
LLM推論基盤プロビジョニング講座 第4回 推論エンジンの選定


こんにちは!前回までの講座では、LLMサービス構築に必要なリクエスト数の見積もりや、使用モデルの推論時消費メモリ計算について詳しく解説してきました。今回は7ステッププロセスの4番目、「推論エンジンの選定」について詳しく掘り下げていきます。
LLM推論基盤プロビジョニング講座 シリーズ記事一覧
- 第1回 基本概念と推論速度
- 第2回 LLMサービスのリクエスト数を見積もる
- 第3回 使用モデルの推論時消費メモリ見積もり
- 第4回 推論エンジンの選定
- 第5回 GPUノード構成から負荷試験までの実践プロセス
- 番外編 KVキャッシュのオフロード戦略とGQA
推論エンジンとは何か
推論エンジンとは、GPU上でLLMモデルの推論計算(テキスト生成)を効率的に行うために設計された専用のソフトウェアプログラムです。一般的なディープラーニングフレームワーク(PyTorch、TensorFlowなど)でも推論は可能ですが、実運用環境では専用の推論エンジンを使用することで、大幅なパフォーマンス向上とリソース効率化が期待できます。
推論エンジンは単なる実行環境ではなく、様々な最適化技術を実装しています。特定のモデルアーキテクチャに特化した最適化機能を実装したものや、推論速度の高速化に特化したもの、前回解説したKVキャッシュのメモリ効率化機能を備えたものなど、それぞれ特徴が異なります。そのため、自社で採用したLLMモデルや運用環境、要件に合致した推論エンジンを選定することが重要です。
推論エンジン選定のアプローチ
推論エンジンの選定は、理想的には複数の候補を実際に試してベンチマークを取ることが望ましいですが、時間や資源の制約がある場合は、まずは大まかな絞り込みから始めるアプローチも有効です。
特に重要なのは、自社で採用したLLMモデルとの互換性です。最初の段階で、採用予定のLLMに対応していない推論エンジンを除外することで、後続の負荷テストの対象を絞り込むことができます。モデルとエンジンの相性は非常に重要で、すべての推論エンジンがすべてのモデルに最適なパフォーマンスを発揮するわけではありません。
互換性の確認後は、パフォーマンス(推論速度、メモリ効率)、使いやすさ(セットアップの難易度、ドキュメンテーションの充実度)、拡張性(分散推論のサポート)、サポート体制(コミュニティの活発さ、商用サポートの有無)などの観点から評価していきます。
主要な推論エンジンの比較
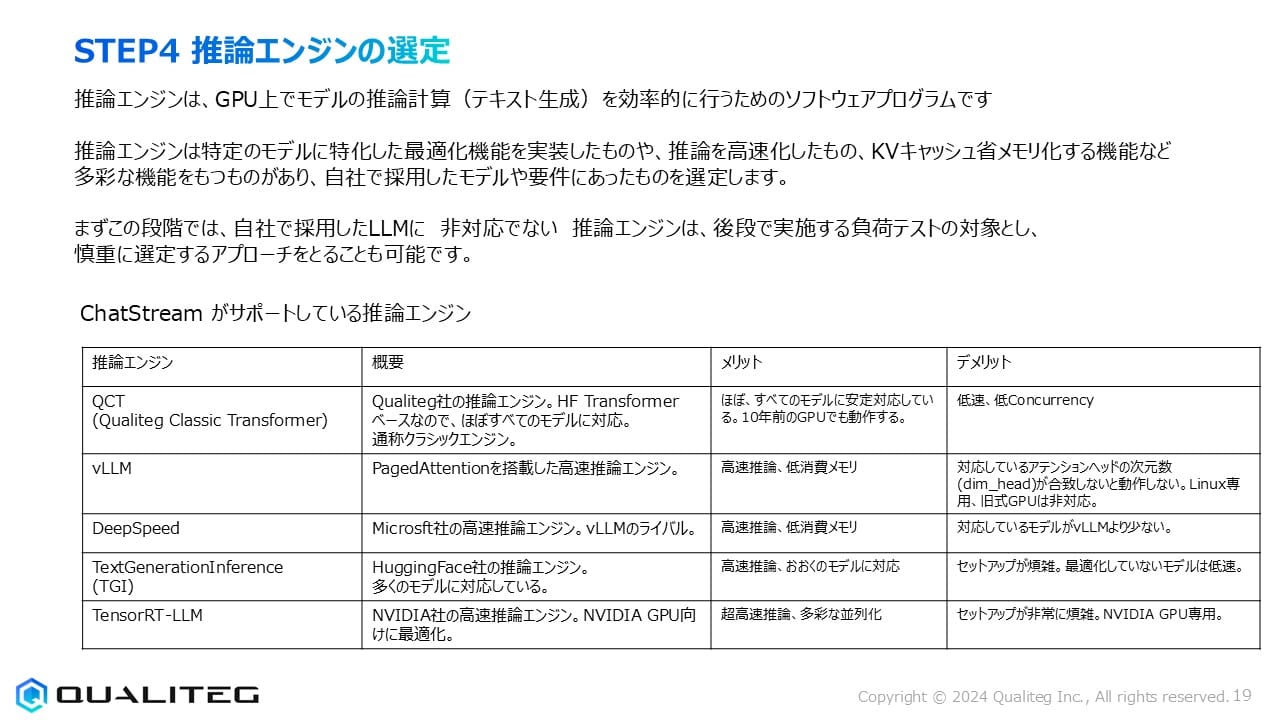
市場には多数の推論エンジンが存在しますが、ここではChatStream(当社のLLM推論システム)がサポートしている主要な推論エンジンについて詳細に見ていきましょう。(ChatStreamを使用しなくても、ご紹介する推論エンジン単体でもちろん使用できます)
ChatStreamとは
