
LLM推論基盤プロビジョニング講座 第3回 使用モデルの推論時消費メモリ見積もり


こんにちは!前回はLLMサービスへのリクエスト数見積もりについて解説しました。今回は7ステッププロセスの3番目、「使用モデルの推論時消費メモリ見積もり」について詳しく掘り下げていきます。
LLM推論基盤プロビジョニング講座 シリーズ記事一覧
- 第1回 基本概念と推論速度
- 第2回 LLMサービスのリクエスト数を見積もる
- 第3回 使用モデルの推論時消費メモリ見積もり
- 第4回 推論エンジンの選定
- 第5回 GPUノード構成から負荷試験までの実践プロセス
- 番外編 KVキャッシュのオフロード戦略とGQA
GPUメモリがリクエスト処理能力を決定する
LLMサービス構築において、GPUが同時に処理できるリクエスト数はGPUメモリの消費量によって制約されます。
つまり、利用可能なGPUメモリがどれだけあるかによって、同時に何件のリクエストを処理できるかがほぼ決まります。
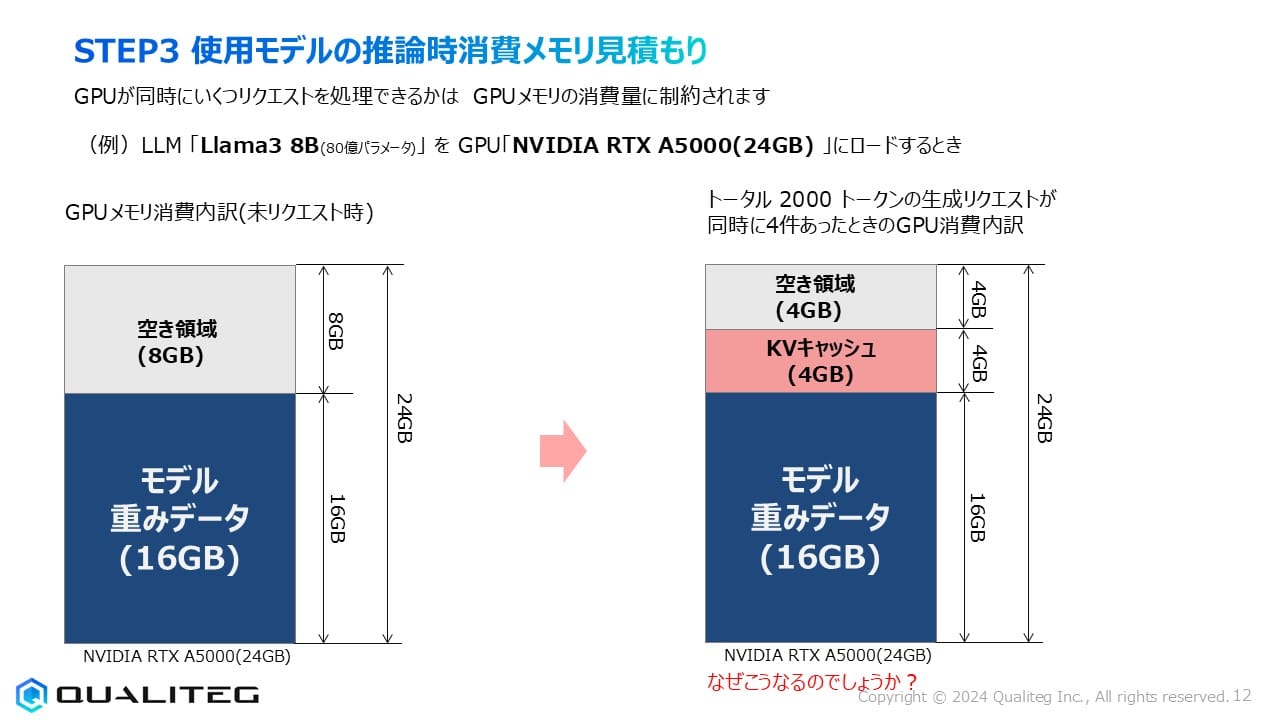
では、その具体例として、Llama3 8B(80億パラメータ)モデルをNVIDIA RTX A5000(24GB)にロードするケースを考えてみましょう。
このGPUには24GBのGPUメモリがありますが、すべてをリクエスト処理に使えるわけではありません。最初にモデル自体が一定量のメモリを消費し、残りの領域で実際のリクエスト処理を行います。
GPUメモリ消費の二大要素
GPUの消費メモリ量は主に以下の2つの要素によって決まります
- モデルのフットプリント
LLMをGPUに読み込んだときに最初に消費されるメモリ量 - KVキャッシュの総量
リクエスト処理中に必要となる一時的なメモリ量
この2つを正確に見積もることで、1台のGPUで同時に処理可能なリクエスト数を算出できます。
3-1 フットプリントとは
フットプリントとは、LLMをGPUに読み込んだときに消費されるGPUメモリの量です。これはモデルの重みパラメータなどを格納するために必要な固定的なメモリ使用量です。

