
[ChatStream] 入出力プロンプトの予期せぬ変更に備え revision は固定する
![[ChatStream] 入出力プロンプトの予期せぬ変更に備え revision は固定する](/content/images/size/w1200/2024/05/-----TIPs--1--1.png)
こんにちは。(株) Qualiteg プロダクト開発部です。
GW中に、microsoft/Phi-3-mini-128k-instruct の tokenizer.json が変更になり、プロンプトのパースに失敗し、チャットのストリーミングができなくなる問題が発生しました。
実際には以下の変更がありました
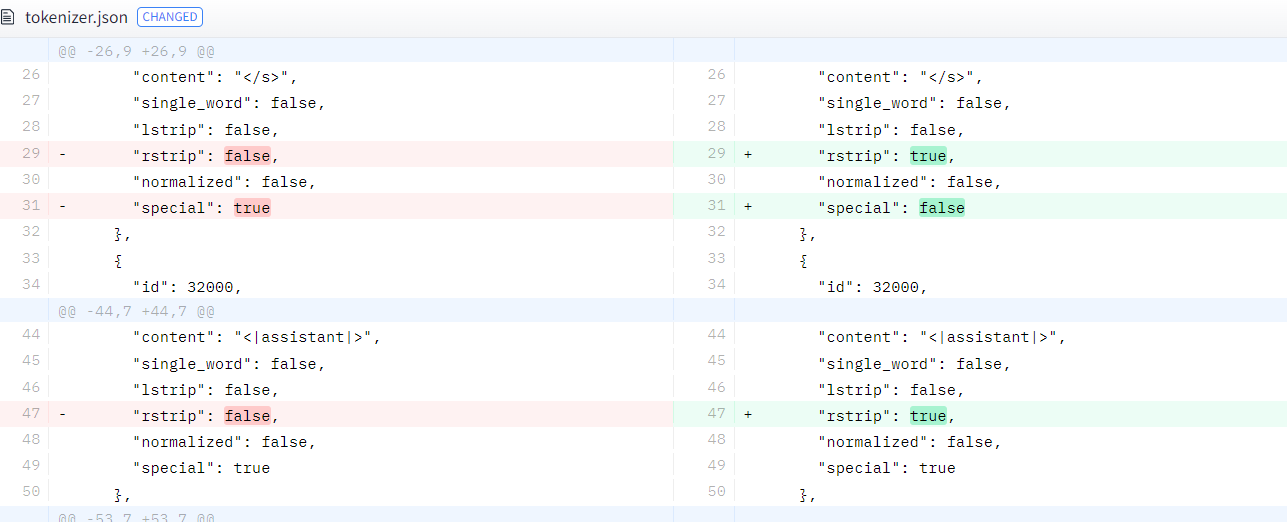
もともと、Miscrosoft さんが書いていた記事にあるプロンプトフォーマットと実際のモデルのプロンプトフォーマットが異なっていたため、当社では、実際のモデルにあわせるヒューリスティックな対応をしておりましたが、モデル(\w tokenizer) 側がもとの仕様に近い形に修正してきた模様です。
これによって、当初動作していたプロンプト変換器が動作しなくなるという現象が発生しました。
LLM は「スピードが命!」なので、トークナイザー含め完全にテストされた状態では出てこないのは given condition ですが、モデルがアップデートされるためにプロンプト変換エラーが発生しないよう、 プロダクトでAuto クラスをつかったモデル・トークナイザーの読み込みをするときには revision 付き呼出しをし、その上で、モデルの最新版がでたときに、しっかりテストを回すという運用が好ましいとおもいます。
リビジョン付き呼出しの例
MODEL_REVISION = "8a362e755d2faf8cec2bf98850ce2216023d178a"
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3-mini-128k-instruct",
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
revision=MODEL_REVISION,
)
tokenizer = AutoTokenizer.from_pretrained(model_path, revision=MODEL_REVISION)(リビジョンは コミットID、タグ名 など指定可能)



