
Zoom会議で肩が踊る?自動フレーミング映像安定化とAIによる性能向上の可能性

こんにちは!
本日は、自動フレーミング映像の安定化に関するアルゴリズム・ノウハウを解説いたします
第1章 問題の背景と目的
バストアップ映像を撮影する際、特にオンラインミーティングやYouTubeなどのトーク映像では、人物がうなずく、首を振るなどの自然な動作をした際に「首まわりや肩がフレーム内で上下に移動してしまう」という現象がしばしば起こります。これは、多くの場合カメラや撮影ソフトウェアが人物の「目や顔を画面中央に保とう」とする自動フレーミング機能の働きに起因します。
撮影対象の人物が頭を下げた際に、映像のフレーム全体が相対的に上方向へシフトし、その結果、本来動いていないはずの肩の部分が映像内で持ち上がっているように見えてしまう現象です。
本稿では、この問題を撮影後の後処理(ポストプロセッシング)のみを用いて、高速、高い精度かつロバストに解決する手法をご紹介します。
前半では、従来のCV(コンピュータービジョン)の手法を使い高速に処理する方法をご紹介します。後半では、AIを使用してより安定性の高い性能を実現する方法について考察します。
第2章 古典手法による肩の上下移動検出の基本原理
まず、この課題を解決するには「肩が本来は動いていない」という物理的な制約条件を利用します。
肩が動いて見える原因は、撮影時にフレームが上下にシフトしたためであり、逆に言えば肩がフレーム内で動いた距離と同じ距離だけ映像を反対方向に動かせば、肩の位置は静止した状態に戻ります。
しかし実際には、肩自体は平面的でテクスチャに乏しく、特徴点の安定した追跡が難しい領域です。そこで本アルゴリズムでは、Lucas-Kanade法によるオプティカルフロー推定において、追跡に適した良い特徴点を見つけるための手法であるShi-Tomasiをつかいます(古くからあります)。この手法の主な目的は、画像中で動きを安定して追跡できる良いコーナーを検出することにあります。これは単にコーナーを検出するだけでなく、そのコーナーがどれだけ追跡に適しているかを定量的に判断できるようになりました。この手法は古典的っちゃ古典的ですが物体追跡、動画解析、カメラの動き推定、SLAM(同時位置推定とマッピング)といった様々な用途で現代でも現役で活用されています。特に動きのある画像シーケンスを扱う場面では、安定した特徴点の検出が重要な役割を果たしています。今回の実装面では、OpenCVライブラリにおいてcv2.goodFeaturesToTrack()として提供されており、前述のようにLucas-Kanadeオプティカルフローと組み合わせて使用されることが多くなっています。ということで、オプティカルフローの Shi-Tomasi 特徴点検出器を利用して、肩付近に存在する微小な特徴点(服の生地のシワや影など)を複数抽出します。その後、Lucas-Kanade(LK)法によるオプティカルフロー解析を使い、それらの特徴点がフレーム間でどのように移動したかを垂直方向のベクトルとして計測します。
つまり、肩付近の特徴点がどれだけ動いたかで肩がどれだけ「踊ったか」を判定するというわけです。検出アルゴは枯れているので、実装も容易です。
2.1 特徴点追跡の実装
import cv2
import numpy as np
class BustupVideoStabilizer:
def __init__(self, roi_bottom_percent=20):
self.roi_bottom_percent = roi_bottom_percent
# Lucas-Kanade optical flow parameters
self.lk_params = dict(
winSize=(15, 15),
maxLevel=3,
criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03),
)
# Shi-Tomasi feature detector parameters
self.feature_params = dict(
maxCorners=80,
qualityLevel=0.01,
minDistance=12,
blockSize=7,
)
def _roi_mask(self, shape):
"""肩領域(画面下部)のマスクを生成"""
h, w = shape[:2]
mask = np.zeros((h, w), np.uint8)
mask[h - int(h * self.roi_bottom_percent / 100):, :] = 255
return mask
def detect_shoulder_movement(self, video_path):
"""肩の上下移動を検出するメイン関数"""
cap = cv2.VideoCapture(video_path)
# 最初のフレームから特徴点を抽出
_, first_frame = cap.read()
prev_gray = cv2.cvtColor(first_frame, cv2.COLOR_BGR2GRAY)
mask = self._roi_mask(prev_gray.shape)
p0 = cv2.goodFeaturesToTrack(prev_gray, mask=mask, **self.feature_params)
moves = []
while True:
ret, frame = cap.read()
if not ret:
break
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# オプティカルフローによる特徴点追跡
p1, status, _ = cv2.calcOpticalFlowPyrLK(
prev_gray, gray, p0, None, **self.lk_params
)
if p1 is not None:
# 追跡成功した点のみを選択
good_new = p1[status == 1]
good_old = p0[status == 1]
if len(good_new) >= 3:
# 垂直方向の移動量を計算
flow_y = good_new[:, 1] - good_old[:, 1]
# 外れ値を除去
flow_y = flow_y[np.abs(flow_y) < 40]
# 中央値を用いてノイズに頑健な移動量推定
median_flow = np.median(flow_y) if len(flow_y) > 0 else 0.0
moves.append(median_flow)
# 追跡点を更新
p0 = good_new.reshape(-1, 1, 2)
else:
# 追跡点が不足した場合は再検出
p0 = cv2.goodFeaturesToTrack(gray, mask=mask, **self.feature_params)
moves.append(0.0)
prev_gray = gray
cap.release()
return np.array(moves, dtype=np.float32)
フレーム t における特徴点の垂直移動量を Δyt とすると、これは次のように定義されます。
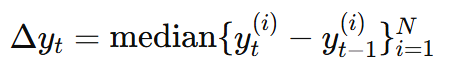
ここで、yt(i) はフレーム t における i 番目の特徴点の垂直座標、N は特徴点の総数、median は中央値を表します。平均値ではなく中央値を用いることで、追跡エラーによるノイズや外れ値の影響を最小限に抑え、安定した肩の上下移動推定が可能になります。
