
【極めればこのテンソル操作】permute(1,0)

本記事はPyTorch,NumPy でよくつかうテンソル操作を、頭でしっかりイメージできるようにするための機械学習エンジニア初心者向けシリーズです!
「厳密な正しさ」をもとめるリファレンス的なものではなく、現場でつかうソースコードに頻出するコードで覚えていきましょう。
今日は permute (1,0)
permute操作は、テンソルの次元の順序を変更するためによく使用されます。permuteメソッドの引数は、並び替えの順番を指定します。
permute(1,0)は2次元のテンソルにおいては、「転置」テンソルを作る役割を果たします。なぜそうなのか、順を追ってみていきましょう!
それでは早速以下のような 2×3 なテンソルを考えてみましょう
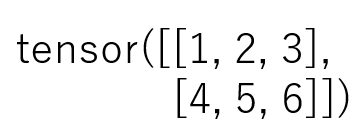
このテンソルは2次元なので、表で表現できますね。
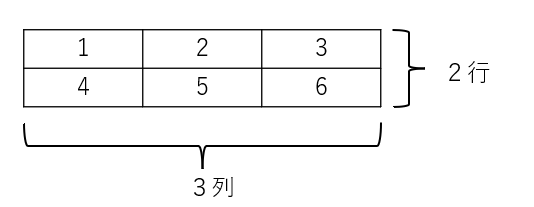
このとき、このテンソルは PyTorchでは以下のように定義できます。
import torch
x = torch.tensor([[1, 2, 3],
[4, 5, 6]])
このテンソルの「形状」は、上でもかいたとおり 2 × 3 ですね。
コード内では、これを (2,3) や [2,3] のように表現します。
テンソルの形状は以下のように .shape で得ることができます
print(f"Shape: {x.shape}")出力結果は以下のようになります
Shape: torch.Size([2, 3])はい、ここで、 この [2,3] は各次元のサイズですよね。
この次元の位置を変更できるのが permute です
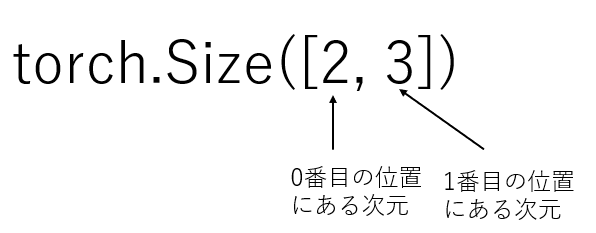
たとえば、今の例だと、
- 0番目の位置にある次元(つまり行)の大きさが2
- 1番目の位置にある次元(つまり列)の大きさが3となります
ある次元を「人」と呼ぶと、
permuteの文法は
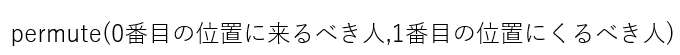
となります。
そこで、

とは、以下を意味します。

permute(1,0) のサンプルコード
import torch
import numpy as np
x = torch.tensor([[1, 2, 3],
[4, 5, 6]])
print("Original tensor:")
print(x)
print(f"Shape: {x.shape}")
# permute: 次元の順序を変更
print("\n1. Permute")
print(f"Before: {x.shape}")
y = x.permute(1, 0)
print(f"After permute(1, 0): {y.shape}")
print(y)結果は以下のように [3,2]のテンソルになりました。
Original tensor:
tensor([[1, 2, 3],
[4, 5, 6]])
Shape: torch.Size([2, 3])
Permute
Before: torch.Size([2, 3])
After permute(1, 0): torch.Size([3, 2])
tensor([[1, 4],
[2, 5],
[3, 6]])つまり、転置していますね。
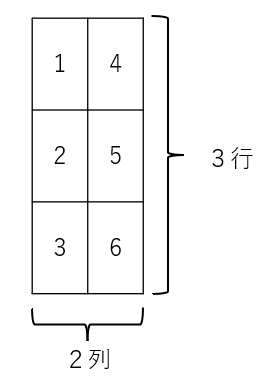
このように、2次元のテンソルの場合は、permute(1,0)は「転置」ベクトル操作になります。



