
PII検出の混同行列では見えないもの ― 認識器間衝突と統合テスト


こんにちは!Qualiteg研究部です!
個人情報(PII: Personally Identifiable Information)の自動検出は、テキスト中から特定の表現を抽出し、それがどの種類のPIIに当たるかを判定する問題として捉えることができます。
電話番号、人名、口座番号、金額表現など、検出対象のPIIタイプが増えるにつれて、単一の手法ではカバーしきれなくなり、性質の異なる複数の認識器(Recognizer)を組み合わせるマルチレイヤー構成が採用されるのが一般的です。
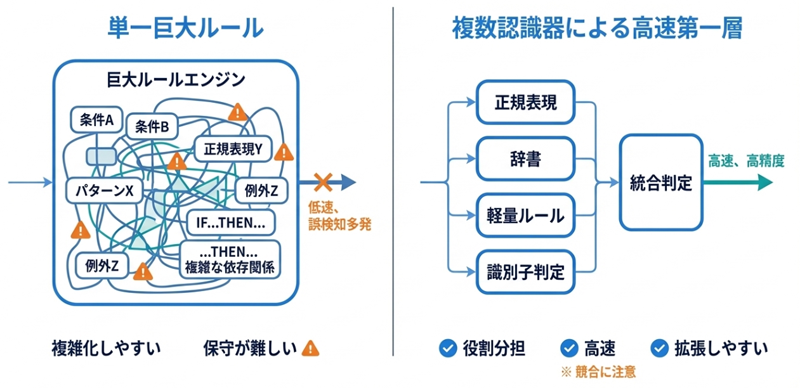
本稿で想定しているのは、ユーザーが海外製LLMにチャットを送信する直前に、その内容に個人情報や機密情報が含まれていないかをリアルタイムに検査するユースケースです。
この場面では、検出精度だけでなく、送信体験を損ねない速度が不可欠です。
高精度なLLMやBERT系モデル、NERベースの手法は有力ですが、送信前チェックの第一層として常時適用するには、レイテンシやコストの面で不利になることがあります。

そのため、本システムでは、正規表現、辞書、軽量なルールベース認識器を組み合わせた超高速な第一層を設け、そのうえで必要に応じて後段の認識器が文脈を補うマルチレイヤー構成を採用しています。
重要なのは、この構成が単なる正規表現パターンの追加ではないという点です。高速性を保ったまま検出範囲を広げようとすると、巨大な単一ルールに集約するよりも、役割ごとに認識器を分けたほうが設計しやすくなります。しかしその代償として、今度は各認識器が互いに干渉する問題が表面化します。
本記事ではこの現象を「クロス認識器衝突(Cross-Recognizer Collision)」と呼び、混同行列の観点からテスト設計のあり方を考察していきたいとおもいます。
混同行列の4象限とPII検出
混同行列は分類問題の性能評価に広く用いられる枠組みですが、PII検出の文脈では各象限が持つ実務上の意味合いがやや独特です。まず基本的な定義を確認します。
| 実際にPIIである | 実際にPIIでない | |
|---|---|---|
| 検出した | TP(真陽性) ✅ 正しく検出できた | FP(偽陽性) ⚠️ 誤検知・過検出 |
| 検出しなかった | FN(偽陰性) 🚨 見逃し | TN(真陰性) ✅ 正しくスルーできた |
これを具体例で補うと、以下のようになります。
| 実際にPIIである | 実際にPIIでない | |
|---|---|---|
| 検出した | 「年収500万円」を個人収入として正しく検出した | 日付 2026/3/5 の /5 をスコアパターンとして誤検出した |
| 検出しなかった | マイナンバーが文中にあるのに検出できなかった | 健康コラムの一般的な医学用語を正しくスルーした |
TP ― 開発初期の安心と、その限界
TPテストは開発の最初期に書かれるものです。
「この入力を与えたら正しく検出される」という確認は直感的であり、テストケースも書きやすいため、TP中心のテストスイートだけで早期に100%パスの状態を作れてしまいます。しかし、この100%は「検出すべきものを検出できた」ことしか証明しておらず、「検出すべきでないものをスルーできているか」については何も語りません。
FP ― ユーザー信頼を削る「オオカミ少年」問題