フットプリントの計算方法
フットプリントは以下の式で計算できます
フットプリント(GB) = モデルサイズ(B) × バイト単位の精度
ここで「バイト単位の精度」とは、モデルの量子化ビット数によって決まる値です
| 量子化ビット数 | フォーマット | 精度 | 備考 |
|---|---|---|---|
| 32ビット | FP32 | 4 | 学習時精度、標準利用 |
| 16ビット | FP16, BF16 | 2 | 標準(半精度)利用 |
| 8ビット | INT8, FP8 | 1 | メモリ資源量を減らしたいとき精度を犠牲にして使用 |
| 4ビット | INT4, FP4 | 0.5 | メモリ使用量を極力減らしたいとき精度を犠牲にして使用 |
例えば、Llama3 8Bモデル(8B=80億パラメータ)を16ビット精度(半精度)で使用する場合
フットプリント = 8 × 2 = 16GB
となります。この16GBが、モデルをロードした時点で固定的に使用されるメモリ量です。
Llama3 8Bのモデルスペック
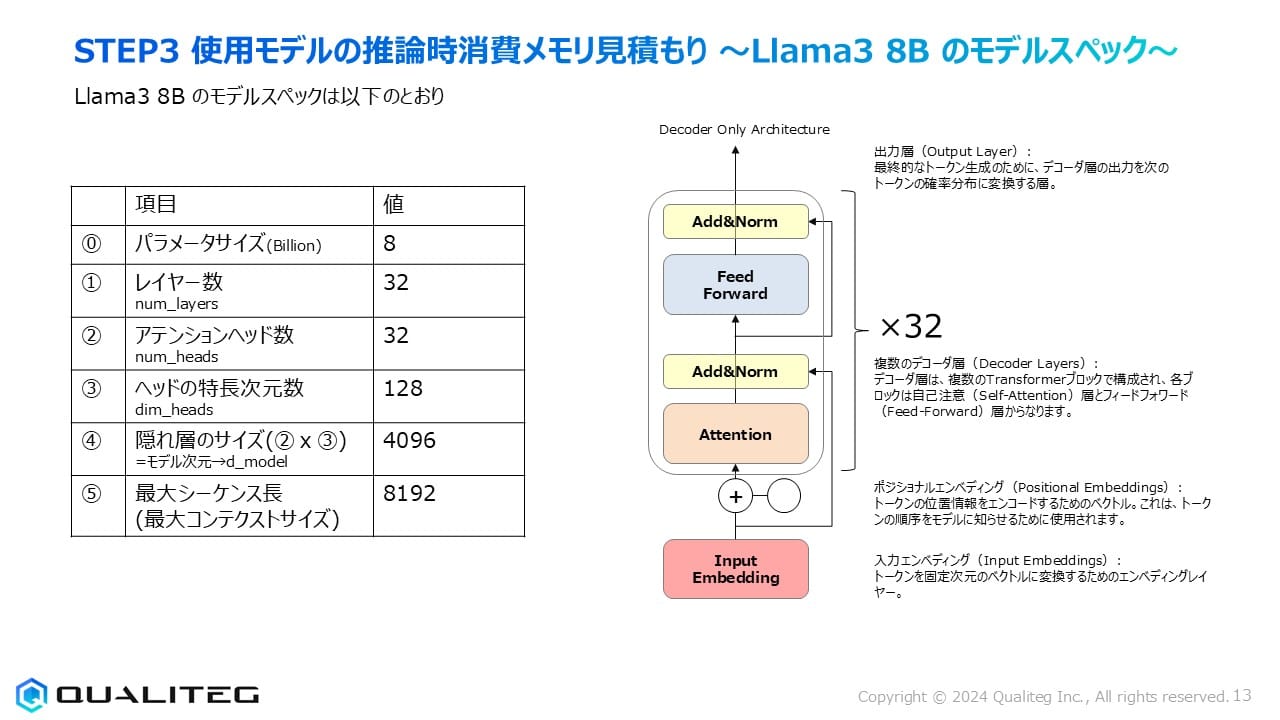
さて、ここで、Llama3 8Bモデルの詳細なスペックを確認しておきましょう
| 項目 | 値 |
|---|---|
| パラメータサイズ(Billion) | 8 |
| レイヤー数(num_layers) | 32 |
| アテンションヘッド数(num_heads) | 32 |
| ヘッドの特長次元数(dim_heads) | 128 |
| 隠れ層のサイズ(②×③) = モデル次元d_model | 4096 |
| 最大シーケンス長(最大コンテクストサイズ) | 8192 |
このモデルはDecoder Onlyアーキテクチャとよばれるもので、32の層(レイヤー)それぞれに自己注意(Self-Attention)層とフィードフォワード(Feed-Forward)層が含まれています。各層の間には正規化(Add & Norm)が適用されています。
出力層(Output Layer)は最終的なトークン生成のために、デコーダ層の出力を次のトークンの確率分布に変換する役割を担っています。また、入力されるトークンの位置情報をエンコードするためのポジショナルエンベディングや、トークンを固定次元のベクトルに変換する入力エンベディングも重要な構成要素です。
まぁ、ここに関しては、いったん、LLMモデルにはこんな種類のパラメータがある、程度を理解しておけばよいとおもいます。
3-2 KVキャッシュとは
KVキャッシュとは、トークン生成時に一時的に必要となるメモリ量です。LLMの推論プロセス中、過去の計算結果を再利用するために保存されるキー(K)と値(V)のベクトルのことで、モデルごとに異なる特性を持ちます。

