xaml/2.8.5" -OutFile "$env:USERPROFILE\Downloads\Microsoft.UI.Xaml.2.8.zip"
# UI Xaml 2.8 のzipを展開
Expand-Archive -Path "$env:USERPROFILE\Downloads\Microsoft.UI.Xaml.2.8.zip" -DestinationPath "$env:USERPROFILE\Downloads\Microsoft.UI.Xaml.2.8"
# UI Xaml 2.8 のx64用のappxファイルをインストール
Add-AppxPackage -Path "$env:USERPROFILE\Downloads\Microsoft.UI.Xaml.2.8\tools\AppX\x64\Release\Microsoft.UI.Xaml.2.8.appx"
# Windowsターミナルをダウンロードしてdownloadsフォルダに保存
Invoke-WebRequest -Uri "https://github.com/microsoft/terminal/releases/download/v1.21.2701.0/Microsoft.WindowsTerminal_1.21.2701.0_8wekyb3d8bbwe.msixbundle" -OutFile "$env:USERPROFILE\Downloads\Microsoft.WindowsTerminal_1.21.2701.0_8wekyb3d8bbwe.msixbundle"
explorer "$env:USERPROFILE\Downloads"
# Windows Terminalをインストール
Add-AppxPackage -Path "$env:USERPROFILE\Downloads\Microsoft.WindowsTerminal_1.21.2701.0_8wekyb3d8bbwe.msixbundle"
すると、必要なパッケージのダウンロードにはじまり、数分待てばWindowsターミナルをインストールすることができます。
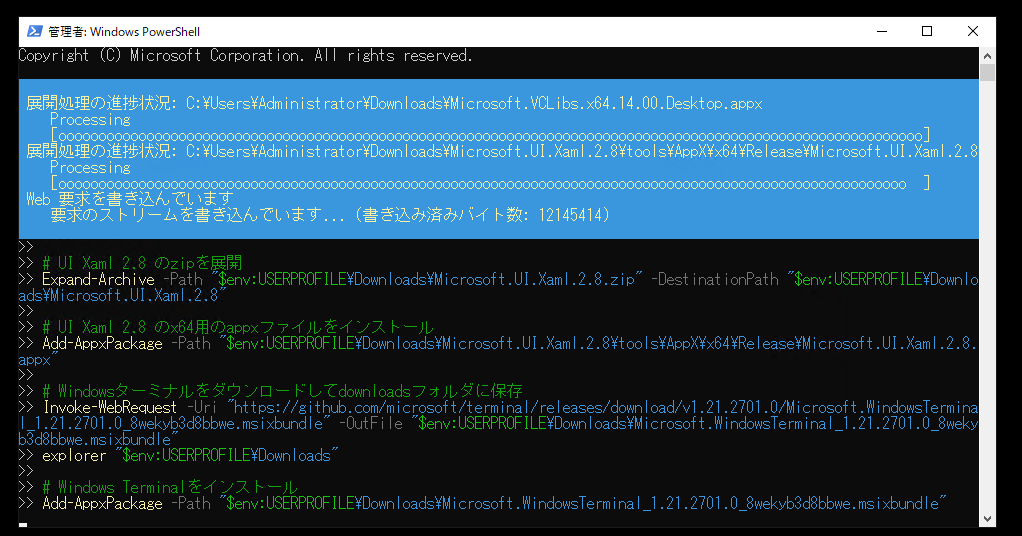
ダウンロードフォルダのお掃除

こんな感じでターミナルインストール関係ファイルが生成されてます。これは削除しても問題ありません。
インストール結果の確認
検索窓に「ターミナル」と入れてみましょう。
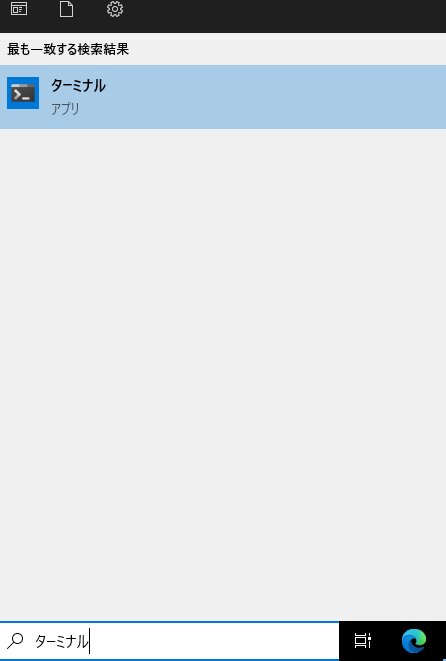
おお、ちゃんと「ターミナル」アプリがインストールされました。
ちなみに、検索窓に
wtとだけ入力しても起動することができます。