FPが多いシステムは、ユーザーからの信頼を急速に失います。正常なテキストに大量の警告フラグが立つツールを、日常的に使いたいと思う人はいません。FP率の高いシステムでは、やがて本当に重要なTP検出すら無視されるようになります。これは医療分野のアラート疲れ(Alert Fatigue)と同じ構造の問題です。
FN ― 直接的なリスク
PIIの文脈では、FNは情報漏洩に直結する可能性があります。マスクすべき個人情報が検出漏れによってそのまま外部に出てしまうリスクがあるため、FN率の低減はシステムの根本的な要件です。
TN ― 地味だが品質の基盤
TNテストは一見地味ですが、システムの「選択性(Specificity)」を保証する唯一の手段です。TNテストの不足は、FPの増加として後から表面化します。
テストカバレッジの偏り ― 個別認識器テストの落とし穴
あるPII検出プロジェクトで、文脈解析型の認識器を複数のパイプライン(検出カテゴリ)に分けて運用しているケースがありました。
全テストがグリーンという状態のもと、各パイプラインのテストカバレッジを象限別に分析したところ、以下のような分布が見られました。
| パイプライン | Positiveケース | Negativeケース | 合計 | Negative比率 |
|---|---|---|---|---|
| A(認証情報系) | 32 | 8 | 40 | 20% |
| B(人事情報系) | 28 | 7 | 35 | 20% |
| C(医療情報系) | 45 | 12 | 57 | 21% |
| D(経営戦略系) | 38 | 18 | 56 | 32% |
| E(法務情報系) | 30 | 10 | 40 | 25% |
| F(社内識別子系) | 35 | 9 | 44 | 20% |
| 合計 | 208 | 64 | 272 | 24% |
一見すると、非検出を期待するネガティブケースも全体の約4分の1を占めており、決してゼロではありません。「特定のキーワードが欠けている場合は検出しない」「サンプルと明記された文脈ではスルーする」「一般的な医学用語には反応しない」といった除外条件のテストは存在していました。
しかし、ここに2つの構造的な問題があります。
まず問題なのは、ポジティブケース偏重の比率そのものです。
検出成功を確認するケースが全体の76%を占めており、「検出できること」の確認に大半のテストリソースが割かれています。一方で、「検出しないこと」を確認するネガティブケースは4分の1に留まっていました。検出対象のバリエーション(表記揺れ、全角半角、略記等)に対するポジティブケースは充実している一方で、ネガティブケースは代表的な除外パターンをいくつか押さえた程度で止まっていました。
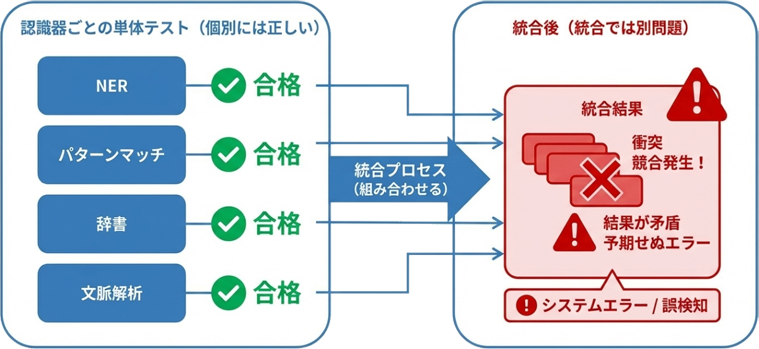
次に、より根本的な問題として、これらのネガティブケースは、いずれもその認識器単体で想定される除外条件を確認するものに留まっていたのです。ある認識器のテストスイートは、他の認識器がどんなパターンを持っているかを知りません。この「無関心」が、次に述べるクロス認識器衝突の温床になります。
クロス認識器衝突(Cross-Recognizer Collision)
マルチレイヤー構成のPII検出システムでは、各認識器の検出結果が最終的に一つのリストにマージされます。このマージの瞬間に、異なる認識器の検出結果が同一のテキスト範囲を奪い合う衝突が発生します。
以下に、典型的な3つの衝突パターンを示します。
ケース1: 形式の類似による識別子衝突
入力: "案件番号 A-1024 を更新してください"
期待: 業務上の内部識別子、または文脈に応じて非PIIとして扱う