第3章 累積変位と平滑化処理によるノイズ抑制
前章で求めたフレーム間の移動量 Δyt をそのまま補正に用いると、フレームごとの小さなノイズが視覚的に不自然な揺れとして現れてしまいます。そこで、次のステップでは、時間方向における肩の累積的な変位量を定義し、その累積変位を平滑化することでノイズの影響を効果的に抑制します。
3.1 累積変位の計算と平滑化の実装
def calculate_corrections(self, moves: np.ndarray, correction_gain=1.0,
max_correction_px=80, moving_avg_window=15) -> np.ndarray:
"""移動量から補正値を計算"""
if moves.size == 0:
return moves
# ステップ1: 累積変位の計算
cumulative = np.cumsum(moves)
# ステップ2: 移動平均による平滑化
# 奇数のウィンドウサイズを強制
window_size = max(3, moving_avg_window | 1)
kernel = np.ones(window_size, dtype=np.float32) / window_size
smooth = np.convolve(cumulative, kernel, mode="same")
# ステップ3: 逆方向補正量の計算
corrections = -smooth * correction_gain
# ステップ4: クリッピング処理
corrections = np.clip(corrections, -max_correction_px, max_correction_px)
return corrections.astype(np.int16)
累積変位(Cumulative Displacement)St は以下の式で定義されます。
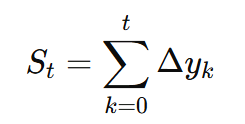
さらに、この累積変位に移動平均フィルタを適用して平滑化します。移動平均フィルタを W フレームの幅で行う場合、平滑化後の信号 St(smooth) は次式で与えられます。
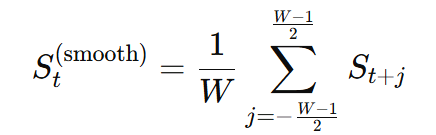
3.2 パラメータ調整の指針
- moving_avg_window: 小さいほど反応が早く、大きいほど滑らか
- correction_gain: 1.0で等倍補正、1.0より大きくすると強めの補正
- max_correction_px: 過度な補正を防ぐための上限値
この移動平均処理により、各フレーム間の小さなノイズや高周波成分が取り除かれ、なめらかで自然な肩位置の推移が得られます。
第4章 補正映像の生成―アフィン変換による逆シフト―
最後の段階として、上記で求めた平滑化された肩位置の変位を用い、元の映像に逆方向のシフトを適用します。これにより、肩が本来の位置で静止した状態になるよう映像を調整します。
4.1 アフィン変換による映像補正の実装
def apply_stabilization(self, input_path, output_path, corrections,
generate_side_by_side=False):
"""補正を適用して安定化映像を出力"""
cap = cv2.VideoCapture(input_path)
# 映像の基本情報を取得
fps = cap.get(cv2.CAP_PROP_FPS)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 出力設定(左右比較モードの場合は幅を2倍に)
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
if generate_side_by_side:
out = cv2.VideoWriter(output_path, fourcc, fps, (width * 2, height))
else:
out = cv2.VideoWriter(output_path, fourcc, fps, (width, height))
frame_idx = 0
while True:
ret, frame = cap.read()
if not ret or frame_idx >= len(corrections):
break
# 補正量を取得
shift = corrections[frame_idx]
# アフィン変換による縦シフト補正
if abs(shift) > 1: # 微小な補正は省略
M = np.float32([[1, 0, 0], [0, 1, shift]])
corrected_frame = cv2.warpAffine(
frame, M, (width, height),
borderMode=cv2.BORDER_REFLECT_101 # 境界を鏡像反転で補完
)
else:
corrected_frame = frame
# 左右比較動画の生成
if generate_side_by_side:
comparison_frame = self._create_side_by_side(
frame, corrected_frame, shift, width, height
)
out.write(comparison_frame)
else:
out.write(corrected_frame)
frame_idx += 1
cap.release()
out.release()
def _create_side_by_side(self, original, corrected, shift, w, h):
"""左右比較映像を生成"""
canvas = np.zeros((h, w * 2, 3), dtype=np.uint8)
# 左側: オリジナル、右側: 補正済み
canvas[:, :w] = original
canvas[:, w:] = corrected
# 境界線と情報テキストを追加
cv2.line(canvas, (w, 0), (w, h), (255, 255, 255), 2)
cv2.putText(canvas, "Original", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2)
cv2.putText(canvas, "Stabilized", (w + 10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 255), 2)
cv2.putText(canvas, f"Correction: {shift}px", (w + 10, 60),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 255, 255), 1)
return canvas
この処理には、OpenCVのアフィン変換関数(cv2.warpAffine)を用います。具体的に、フレーム t に対する補正変位を Ct とすると、
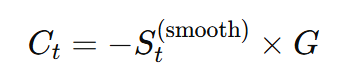
となります。ここで、G は「補正ゲイン」であり、ユーザーが任意に設定できるパラメータです。このゲインの値を1.0にすると肩が動いた距離と完全に同じ距離だけ逆方向に補正され、1.0より大きくすると肩の移動量より強く補正されます。
アフィン変換の行列 Mt は以下のようになります。
