
[ChatStream] キューイングシステムと同時処理制限
![[ChatStream] キューイングシステムと同時処理制限](/content/images/size/w1200/2024/04/queueing_system_cover.gif)
こんにちは! (株)Qualiteg プロダクト開発部 です!
本稿では、 ChatStream のキューイングシステムについてご説明いたします!
キューイングシステムとは
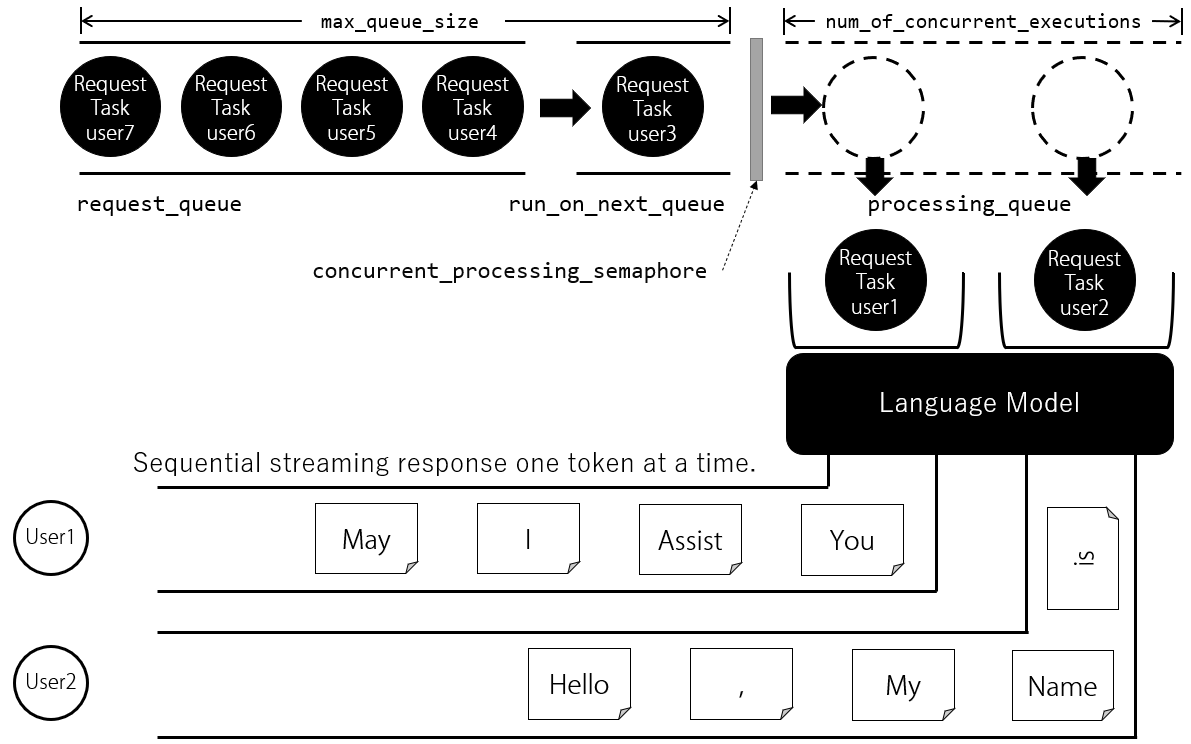
ChatStream は多数同時アクセス要求が来たときに、
リクエストをキューイングし、同時に実行できる文章生成の数を制限することができます。
GPU や CPU の性能に応じて、文章生成処理の同時実行数を制限することで、良好な応答性能を得ることができます。
また同時実行数を超えるリクエストがあった場合はリクエストをキューイング(待ち行列に追加)し、
順次実行することで、負荷を適切にコントロールします。
同時実行とは
同時実行とは 1GPU で実行する場合には、正確には同時実行ではなく 並行実行(concurrent) となります。
同時実行数をセットすると、その数だけ 並行実行 されます。
たとえば、同時実行数の最大値が2に設定されている状態で、2人のユーザー1、ユーザー2 が同じタイミングにリクエストしてきた場合
2人のリクエストは 処理キュー (文章生成中をあらわすキュー)に入り1トークンごとに交互に文章を生成 します。
例えば日本語のモデルの場合、1トークンはほぼ1文字に相当しますので、ユーザー1向けの文章に1文字追加したらユーザー2向けの文章に1文字追加します。
これを文章生成が終わるまで繰り返します。
ユーザー3が途中で割り込んできた場合、まだユーザー1とユーザー2の文章は生成されている途中ですので、ユーザーCのリクエストは リクエストキュー (処理待ち行列) に入ります。
ユーザー1またはユーザー2の文章生成が終了すると、 リクエストキュー に入っているユーザー3のリクエストが 処理キュー に入り、
文章生成処理が開始されます。
コラム: 非同期I/O と並行実行
FastAPIは非同期I/Oをサポートしており、これは複数のリクエストを並行に処理する能力があります。
Pythonの非同期I/Oは、コルーチンと呼ばれる特殊な関数を使用して並行性を実現しています。
この場合の並行性とは、一度に一つのタスクだけが進行するが、I/O操作(HTTPリクエスト、モデルからのトークンの生成など)を待つ間に他のタスクを進行させることができる
ということです。この形式を"協調的マルチタスク"を呼びます。
それぞれのリクエストは別の「非同期タスク」として処理され、これらのタスクは同じスレッド上で切り替えられます。
「非同期タスク」においては複数のリクエストに対するモデルへのアクセスが並行しているように見えますが
実際にはある瞬間に一つのリクエストだけがモデルを利用しています
そのため、それぞれのリクエストが モデルによるトークン生成のためにブロックする期間は限られており、
逐次出力トークンの生成について言えば、1つ新トークンを生成した後で他のリクエストに制御を戻すことができます
そのため、一つのリクエストによる文章生成の際、停止トークン、停止文字列が現れるまでの間、
他の全てのリクエストがブロックされることはなく、各リクエストはモデルからのトークンを逐次生成しながら、
他のリクエストも進行させることができます
キューイングの開始
Web アプリケーションの起動時に start_queue_worker を呼ぶことで、キューワーカーを開始できます
キューワーカーを開始すると、リクエスト処理キューが開始され、リクエストをリクエストキューに挿入し、処理キューへと順次実行していくキューイングループが開始されます
chatstream#start_queue_worker



