
GPUメモリ最適化の深層:初回と最終バッチの特殊性を踏まえた効率的なAI画像処理

はじめに
こんにちは!Qualitegプロダクト開発部です。
当社では、LLMテクノロジーをベースとしたAIキャラクター、AIヒューマンの研究開発を行っています。そんな中、表情、仕草のように「人間らしさ」をもったバーチャルヒューマンを再現するときには画像生成、画像編集といったAIを活用した画像処理が必要となります。
人と対話するAIヒューマンやバーチャルヒューマンはタイムリーに表情や仕草を生成する必要があるため、複数の画像をフレーム連結してつくるモーション(シンプルにいうと動画)を短時間に生成する必要があります。
このようなとき、AIトレーニングやシンプルな推論とは異なり、いかにGPUの能力を引き出してやるか「GPUの使いこなし術」がミソとなります。
GPUの使いこなし術というと、以前のブログにも連続バッチやダイナミックバッチについてLLM推論のコンテクストで語りましたが、本日は画像処理におけるGPUメモリ最適化、とくに、推論時バッチにおける「初回と最終回」のお作法という少しマニアックな話題について語ってみようとおもいます。
画像処理とGPU
GPUを用いた画像処理や機械学習タスクにおいて、メモリの効率的な使用は性能を左右する重要な要素です。
特に、大規模なデータセットを扱う際には、GPUメモリの動的な挙動を理解し、適切に対処することが求められます。
最初にのべたとおり本記事では、バッチ処理における初回と最終バッチの特殊性に焦点を当て、効率的なGPUメモリ使用のための詳細な戦略を紹介します。
事例
理解を深めるために、具体的な事例で考えます。
今回は、動画を1フレームずつ処理する事例で考えてみましょう。
この動画が全部で120フレームあったとしましょう。つまり、120枚の画像で構成されています。