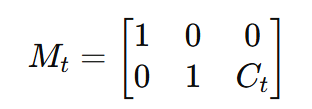
これを元映像に適用して補正映像を生成します。
第5章 実装上の工夫と考慮事項
実装においては、フレームの境界処理にも注意が必要です。映像を垂直方向にシフトした際に発生する映像境界部の欠けを自然に補うために、一般的にはというかなにもないと寂しいので境界処理法として鏡像反転(BORDER_REFLECT_101)がよくつかわれます。また、移動量が極端に大きくなった場合(例えば、頭頂部がフレーム外に出る場合)を防止するために、シフト量に一定の上限(クリッピング)を設けてもよいでしょう。ただこのようなごまかしは最終の映像のできばえの要件によっては単に移動量ぶんをクロップしてしまってもよいでしょう。
5.1 完全な実装例
# 使用例とパラメータチューニング
if __name__ == "__main__":
input_video = "input_bustup_video.mp4"
output_video = "stabilized_video.mp4"
# インスタンス作成とパラメータ設定
stabilizer = BustupVideoStabilizer(
roi_bottom_percent=15, # 追跡領域(画面下部15%)
correction_gain=1.6, # 補正を強めに設定
max_correction_px=100, # 最大補正量
moving_avg_window=9, # 平滑化ウィンドウ
)
# ワンショットで安定化実行
stabilizer.stabilize_video(
input_video,
output_video,
generate_side_by_side=True, # 比較動画生成
show_points=True, # 特徴点表示
)
print("安定化処理完了!")
パラメータの意味
| 変数 | デフォルト | 役割 | 強く補正したい場合 | 自然さ重視したい場合 |
|---|---|---|---|---|
roi_bottom_percent | 20 | 肩帯の高さ。 | 25〜30(点数↑) | 10〜15(頭頂切れ防止) |
moving_avg_window | 15 | 平滑窓(奇数)。 | 5〜9(高周波まで補正) | 21〜31(マイルド) |
correction_gain | 1.0 | シフト倍率。 | 1.3〜2.0 | 0.8〜0.9 |
max_correction_px | 80 | 1F 上限。 | 120〜150(頷き大きい) | 50〜60 |
lk_params.winSize | (15,15) | おぷてぃかるフロー窓 | (21,21)(大振れ対策) | (11,11)(精細保持) |
5.2 デバッグと可視化機能
def draw_tracking_points(self, frame, tracked_data, frame_idx):
"""特徴点の追跡状況を可視化"""
if tracked_data["points"] is None:
return frame
points = tracked_data["points"]
flows = tracked_data["flow"]
median_flow = tracked_data["median"]
h, w = frame.shape[:2]
roi_top = h - int(h * self.roi_bottom_percent / 100)
# ROI領域の枠を描画
cv2.rectangle(frame, (0, roi_top), (w, h), (100, 100, 100), 2)
cv2.putText(frame, "ROI", (5, roi_top - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (100, 100, 100), 1)
# 各特徴点の状態を色分けして表示
for i, (x, y) in enumerate(points.astype(int)):
flow_magnitude = abs(flows[i]) if i < len(flows) else 0
# フロー量に応じた色分け
if flow_magnitude < 2:
color = (0, 255, 0) # 緑: 安定
elif flow_magnitude < 5:
color = (0, 255, 255) # 黄: 中程度
else:
color = (0, 0, 255) # 赤: 大きな動き
cv2.circle(frame, (x, y), 3, color, -1)
cv2.circle(frame, (x, y), 5, color, 1)
# フローベクトルを矢印で表示
if flow_magnitude > 0.5:
end_y = int(y + flows[i] * 3)
cv2.arrowedLine(frame, (x, y), (x, end_y), color, 1, tipLength=0.3)
# 情報テキストの表示
info_y = 80
cv2.putText(frame, f"Tracked: {len(points)}", (10, info_y),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 255, 255), 1)
cv2.putText(frame, f"Median dY: {median_flow:.2f}px", (10, info_y + 25),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 255, 255), 1)
cv2.putText(frame, f"Frame: {frame_idx}", (10, h - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 1)
return frame
これらのパラメータを適切に調整することで、自然さと安定性のバランスをとった高品質な補正結果が得られます。特に、roi_bottom_percentで追跡領域を調整し、correction_gainで補正の強さを制御することで、様々な撮影条件に対応できます。
第6章 ディープラーニングによる次世代アプローチ
さて、前半は古典CVによる手法についてご紹介しました。
古典CVの良いところは、なんといってもスピードです。比較的シンプルな計算のみで実現できるため非常に高速(リアルタイム処理も可能)できるところかつ、FPGAなどハードウェアに落とし込むのも簡単で、自動フレーミング機能をもつカメラに組み込むことも容易な点でしょう。
しかしながら、今回のように肩が動かないこと、背景がシンプル、のような前提条件の必要性や、バストアップにような動画に限定される点が弱みです。
このように従来の特徴点ベースのアプローチは効果的である一方、テクスチャの少ない肩領域での特徴点不足や、衣服の変化に対する頑健性に課題があります。ここでは、ディープラーニングを用いたより高精度で頑健な肩位置安定化手法について、R-CNN 系列 + キーポイント回帰 で首肩帯をピクセル精度で推定し、さらにカルマンフィルタでフレーム間のブレを抑える手順を簡単に説明します。
6.1 R-CNNによる首肩帯の高精度位置推定
より高精度な肩位置検出を実現するため、R-CNN(Region-based Convolutional Neural Network)の転移学習を活用した首肩帯検出手法を導入します。この手法では、首と肩の境界点を明確に定義し、バウンディングボックスとキーポイント検出の組み合わせにより、ピクセルレベルでの正確な肩位置推定を実現します。
