
[自作日記10] マザーボードにCPU、メモリ、SSDを装着する
![[自作日記10] マザーボードにCPU、メモリ、SSDを装着する](/content/images/size/w1200/2024/04/gpu_machine_jisaku_10.png)
マザーボードまわりをセットアップしていきます
1.マザーボード 開封の儀
今回購入したマザーボードは 【ASRock Z690 Steel Legend WiFi 6E/D5】です。
早速開封していきましょう!
箱をあけると、ケーブル類とマニュアル類が上段の小箱にはいっています。

つぎに、中箱をあけます。

おーマザーボードが見えてきました
美しい!

ワクワクしてきました~
写真左側中央部は LGA 1700 ソケットにカバーがかかった状態です。ここにCPUを設置します。
また LGA 1700 ソケットの上側にはメモリモジュールを挿入する DDR5 のメモリスロット4つがみえます。
そして水平中央付近に SSD を設置する M.2 スロットがあります。(写真ではヒートシンクがありますが、その下にスロットがあります)
そこからやや右側にグラボを挿す PCI Express x16 スロットがあります。
ざっとこんな感じで主要部品を設置していきましょう。

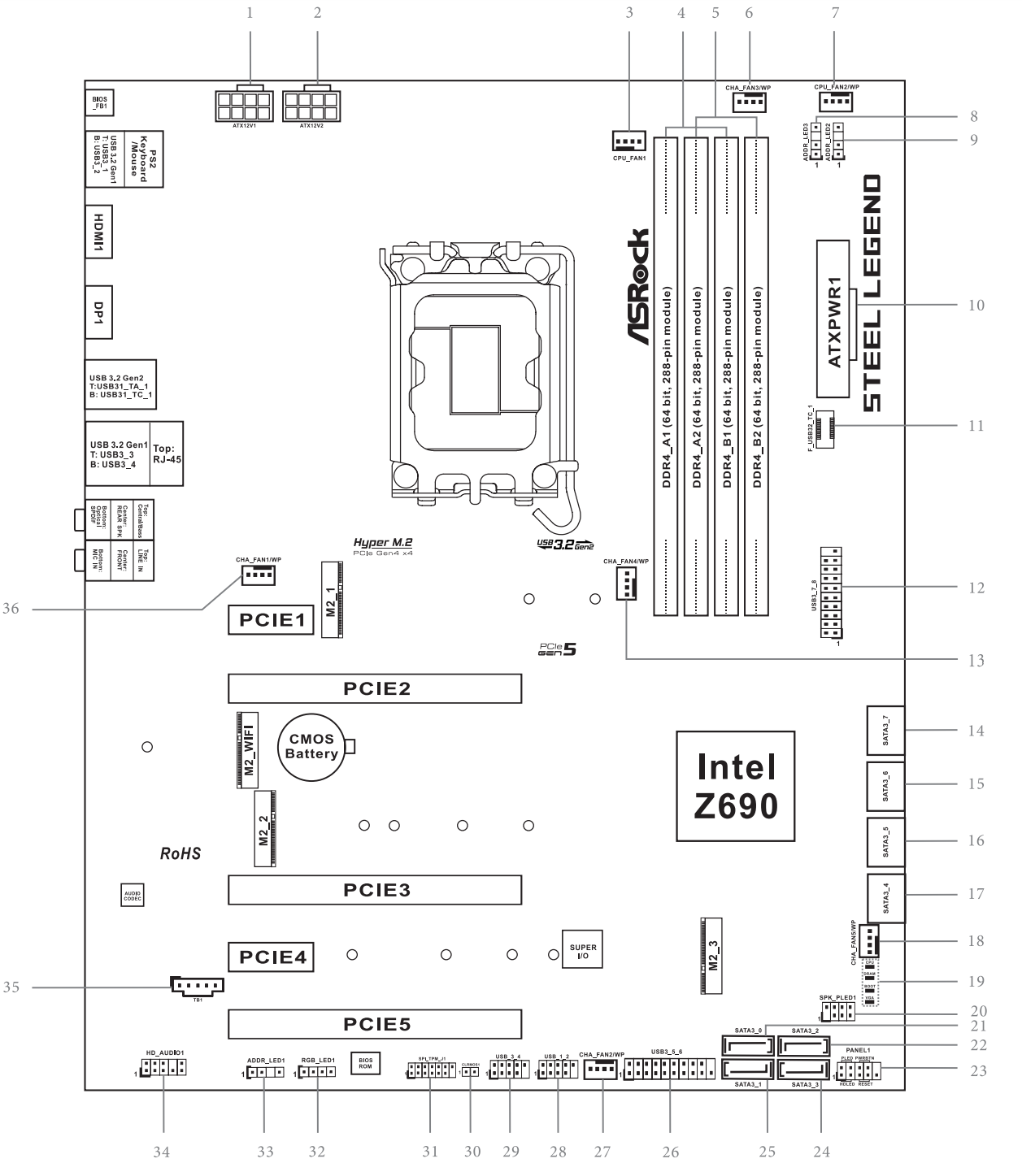
2.マザーボードの配線図はあらかじめ印刷しておくと便利
付属のマニュアルに配線図がついているのですが、可能であれば、マザーボードのピン配置などが掲載された配線図は拡大コピーしたりして1枚の紙に印刷しておくと組み立ての時便利です。
マニュアルのページをめくっておくよりも1枚の紙に印刷して手元に置いておいた方が便利、というわけです。
3.マザーボードにCPUを装着
早速、組み立て作業です!
どのパーツもとても繊細なので、静電気防止機能+滑り止め機能のある手袋をつけて作業します。