KVキャッシュの計算方法
1トークンあたりのKVキャッシュは次の式で計算できます
KVキャッシュ(1トークンあたり) = 2 × レイヤー数 × アテンションヘッド数 × ヘッド特徴次元数 × バイト単位の精度
ここで「2」はキー行列と値行列の2つを意味します。
Llama3 8Bモデルを16ビット精度で使用する場合の計算例

KVキャッシュ = 2 × 32 × 32 × 128 × 2 = 524,288 bytes ≒ 0.5 MBytes(1トークンあたり)
つまり、Llama3 8Bモデルでは1トークンあたり約0.5MBのKVキャッシュが必要になります。
実際のGPUメモリ使用状況
NVIDIA RTX A5000(24GB)にLlama3 8B(16ビット精度)をロードした初期状態で考えてみましょう。

- モデル重みデータ:16GB
- 残りの空き領域:8GB
ここで、4人が同時に各2,000トークンの生成リクエストを行った場合を考えると
KVキャッシュの総消費量 = 2,000(トークン) × 4(リクエスト) × 0.5(MBytes) = 4,000 MBytes ≒ 4 GBytes
この4GBのKVキャッシュがモデルの重みデータ(16GB)に加わり、残りの空き領域は4GBとなります。
KVキャッシュ見積もりの重要性
KVキャッシュの見積もりは「ピーク時に各ユーザーが設定したコンテクストサイズごとに生成した値で計算するのが安全」です。例えば、最大コンテクストサイズが2,000トークンの場合、1リクエストあたり約1GBのメモリを消費します。

これを正確に把握することで、1台のGPUで処理可能な同時リクエスト数の上限を知ることができます。
例えばRTX A5000(24GB)では、モデル自体(16GB)を除いた残り8GBの領域で、各1GBを消費するリクエストを最大8件同時に処理できる計算になります。ただし実際には安全マージンを考慮して、少し余裕を持たせた設計が望ましいでしょう。
コンテクストサイズ(コンテクストウィンドウ)とは、LLMがトークンを記憶できる容量のことで、LLMサービス側で「コンテクストサイズ < モデルの最大シーケンス長」の範囲で設定します。Llama3 8Bの場合、最大シーケンス長は8,192トークンなので、それより小さい値でサービスのコンテクストサイズを設定することになります。
量子化による最適化
GPUメモリを効率的に使用するための一つの手法が「量子化」です。例えば、Llama3 8Bモデルを標準的な16ビット精度(FP16)ではなく、8ビット精度(INT8)に量子化すると、モデルのフットプリントは16GBから8GBに半減します。さらに4ビット精度に量子化すれば4GBまで削減できます。
ただし、量子化によってモデルの精度が犠牲になるトレードオフがあります。重要なのは、サービスの要件(応答品質と速度)とコスト効率のバランスを見極めることです。一般的には、16ビット精度が標準的な選択肢ですが、メモリ効率を優先する場合は8ビットや4ビットの量子化も検討価値があります。
今回のまとめ
今回は、LLMモデルの推論時に消費されるGPUメモリの見積もり方法について、特にモデルのフットプリントとKVキャッシュの計算に焦点を当てて解説してきました。
理論値としてのKVキャッシュ計算
本章で紹介したKVキャッシュの計算方法は、基本的な理論値に基づいたものです。具体的には、以下の計算式でKVキャッシュのサイズを見積もりました
KVキャッシュ(1トークンあたり) = 2 × レイヤー数 × アテンションヘッド数 × ヘッド特徴次元数 × バイト単位の精度Llama3 8Bの例では、1トークンあたり約0.5MBのKVキャッシュが必要という計算結果となり、2,000トークンのコンテクストでは1リクエストあたり約1GBのメモリ消費になることを確認しました。
しかし、この計算はあくまで「最適化を施していない素朴な実装」を前提としたものです。実際の本番環境では、このような単純な実装ではなく、さまざまなメモリ効率化技術が適用されます。
最新推論エンジンのメモリ効率化技術
最新のLLM推論エンジン、特にvLLMや TensorRT-LLM、DeepSpeedなどでは、以下のようなメモリ効率化技術がもりもりと実装されており、理論値の数分の1のメモリで快適にLLMが動作するようになっています
1. ページング方式のKVキャッシュ管理
vLLMの最も革新的な機能の一つは、「ページング方式」のKVキャッシュ管理です。従来の実装では連続したメモリブロックを各リクエストに割り当てていましたが、vLLMではメモリを「ページ」と呼ばれる小さな単位に分割し、必要なページだけを保持する仕組みを導入しています。これにより、メモリの断片化を減らし、利用効率を大幅に向上させています。
詳しくはこちらのブログ「LLM サービング効率化の為のPagedAttention」にて解説しています