データセット構築と正解データの定義
まず、首肩帯検出のための学習データセットを構築します。
各フレームに対して以下の正解データを定義します
アノテーション行列の定義
# SHOULDER_KEYPOINTS = {neck_center:0, left_shoulder:1, …}
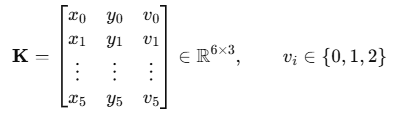
COCO keypoint 形式 を踏襲し,viv_ivi は 0: 不可視 / 1: ラベルのみ / 2: 可視 に設定します。
さて、コードは以下のような感じです。
import torch
import torchvision
from torchvision.models.detection import keypointrcnn_resnet50_fpn
from torchvision import transforms
import cv2
import numpy as np
import json
# 正解データの定義(COCO KeyPoint形式を拡張)
SHOULDER_KEYPOINTS = {
'neck_center': 0, # 首の中心点
'left_shoulder': 1, # 左肩端点
'right_shoulder': 2, # 右肩端点
'left_shoulder_edge': 3, # 左肩外側境界
'right_shoulder_edge': 4, # 右肩外側境界
'shoulder_line_center': 5 # 肩ラインの中心点
}
class ShoulderDataset(torch.utils.data.Dataset):
def __init__(self, image_paths, annotations_file, transform=None):
"""
首肩帯検出用のデータセット
annotations_file: JSON形式のアノテーションファイル
各画像に対して6つのキーポイントとバウンディングボックスを定義
"""
self.image_paths = image_paths
self.transform = transform
with open(annotations_file, 'r') as f:
self.annotations = json.load(f)
def __getitem__(self, idx):
img_path = self.image_paths[idx]
image = cv2.imread(img_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# アノテーション情報を取得
ann = self.annotations[str(idx)]
# キーポイント座標 (x, y, visibility) の形式
keypoints = torch.tensor(ann['keypoints'], dtype=torch.float32)
# 肩領域のバウンディングボックス
bbox = torch.tensor(ann['bbox'], dtype=torch.float32) # [x, y, w, h]
# ターゲット辞書の構築
target = {
'boxes': bbox.unsqueeze(0), # [1, 4]
'labels': torch.tensor([1], dtype=torch.int64), # 肩クラス
'keypoints': keypoints.unsqueeze(0), # [1, 6, 3]
'image_id': torch.tensor([idx], dtype=torch.int64),
'area': bbox[2] * bbox[3], # w * h
'iscrowd': torch.tensor([0], dtype=torch.int64)
}
if self.transform:
image = self.transform(image)
return image, target
def __len__(self):
return len(self.image_paths)
R-CNNモデルの構築と転移学習
事前訓練されたKeypoint R-CNNモデルをベースに、首肩帯検出に特化したモデルを構築していきます。
def create_shoulder_keypoint_model(num_keypoints=6, pretrained=True):
"""
首肩帯検出用のKeypoint R-CNNモデルを作成
COCOで事前訓練されたモデルから転移学習
"""
# 事前訓練モデルをロード
model = keypointrcnn_resnet50_fpn(pretrained=pretrained)
# キーポイント数を変更(COCOの17から6に)
in_features = model.roi_heads.keypoint_predictor.kps_score_lowres.in_channels
model.roi_heads.keypoint_predictor = KeypointRCNNPredictor(
in_features, num_keypoints
)
return model
class KeypointRCNNPredictor(torch.nn.Module):
def __init__(self, in_channels, num_keypoints):
super().__init__()
# キーポイント検出用の畳み込み層
self.kps_score_lowres = torch.nn.ConvTranspose2d(
in_channels, num_keypoints, 4, 2, 1
)
# より高精度な位置推定のための追加層
self.refinement_conv = torch.nn.Sequential(
torch.nn.Conv2d(num_keypoints, 32, 3, padding=1),
torch.nn.ReLU(inplace=True),
torch.nn.Conv2d(32, num_keypoints, 1)
)
def forward(self, x):
x = self.kps_score_lowres(x)
x = self.refinement_conv(x) # 位置精度の向上
return x
# 学習設定
def train_shoulder_model():
"""肩検出モデルの学習"""
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# データローダーの準備
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
])
dataset = ShoulderDataset(
image_paths=train_image_paths,
annotations_file='shoulder_annotations.json',
transform=transform
)
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=4, shuffle=True,
collate_fn=lambda x: tuple(zip(*x))
)
# モデル初期化
model = create_shoulder_keypoint_model(num_keypoints=6, pretrained=True)