実際: 別の認識器がこれを病室番号、チケットID、契約番号など別カテゴリの識別子として誤認する
英字と数字をハイフンで連結した短い識別子は、多くの業務システムで共通して使われます。形式だけに依存した認識器は、同一の文字列に対して異なる意味を割り当ててしまいがちです。
ケース2: 日付表記と比率・スコア表記の衝突
入力: "提出期限は2026/3/5です"
期待: PIIとしては検出なし
実際: 3/5 や /5 が比率・スコア表現として誤認される
スラッシュ区切りの表現は、日付、比率、評価点など複数の意味を持ちます。短い部分文字列だけを見る認識器は、周辺文脈を失った状態で誤反応しやすくなります。
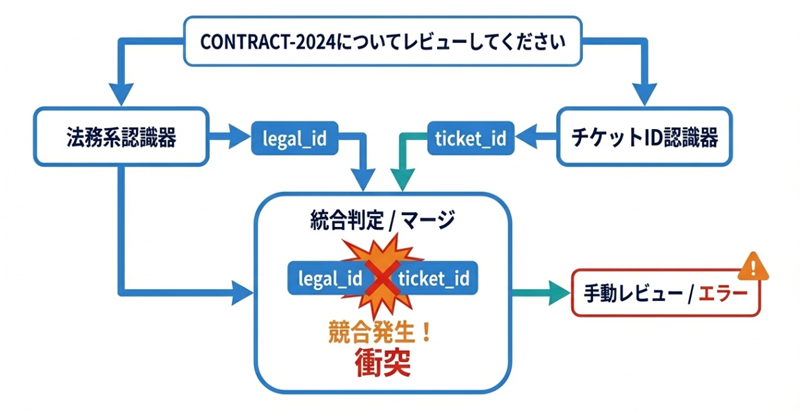
ケース3: ID形式の曖昧性
入力: "CONTRACT-2024についてレビューしてください"
期待: 法務情報(契約書ID)として検出
実際: チケットIDパターン(例: "PROJ-1234" 形式)にマッチ
大文字英字-数字4桁 という形式は、チケットID、契約書番号、プロジェクトコードのいずれにも使われます。正規表現パターンだけでは区別がつきません。文脈解析型の認識器であればコンテキストからより妥当な判定ができる可能性がありますが、実装によっては、早い段階のパターンマッチ結果が優先採用されたり、後段の判定を事実上マスクしたりするため、文脈に基づく補正が十分に効かないことがあります。
衝突が発見されにくい構造的な理由
クロス認識器衝突の発見が遅れるのは、テスト設計の構造的な問題に起因しています。
認識器ごとの独立した開発。 通常、各認識器は別々の開発者やチームが担当します。NERモデルのチューニング担当はNERのテストを、辞書認識器の担当は辞書のテストを書きます。各テストスイートは単体では正しく通りますが、他の認識器の存在を考慮した入力パターンは含まれていません。
CIパイプラインの分離。 多くのプロジェクトでは、各認識器のテストスイートが独立に実行されます。全認識器をロードした状態でのEnd-to-Endテストは、意識的に設計しない限り存在しません。
自然言語の本質的な曖昧性。 同じ文字列が複数の意味を持ちうるのは、自然言語の本質です。特に日本語は英語のようにスペースで単語が区切られないため、部分文字列マッチの問題がより深刻になります。\b(ワードバウンダリ)に相当する概念が希薄であり、形態素解析との連携が必要になる場面も少なくありません。
2×2の混同行列では見えない認識器間衝突
ここまでの議論を一般化してみます。
高速に動作する第一層のフィルタを置くこと自体は、セキュリティやDLP、入力検証の分野では必ずしも珍しい発想ではありません。本アプローチの特徴は、単に正規表現を増やすことではなく、高速に動作する複数の認識器を役割分担させ、その統合時に生じる衝突まで含めて品質設計の対象とした点にあります。高速な第一層を置くこと自体は一般的な設計判断ですが、その副作用として現れる認識器間競合を、テスト設計の中心課題として明示的に扱う例は必ずしも多くありません。
単一の認識器であれば、評価は2×2の混同行列で整理できます。しかし、複数の認識器を並走させるシステムでは事情が複雑になります。実際には、複数のエンティティタイプと「該当なし」を含む多クラス的な判定に加えて、認識器同士のスパン競合やラベル競合も発生するため、2×2の混同行列だけでは誤りの構造を捉えきれません。