2. 動的なKVキャッシュ割り当て
最新の推論エンジンでは、固定サイズのメモリブロックを各リクエストに事前割り当てするのではなく、実際に使用されるコンテクスト長に応じて動的にメモリを割り当てる手法が採用されています。これにより、短いメッセージのやり取りが主体のチャットサービスなどでは、メモリ使用効率が大幅に向上します。
3. Attention Maskの最適化
長いコンテクストの場合、すべての過去トークンが現在の生成に同等に重要なわけではありません。一部の推論エンジンでは、注意マスクを最適化し、重要度の低い過去コンテキストのKVキャッシュをGPUメモリから解放して、CPU側に一時保存するプルーニング技術も導入されています。
4. 量子化技術の進化
モデルのパラメータだけでなく、KVキャッシュ自体も量子化する技術が進んでいます。例えば、生成中のKVキャッシュを8ビットや4ビットに動的に量子化することで、精度をある程度維持しながらもメモリ消費を大幅に削減できます。
5. GPU-CPU連携メモリ管理
大規模なコンテクストを扱う場合、一部のKVキャッシュをCPUメモリに退避させ、必要なときだけGPUに再ロードするCPU-GPUのメモリオフロードアプローチも採用されています。
現実的なGPUメモリ消費の見積もり
このような最適化技術を適用した場合、実際のGPUメモリ消費量は本章で計算した理論値よりも大幅に少なくなることがあります。例えば、vLLMを使用した場合、同じRTX A5000(24GB)のGPUで、理論上4リクエストしか同時処理できないケースでも、最適化により12〜20件の同時リクエスト処理が可能になることも珍しくありません。
ただし、こうした最適化の効果は使用するモデル、コンテクスト長、リクエストパターンなどによって大きく異なるため、実際の環境での検証が不可欠です。
次回の展望
今回のKVキャッシュ計算は「原理原則を理解するための基礎」として押さえておくことが重要です。これを土台として、次回のSTEP4「推論エンジン選定」では、vLLM、TensorRT-LLM、DeepSpeed ZERO Inferenceなど、さまざまな推論エンジンの比較と選定基準について詳しく解説していきます。
推論エンジンの選択は、単なる実行速度だけでなく、メモリ効率、スケーラビリティ、対応モデル、導入の容易さなど、多面的な視点から検討する必要があります。とりわけ、サービスの規模や要件に応じて最適な推論エンジンが異なるという点にも注目していきます。
それでは、次回またお会いしましょう!
LLM/AIセキュリティのことなら株式会社Qualiteg
私たちQualitegは、LLMの推論・サービング基盤を実際に設計してきたエンジニアリングチームを有しており推論エンジンを単なる箱として扱わず、アテンション計算やKVキャッシュの挙動など深い知見をベースにしたローカルLLM技術のご支援を提供しています。「VRAMに収まる構成はどこか」「vLLMとHugging Face、判断軸は何か」「既存モデルを自社ドメインへ適応させる最短経路は」「オープンLLMと商用LLMの使い分け」「セキュアなローカルLLM構成はどうすればいいか」「ローカルLLMとGPUの選び方」「GPUデータセンターの需要と市場予測」「AI市場予測」などコア技術からAI市場分析まで、お気軽にご相談くださいませ。