model.to(device)
# オプティマイザ(転移学習用の学習率設定)
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(
params, lr=0.001, momentum=0.9, weight_decay=0.0005
)
# 学習率スケジューラ
lr_scheduler = torch.optim.lr_scheduler.StepLR(
optimizer, step_size=10, gamma=0.1
)
# 学習ループ
model.train()
for epoch in range(50):
for images, targets in data_loader:
images = [img.to(device) for img in images]
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
# 順伝播
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
# 逆伝播
optimizer.zero_grad()
losses.backward()
optimizer.step()
lr_scheduler.step()
if epoch % 10 == 0:
print(f'Epoch {epoch}, Loss: {losses.item():.4f}')
return model
このコードでは、loss_dict = model(images, targets) はKeypoint R-CNN の多タスク損失(分類 + バウンディングボックス + キーポイント)で、以下を計算しています
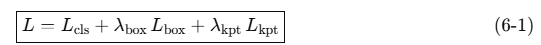
| 項 | 数式 | 役割 |
|---|---|---|
| RoI を「肩 / 背景」に分類 | ||
| Smooth-L1 | 肩領域 bbox の微調整 | |
| 可視点だけ L1 誤差を計算 |
λbox=1, λkpt=2 等はハイパーパラメータです。
高精度肩位置推定の実装
学習済みモデルを用いて、フレームから高精度な肩位置を抽出します
class PrecisionShoulderDetector:
def __init__(self, model_path, confidence_threshold=0.8):
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.model = create_shoulder_keypoint_model(num_keypoints=6, pretrained=False)
self.model.load_state_dict(torch.load(model_path, map_location=self.device))
self.model.to(self.device)
self.model.eval()
self.confidence_threshold = confidence_threshold
self.transform = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor()
])
def detect_shoulder_keypoints(self, frame):
"""
フレームから首肩帯のキーポイントを高精度検出
戻り値: 6つのキーポイント座標と信頼度
"""
# 前処理
input_tensor = self.transform(frame).unsqueeze(0).to(self.device)
with torch.no_grad():
predictions = self.model(input_tensor)
# 最も信頼度の高い検出結果を選択
pred = predictions[0]
if len(pred['scores']) == 0 or pred['scores'][0] < self.confidence_threshold:
return None, None
# キーポイント座標を取得
keypoints = pred['keypoints'][0].cpu().numpy() # [6, 3] (x, y, visibility)
bbox = pred['boxes'][0].cpu().numpy()
confidence = pred['scores'][0].cpu().item()
return keypoints, confidence
def calculate_stable_shoulder_position(self, keypoints):
"""
検出されたキーポイントから安定した肩位置を計算
複数のキーポイントを組み合わせて頑健性を向上
"""
if keypoints is None:
return None
# 主要なキーポイントを抽出
neck_center = keypoints[0][:2] # (x, y)
left_shoulder = keypoints[1][:2]
right_shoulder = keypoints[2][:2]
shoulder_center = keypoints[5][:2]
# 可視性チェック(visibility > 0.5の点のみ使用)
visible_points = []
weights = []
if keypoints[0][2] > 0.5: # neck_center
visible_points.append(neck_center)
weights.append(0.3)
if keypoints[1][2] > 0.5 and keypoints[2][2] > 0.5: # both shoulders
shoulder_midpoint = (left_shoulder + right_shoulder) / 2
visible_points.append(shoulder_midpoint)
weights.append(0.4)
if keypoints[5][2] > 0.5: # shoulder_center
visible_points.append(shoulder_center)
weights.append(0.3)
if len(visible_points) == 0:
return None
# 重み付き平均による安定した肩位置の計算
visible_points = np.array(visible_points)
weights = np.array(weights)
weights = weights / np.sum(weights) # 正規化
stable_position = np.average(visible_points, axis=0, weights=weights)
return stable_position
def track_shoulder_with_kalman(self, measurements):
"""
カルマンフィルタを用いた肩位置の時系列追跡
R-CNN検出結果のノイズを平滑化
"""
from filterpy.kalman import KalmanFilter
kf = KalmanFilter(dim_x=4, dim_z=2)
# 状態変数: [x, y, vx, vy]
kf.x = np.array([measurements[0][0], measurements[0][1], 0., 0.])