このとき見落とされがちなのが、同一の文字列に対して認識器ごとに異なるラベルが付与されうるという関係です。たとえば CONTRACT-2024 という表記は、法務系認識器にとっては正しい契約識別子として扱われる一方、別の認識器からはチケットID形式として誤って解釈される可能性があります。つまり、ある認識器の正しい検出が、システム全体では別の認識器との競合源になることがあります。この二重性は、個別認識器のテストでは原理的に検出できません。
さらにPII検出では、単に「何を検出したか」だけでなく、「どこまでを検出したか」も重要です。たとえば電話番号の一部だけを拾った場合や、組織名に接続する部署名まで過剰に含めてしまった場合は、ラベル自体が正しくても実用上は不正解になりえます。したがって評価では、エンティティタイプの正誤だけでなく、スパン境界の正確さも区別して扱う必要があります。
認識器間の衝突関係を表にすると以下のようになります(行が「検出元」、列が「衝突先」です)。
| NER | パターンマッチ | 辞書 | 文脈解析 | |
|---|---|---|---|---|
| NER | ― | 人名がIDパターンに干渉 | 人名が辞書エントリに一致 | 人名がキーワードに干渉 |
| パターンマッチ | 電話番号がNER入力を汚染 | ― | IDが辞書エントリに類似 | 日付がスコアパターンに干渉 |
| 辞書 | 辞書エントリがNER人名と衝突 | 禁止ワードがIDパターンに一致 | ― | 辞書エントリがキーワードに一致 |
| 文脈解析 | 金額近傍の人名がキーワード誤認 | 口座番号が電話番号パターンに一致 | 金額カテゴリが辞書と競合 | ― |
対角要素以外のすべてのセルが、潜在的な衝突の温床です。システム全体の品質を測るには、この非対角要素を意識的にテストする必要があります。
対策のアプローチ

1. クロス認識器向けネガティブケースの追加
他の認識器のパターンに引っかかりそうな入力を、各認識器のTNテストとして追加する方法です。
// 医療系認識器のTNテスト
{
text: "案件番号 A-1024 を更新してください",
expected_count: 0,
description: "短い識別子形式を医療カテゴリとして誤認しないこと"
}
// チケットID認識器のTNテスト
{
text: "CONTRACT-2024についてレビューしてください",
expected_count: 0,
description: "契約ID形式を別カテゴリの識別子として誤認しないこと"
}
実装が容易で回帰テストとして確実に機能します。ただし、衝突パターンを事前にすべて洗い出すのは困難なため、本番で発見された衝突を一つずつTNテストに追加していく地道な積み上げが現実的です。
2. 認識器間の優先度と競合解決ルール
同じテキスト範囲に複数の認識器が反応した場合の解決戦略を明文化する方法です。
ひとつは、より長いスパンを優先する考え方です。短い部分一致よりも、広い範囲を一貫した意味として捉えている検出結果のほうを採用します。次に、周辺文脈のキーワードを考慮した検出を、パターンのみの検出より優先するアプローチがあります。さらに、特定のエンティティタイプ同士が競合した場合の優劣をあらかじめ定義しておく方法や、認識器ごとに数値的な優先度(Priority値)を設定し、競合時は高い方を採用する方法も有効です。
3. 統合テストレイヤーの導入
個別認識器のユニットテストとは別に、全認識器をロードした状態で実行する統合テストを設計します。
describe("Cross-Recognizer Collision Tests", () => {
const detector = createFullDetector(); // 全認識器をロード