それでは、CPUを開梱します。
CPUは インテル12世代Coreシリーズの Intel Core i7 12700 です。

CPU本体とリテールファンが付属しています

マザーボードを箱からとりだし、やわらかい絶縁マットの上に置きます。
LGA-1700 スロットには最初カバーがかかっているため、ストッパーを外します

ストッパーを押しずらしてはずして、カバーを取り外します

先ほど開梱したCPUを保護ケースから取り出します

開いている LGA 1700 スロットにCPUを設置します。切り欠きを確認して、向きを間違えないように、設置したらストッパーを再び閉じます

ちなみに、CPUファンはまだ装着しません。
なぜなら、ファンは大きいので先に装着してしまうと、メモリ等の装着の際にジャマになるためです。
4.メモリの装着
次にメモリを装着していきます。
この4つ並んでいるのがメモリスロットでここに1枚ずつメモリを挿入します
まず最初に、ロックレバーを開いておきます

メモリモジュールをパッケージから取り出しましょう。今日使っているメモリは Crucial デスクトップ用 DDR5 32G x 2です。

そこに、メモリモジュールを挿し込みます。
方向を間違えないようにきをつけます。
もし軽く押してみて抵抗があるようなら、向きをみましょう。
反対にしてみても抵抗がある場合、規格が違うことも疑います。
たとえば マザーボードが DDR5 のメモリモジュールを求めているのに DDR4 のメモリモジュールを買ってしまった場合など、DDR4は物理的に挿し込めないようになっていますので、無理に力を入れて挿そうとするとマザーボードやメモリが壊れてしまうので気を付けましょう。

今回は、何も考えずに1番スロットと2番スロットに挿してしまいましたが、どこに挿すのがよいのかはマザーボードのマニュアルを確認する必要があります。
2枚のメモリモジュールを挿す場合、多くのマザーボードでは、1番スロットと3番スロット または 2番スロットと4番スロットのように1スロットとばして挿すとメモリ読み書きの効率が良いとマニュアルに書いてあります。
4.SSDの装着
次にSSDを装着していきます。開梱すると、このようなSSDが出てきます。
今回買ったSSDはSAMSUNG 980 PRO 2T M.2 NVMeでヒートシンクつきのモデルです。

M.2 用のSSDにはヒートシンクつきと、ヒートシンク無しのものがありますが、今回のマザーボード 【ASRock Z690 Steel Legend WiFi 6E/D5】 には M.2 Armor という評判の良いM.2 用のヒートシンクが標準で用意されています。
今回はヒートシンクつきのSSD を購入したので、マザーボード標準搭載のヒートシンクはドライバーでネジをはずして取りはずすことにします。

マザーボードの標準のデザインが気に入っている人はヒートシンク無しのSSDを購入するのもありですね。
このとおり、標準装備されていた M.2 用ヒートシンクをはずすと、M.2スロットが姿をあらわします。

M.2 スロットに SSD を挿して、


これで SSD の装着が完了です
5.CPUファンの装着
CPUファンを取り付けましょう。
今回とりつけるのは、CPUに付属している「リテールファン」です。

CPUのまわりにある4つの穴に、ファンのピンが入るように把持し、

ピン先が穴にふれたら、ピンの上部をカチっとなるまで押し入れます。

次に、CPUファンの電源コネクタをマザーボードの CPU FAN 用ジャンパー差します。マザーボード上に CPU FAN1 と書いてありますね

次回は、マザーボードをケースに設定してからの組み立て作業を行っていきたいと思います!
navigation