1枚ずつ処理をすると時間がかかるので、16枚を同時にGPUで処理させます。
つまり、バッチサイズ16でGPUをつかって推論する例を考えてみます。

1. 初回バッチの特殊性:予想外のメモリ消費
現象
初回のバッチ処理時に、その後の通常の推論時よりも大幅に多くのGPUメモリが消費されることがあります。
たとえば、初回推論だけ 2000MBのGPUメモリを消費した。でも、2回目以降は80MB固定だった、みたいな現象が発生します。
原因
- CUDA最適化: 初回実行時、CUDAは様々なアルゴリズムを試し、最適な実行パスを決定します。
- メモリプール確保: PyTorchなどのフレームワークは、初回に大きめのメモリプールを確保し、以降の処理で再利用します。
- JIT(Just-In-Time)コンパイル: 一部の操作では、初回実行時にGPU上でコードがコンパイルされます。
対策と最適化
こんな時はウォームアップ処理を入れておきましょう。
GPU処理をサーバーとして提供しているなら、サーバーの起動時などに、ウォームアップをし、これから行う処理の予行演習を1回やることでGPUの目を覚まさせることができます。たいてい1回目にCUDA最適化処理やPyTorchのメモリ確保などが行われます。複数サーバーをクラスター構成にするときなどもサーバー立ち上げ時の初期化処理として1回予行演習をはさむと安定します。
def warmup_gpu(model, input_shape):
dummy_input = torch.randn(input_shape).cuda()
model(dummy_input) # ウォームアップ実行
torch.cuda.empty_cache() # キャッシュをクリア
# 本番処理前にウォームアップを実行
warmup_gpu(model, (1, 3, 224, 224))
効果
- 初回バッチの異常なメモリ消費を隠蔽
- 本番処理のパフォーマンスを安定化
2. 最終バッチの特殊性:新たなメモリ確保の罠
現象
データセット数がバッチサイズで割り切れない場合、最終バッチで予想外に大きなメモリ消費が発生することがあります。
今回の例のように 120フレームの動画をバッチサイズ16で処理すると、
120 ÷ 16 = 7 あまり 8 ということで、1番目から7番目までの処理では、16枚の画像をバッチで処理できますが、最終の8番目のバッチ(バッチ8)は、画像がバッチサイズに足りない8枚しか入力できなくなってしまいます。つまり、最終バッチのループで 8枚分は入力できないことになりますね。
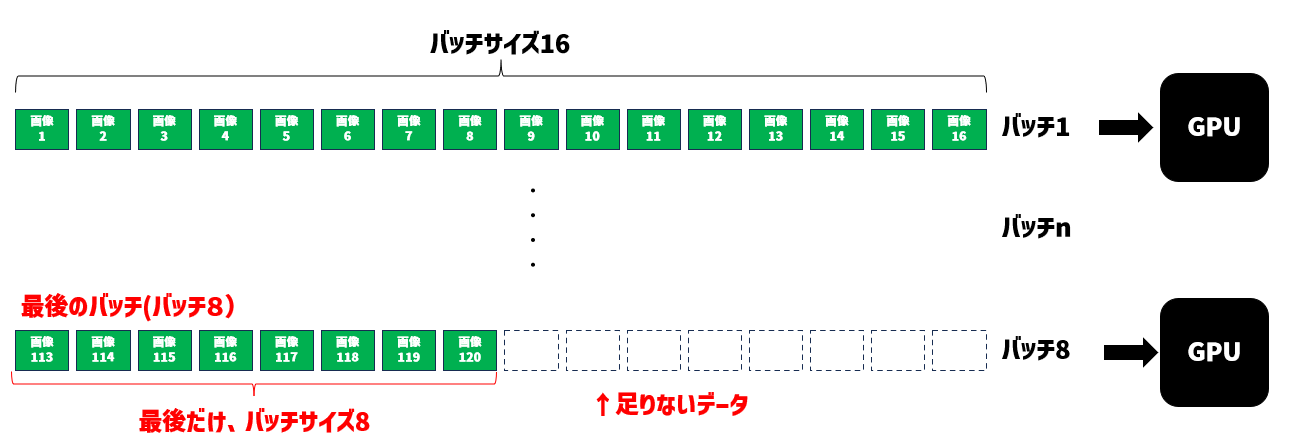
一件、問題なさそうにみえますが、実はこれが問題を引き起こします。
最後の1回だけバッチサイズが異なってしまうと、(CUDAさんが最適化をやりなおそうとして)CUDAカーネルの再コンパイルが発生します。これにより、再度、新たなメモリを大き目に確保する現象が発生することがあります。
そこで、最終バッチがバッチサイズを下回った場合でも、同じバッチサイズにあわせこんでGPUに投入してあげるとCUDAカーネルの再コンパイルがかからないで済みます。
原因
- 不均一なバッチサイズ: 最終バッチが他のバッチと異なるサイズになると、新たなメモリ領域の確保が必要になります。
- CUDAカーネルの再コンパイル: 異なるサイズの入力に対して、CUDAカーネルの再コンパイルが発生する場合があります。
- メモリフラグメンテーション: 連続した処理で、小さな未使用メモリ領域が散在し、新たな大きなメモリ確保が必要になることがあります。
対策と最適化
例えば、以下のように、最終バッチがバッチサイズより小さいとき、足りない分を埋めてやることで、GPUに与えるバッチサイズを維持することができます。
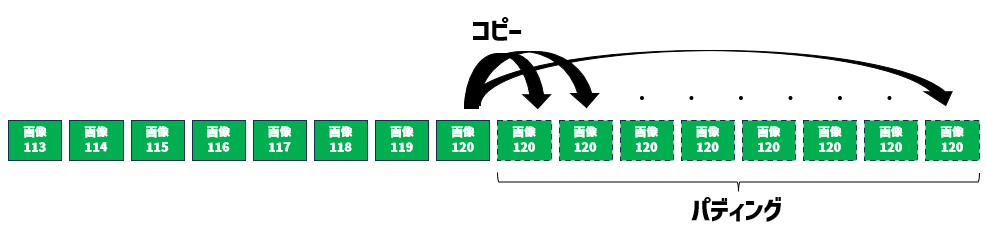
たとえば、↑のように最後の要素で残りを埋めてやることができます。
このように、何らかで埋めてデータの長さを整えることを「パディング」と呼びます。上の例では、とりあえず最後の要素でうめてみましたが、0テンソルでうめるなど、何で埋めてやるかはモデルの特性に応じて検討する必要があります。
これはシンプルな対策例ですが、CUDAやPyTorchの組み合わせ・バージョンによっては、これだけでも、巨大メモリの新たな確保という現象を抑えることが可能です。
これが「最終バッチのパディング」という手法となります。
def process_batch(batch, model, batch_size):
if len(batch) < batch_size:
# 最後の要素でパディング
padding = [batch[-1]] * (batch_size - len(batch))
batch += padding
results = model(batch)
# パディングされた部分を除去
return results[:len(batch)]
def process_dataset(dataset, model, batch_size):
results = []
for i in range(0, len(dataset), batch_size):
batch = dataset[i:i+batch_size]
batch_results = process_batch(batch, model, batch_size)
results.extend(batch_results)
return results
効果
- バッチサイズの一貫性維持によるメモリ使用の安定化
- CUDAカーネルの再コンパイル回避
- メモリフラグメンテーションの軽減
3. 詳細なメモリ使用量のモニタリングと分析
ご紹介のように、いったんモデルが完成したら、各ノードごとの推論の最適化を行うわけですが、その際は、詳細なメモリ使用状況を把握するために、PyTorchの高度なメモリトラッキング機能を活用しましょう。
import torch
def detailed_memory_stats():
print("\n===== GPU Memory Stats =====")
print(f"Allocated: {torch.cuda.memory_allocated() / 1e6:.2f} MB")
print(f"Cached: {torch.cuda.memory_reserved() / 1e6:.2f} MB")
print(f"Peak Allocated: {torch.cuda.max_memory_allocated() / 1e6:.2f} MB")
print(f"Peak Cached: {torch.cuda.max_memory_reserved() / 1e6:.2f} MB")
def process_with_memory_tracking(batch, model):
torch.cuda.reset_peak_memory_stats()
detailed_memory_stats()
results = model(batch)
detailed_memory_stats()
return results
# 使用例
for i, batch in enumerate(dataloader):
print(f"\nProcessing batch {i}")
results = process_with_memory_tracking(batch, model)
このコードを使用することで、各バッチ処理の前後でのメモリ使用状況の詳細な変化を追跡できます。
これにより、初回バッチや最終バッチでの特殊な挙動を明確に把握し、必要に応じて最適化戦略を調整することが可能になります。
まとめ
GPUを用いた画像処理の最適化、特にメモリ管理においては、初回バッチと最終バッチの特殊性を理解し適切に対処することでGPUメモリの効率的な使用ができることを解説いたしました。
本記事で紹介した技術を活用することで、以下の利点が得られます
- 安定したGPUメモリ使用
- 予期せぬメモリエラーの回避
- 処理速度の向上と安定化
- リソース使用の透明性向上
これらの最適化テクニックは、使用するハードウェア、ソフトウェアフレームワーク、そして具体的なタスクによって効果が異なる場合があります。そのため、実際の使用環境での継続的なモニタリングと調整が不可欠ですね。
今回は、1ノード内の1GPUでのバッチ推論について特に説明をしましたが、今後マルチGPUやマルチノードのGPUメモリ効率化についてもまたご紹介させていただければとおもいます。
それでは、本日もお読みいただきありがとうございました!