it("日付がスコアパターンに誤検出されない", () => {
const results = detector.detect("会議は2026/3/5に設定されました");
expect(results.filter(r => r.type === "score")).toHaveLength(0);
});
it("識別子形式の競合が優先度ルールで正しく解決される", () => {
const results = detector.detect("CONTRACT-2024の条項を確認");
expect(results.some(r => r.type === "legal_id")).toBe(true);
expect(results.some(r => r.type === "ticket_id")).toBe(false);
});
});
ユニットテストが「この認識器は正しく動くか」を検証するのに対して、統合テストは「認識器同士が共存できるか」を検証します。両方が揃ってはじめて、システム全体の信頼性を担保できます。
4. ワードバウンダリの厳格化
部分文字列マッチの問題は、正規表現のワードバウンダリを適切に使うことで軽減できます。
// 部分文字列にもマッチしてしまう
const loose = /CT/i;
// 独立した語としてのCTにのみマッチする
const strict = /\bCT\b/i;
ただし日本語では英語ほど単語境界が明確ではないため、\b に依存した設計はそのままでは通用しません。実際には、形態素解析を併用したり、マッチ箇所の前後の文字種を確認したり、記号・英数字・漢字の境界を後段で補正したりといった工夫が必要になります。
まとめ ― テスト設計が証明していること、していないこと
さて、
では、本記事の要点を整理しましょう。
TPテストだけの100%は「偽りの安心」です
検出すべきものを検出できたことしか証明しておらず、検出すべきでないものへの耐性は未検証のままです。テスト設計の初期段階から、4象限すべてを意識すべきです。
個別認識器の単体テストは必要条件であって十分条件ではありません
複数の認識器を結合した統合テストを早期に導入しないと、結合後に想定外の衝突が発覚して手戻りが発生します。
衝突は偶発的な不具合というより、マルチレイヤー構成が本質的に抱える設計課題です
複数の認識器が異なる規則で同じ文字列を解釈する以上、ラベル競合やスパン競合は一定確率で発生します。したがって、衝突を例外として後から潰すのではなく、最初から前提条件としてテスト設計と競合解決ポリシーに組み込むべきです。
2×2の混同行列だけで閉じず、認識器間の競合まで含めて誤り構造を捉える視点が有効です
ある認識器にとって妥当な検出結果が、システム全体では別の認識器との競合源になるという関係性は、個別テストでは見えません。認識器間の衝突マトリクスを可視化し、非対角要素を意識的にテストすることで、システム全体の品質を底上げできます。
100%パスしたテストスイートを前にしたときこそ、
「このテストは何を保証しており、何をまだ保証していないのか」
を問い直すべき、ということになります。
その問いを持てるかどうかが、デモでは動くが本番では壊れる検出器と、実運用に耐える検出システムを分けるポイントなのかもしれません。
さて、今回は、マルチレイヤーPII検出における認識器間衝突と、その死角になりやすいテスト設計についてお話ししました。
高速性と検出品質の両立に向き合っている方にとって、何か一つでも参考になる点があればうれしいです。
最後まで読んでいただき、ありがとうございました。
次回また、お会いしましょう!