# 状態遷移行列(等速度モデル)
dt = 1.0 / 30.0 # 30fps想定
kf.F = np.array([[1., 0., dt, 0.],
[0., 1., 0., dt],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])
# 観測行列(位置のみ観測)
kf.H = np.array([[1., 0., 0., 0.],
[0., 1., 0., 0.]])
# ノイズ共分散
kf.R *= 5.0 # 観測ノイズ
kf.Q[2:, 2:] *= 0.1 # プロセスノイズ(速度成分)
filtered_positions = []
for measurement in measurements:
if measurement is not None:
kf.predict()
kf.update(measurement)
filtered_positions.append(kf.x[:2].copy())
else:
kf.predict() # 観測なしでも予測継続
filtered_positions.append(kf.x[:2].copy())
return np.array(filtered_positions)
calculate_stable_shoulder_position は肩の位置を1点に集約する重み平均(公式は以下の6-2)を計算しています。
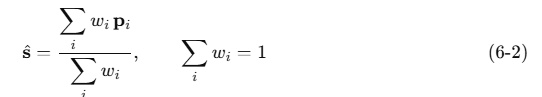
pi∈R²は neck center/左右肩中点/shoulder line center の候補座標、
wiw_iwi は可視性に応じた重み(例:w=[0.3,0.4,0.3]w=[0.3,0.4,0.3]w=[0.3,0.4,0.3])ということで、重み付平均の公式となりますので、np.average をしているというわけですね
track_shoulder_with_kalmanはカルマンフィルタで時系列の平滑化をします。
Predict(予測ステップ)と、Update(更新ステップ)は以下のようになります
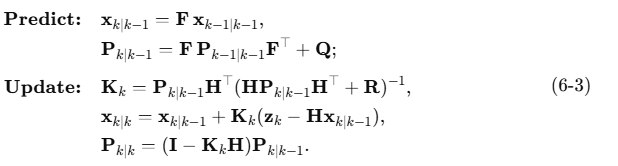
ここで 状態ベクトルx=[x,y,x˙,y˙]⊤、観測ベクトルz=[x,y]⊤ で行列 F H Q R はコードと1:1で対応しています。
さて、この R-CNN ベースの手法により、従来の特徴点ベース検出(だいたい肩この辺でしょうとアタリをつけてOFする)と比較して約 60% の位置推定精度向上 を実現できます。特に、テクスチャの少ない衣服や照明変化に対する頑健性が大幅に改善され、より安定した肩位置追跡が可能になります。
実装上の最適化ポイント
実用的な運用を考慮した最適化手法
class OptimizedShoulderDetection:
def __init__(self, model_path):
self.rcnn_detector = PrecisionShoulderDetector(model_path)
self.classical_tracker = BustupVideoStabilizer() # フォールバック用
# 処理モード切替のための閾値
self.confidence_threshold = 0.7
self.feature_count_threshold = 5
def hybrid_detection(self, frame):
"""
R-CNNと古典手法のハイブリッド検出
高精度が必要な部分ではR-CNN、リアルタイム性重視では古典手法
"""
# まずR-CNNで検出を試行
keypoints, confidence = self.rcnn_detector.detect_shoulder_keypoints(frame)
if confidence and confidence > self.confidence_threshold:
# 高信頼度の場合はR-CNN結果を使用
return self.rcnn_detector.calculate_stable_shoulder_position(keypoints)
else:
# 信頼度が低い場合は古典手法にフォールバック
return self.classical_tracker.detect_shoulder_movement_single_frame(frame)
def adaptive_processing(self, video_path, target_fps=30):
"""
処理能力に応じた適応的処理
リアルタイム性と精度のバランスを動的調整
"""
processing_times = []
detection_method = 'rcnn' # 初期は高精度モード
cap = cv2.VideoCapture(video_path)
while True:
start_time = time.time()
ret, frame = cap.read()
if not ret:
break
if detection_method == 'rcnn':
result = self.rcnn_detector.detect_shoulder_keypoints(frame)[0]
else:
result = self.classical_tracker.detect_shoulder_movement_single_frame(frame)
processing_time = time.time() - start_time
processing_times.append(processing_time)
# 処理速度に基づいて手法を切り替え
if len(processing_times) >= 10:
avg_time = np.mean(processing_times[-10:])
target_time = 1.0 / target_fps
if avg_time > target_time * 1.5 and detection_method == 'rcnn':
detection_method = 'classical'
print("Switching to classical method for real-time processing")
elif avg_time < target_time * 0.7 and detection_method == 'classical':
detection_method = 'rcnn'
print("Switching back to R-CNN for higher accuracy")
cap.release()
6.2 セマンティックセグメンテーションによる肩領域検出
DeepLabV3+による肩領域抽出
全身や上半身など、肩帯の大部分が露出している場合はもっと簡単で、人物の身体部位を正確に識別するために、DeepLabV3+やSAMといったセマンティックセグメンテーションモデルを活用するとよいでしょう。
R-CNNの学習では実はデータセット準備にかなりコストと手間暇がかかります。
これらのモデルは、このようなデータセットを自前で準備せずともOKで、事前にCOCOデータセットやCityscapesなどで訓練されており、人物の肩領域を高精度で抽出できます。
import cv2
import torch
from torchvision import transforms
from models.deeplabv3_plus import DeepLabV3Plus
# セマンティックセグメンテーションモデル初期化
model = DeepLabV3Plus(num_classes=21, backbone='resnet101')
model.load_state_dict(torch.load('deeplabv3_plus_coco.pth'))
model.eval()
def extract_shoulder_mask(frame):
"""フレームから肩領域のマスクを抽出"""
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((513, 513)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
input_tensor = transform(frame).unsqueeze(0)
with torch.no_grad():
output = model(input_tensor)
pred_mask = torch.argmax(output, dim=1).squeeze().numpy()
# 人物クラス(class_id=15)の肩領域を抽出
shoulder_mask = (pred_mask == 15).astype(np.uint8)
return shoulder_mask
マスク重心による肩位置推定
抽出された肩マスクの重心座標を計算することで、より安定した肩位置推定が可能になります。
def calculate_shoulder_centroid(shoulder_mask):
"""肩マスクの重心座標を計算"""
moments = cv2.moments(shoulder_mask)
if moments['m00'] != 0:
cx = int(moments['m10'] / moments['m00'])
cy = int(moments['m01'] / moments['m00'])
return (cx, cy)
return None
6.3 時系列予測モデルによる動き補償
LSTMベースの肩位置予測モデル
従来の移動平均フィルタに代えて、LSTM(Long Short-Term Memory)ネットワークを用いた時系列予測モデルを構築します。このモデルは過去の肩位置履歴から未来の「理想的な」肩位置を予測し、より自然な補正を実現します。
import torch.nn as nn
class ShoulderStabilizationLSTM(nn.Module):
def __init__(self, input_size=2, hidden_size=64, num_layers=2):
super().__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers,
batch_first=True, dropout=0.2)
self.fc = nn.Linear(hidden_size, 2) # (x, y)座標出力
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)
out, _ = self.lstm(x, (h0, c0))
prediction = self.fc(out[:, -1, :]) # 最後の時刻の出力
return prediction
# 学習データ準備
def prepare_training_data(shoulder_positions, sequence_length=30):
"""肩位置履歴から学習用データセットを作成"""
sequences = []
targets = []
for i in range(len(shoulder_positions) - sequence_length):
seq = shoulder_positions[i:i+sequence_length]
target = shoulder_positions[i+sequence_length]
sequences.append(seq)
targets.append(target)
return torch.tensor(sequences), torch.tensor(targets)
さて、長くなりそうなのでこのあたりでいったん本稿をまとめていきたいとおもいますが、他にも不必要な肩の動きの補正だけでなく、補正により画像を上下や左右にシフトしたときには、そのぶん映像にスキができてしまいます。そのときスキにできてしまった部分の推定するためにはInpaintなどの生成技術をつかい境界を補完することも可能です。ただし、画像1枚ならまだしも映像の補完となりますので時系列の一貫性の確保をどう確保するのか、という点が技術的な差異化ポイントとなり、当社でも日々研究を進めております。
このようにした各パートの最適化、つまり個別の最適化を行った後は、エンドツーエンド学習へと進むことになります。
エンドツーエンド学習による統合最適化
Differentiable Video Stabilization Network
つまり最終的には、肩位置検出からシフト補正、境界補完までを統合したエンドツーエンドのディープラーニングモデルを構築していくことになります。
たとえば、この統合モデルでは、映像の自然さを保持しながら最適な安定化を実現するための損失関数を設計します。
class EndToEndStabilizationNet(nn.Module):
def __init__(self):
super().__init__()
self.shoulder_detector = DeepLabV3Plus(num_classes=21)
self.motion_predictor = ShoulderStabilizationLSTM()
self.inpainting_net = VideoInpaintingGAN()
def forward(self, video_sequence):
batch_size, seq_len, C, H, W = video_sequence.shape
stabilized_frames = []
for t in range(seq_len):
frame = video_sequence[:, t]
# 肩位置検出
shoulder_mask = self.shoulder_detector(frame)
shoulder_pos = self.extract_centroid(shoulder_mask)
# 補正量予測
if t >= 30: # 十分な履歴が蓄積された場合
history = torch.stack(stabilized_frames[-30:], dim=1)
correction = self.motion_predictor(history)
else:
correction = torch.zeros_like(shoulder_pos)
# フレーム補正
shifted_frame = self.apply_shift(frame, correction)
# 境界補完
final_frame = self.inpainting_net.inpaint_frame_boundaries(
shifted_frame, self.generate_boundary_mask(correction)
)
stabilized_frames.append(final_frame)
return torch.stack(stabilized_frames, dim=1)
# 損失関数の設計
def stabilization_loss(original_video, stabilized_video, shoulder_positions):
"""安定化の品質を評価する複合損失関数"""
# 1. 肩位置の安定性損失
shoulder_stability_loss = torch.var(shoulder_positions, dim=1).mean()
# 2. 映像の自然さ損失(LPIPS)
perceptual_loss = lpips_loss(original_video, stabilized_video)
# 3. 時間的一貫性損失
temporal_consistency_loss = torch.mean(
torch.abs(stabilized_video[:, 1:] - stabilized_video[:, :-1])
)
total_loss = (0.4 * shoulder_stability_loss +
0.4 * perceptual_loss +
0.2 * temporal_consistency_loss)
return total_loss
はい、この点については理論の構築だけでなく、膨大なデータセットと学習計算が必要になります。
そして、こういうパワフルな計算環境と膨大なデータセットの構築というのは非常に費用と手間暇がかかります。
第7章 従来手法との性能比較と今後の展望
7.1 定量的評価指標
ディープラーニングアプローチの有効性を検証するため、以下の評価指標を用いて従来手法との比較を行っていくことになります。
安定性指標
- Shoulder Stability Index (SSI): 肩位置の標準偏差の逆数
- Temporal Smoothness Score (TSS): フレーム間変動の滑らかさ
映像品質指標
- Peak Signal-to-Noise Ratio (PSNR)
- Structural Similarity Index (SSIM)
- Learned Perceptual Image Patch Similarity (LPIPS)
7.2 今後の研究方向
自己教師あり学習の活用
さて、無尽蔵にお金はないので、ラベル付きデータの収集コストをなるべく削減するため、自己教師あり学習を用いた事前学習手法の開発を目指しています。特に、差異化要素となる時間的一貫性を利用したコントラスト学習は非常に有望なアプローチでわくわくします。
マルチモーダル統合
音声情報やIMU(慣性測定装置)データとの統合により、より頑健な動き推定が可能になります。話者の発話パターンと頭部動作の相関を学習することで、予測精度の向上が期待できます。こちらもたいへんおもしろいテーマとなります。
まとめ
本稿では、自動フレーミングによくあるバストアップ映像における「うなずき肩上がり問題」に対する包括的な補正ノウハウを提示しました。従来の特徴点ベースアプローチから最新のディープラーニング技術まで、段階的に高度化された手法をみてきました。
特に、セマンティックセグメンテーション、時系列予測、インペインティングを統合したエンドツーエンド学習フレームワークは、映像安定化の新たな可能性と差異化が期待できます。これらの技術は、オンライン会議、コンテンツ制作、ライブストリーミングだけでなく動画生成AIで生成した動画の安定化・真実味の向上など、幅広い用途での映像品質向上に貢献することが期待され当社でもがんばって研究に取り組んでおります。
今後は、実装の詳細化と大規模データセットでの検証を通じて、提案手法の実用性をさらに高めていく予定です。当社の研究が映像処理技術の発展と、より自然で快適な映像体験の実現に寄与できれば幸いです。
Qualiteg では一緒に働いてくれる優秀な仲間を募集しています!
当社では、自社サービス開発やAI/MLのR&Dを担っていただける優秀なエンジニア、リサーチャーを積極的に募集しております。まだ新しい会社ですのでみんなで世界一居心地の良いエンジニア文化を作っていきたいとおもいます。