ChatStreamはChatGPTやClaudeのような多ユーザー、大規模LLMサービスの構築を目的として構築された当社のLLMサービス構築ワンストップソリューションです。UIからバックエンドの推論環境、負荷分散に対応しておりローカルLLMを使用してチャットアプリケーションのみならずあらゆるLLMサービスを効率的に開発することが可能です。
さて、各推論エンジンにはそれぞれには固有の長所と短所があります。
1. QCT(Qualiteg Classic Transformer)
概要
当社 Qualitegが開発した推論エンジンで、HF Transformer(Hugging Face Transformers)をベースにしています。従来型の推論アーキテクチャを採用したクラシックエンジンと位置づけられますが、幅広いモデルとの互換性を重視して設計されています。
メリット
- ほぼすべてのTransformerベースのLLMに安定的に対応しているため、モデルの互換性を重視する場合に適しています。
たとえば、多くの推論エンジンがサポートしていない(または、一部動作するが不具合が多い)LLMも安定動作いたします。
例えば FUGAKU LLM がリリースされたときも当社環境に公開したところ官公庁含め多くの皆様にご試用いただけました。 - 10年以上前の古いGPUでも動作可能なため、既存のハードウェア資産を活用できます。
- セットアップが比較的簡単で、特別な環境設定が少なくて済みます。
デメリット
- 最新の最適化技術を採用していないため、推論速度は最新のエンジンに比べて低速です。
- 同時に処理できるリクエスト数(Concurrency)が限られており、大量のリクエストを捌く用途には不向きです。
- メモリ効率化機能が限定的なため、大規模モデルや長いコンテキスト処理に課題があります。
2. vLLM
概要
PagedAttentionと呼ばれる革新的なKVキャッシュ管理技術を搭載した高速推論エンジンです。2023年にUC Berkeleyの研究チームによって開発され、オープンソースとして公開されました。短期間で広く採用され、現在最も人気のある推論エンジンの一つとなっています。
メリット
- 高速な推論速度を実現し、従来のエンジンと比較して2〜5倍の高速化が可能です。
- PagedAttention技術により、KVキャッシュのメモリ使用効率が大幅に向上し、同時に処理できるリクエスト数が増加します。
- 継続的に活発な開発が行われており、新機能やパフォーマンス改善が頻繁に提供されています。
デメリット
- 対応しているアテンションヘッドの次元数(dim_head)が含まれていないと動作しないという制約があります。
- Linux環境での使用が前提となっており、Windows環境での導入には追加の工夫が必要です。
- 旧式GPUは非対応で、比較的新しいNVIDIA GPUが必要となります。
3. DeepSpeed
概要
Microsoft社が開発した高速推論エンジンで、大規模モデルの分散トレーニングと推論に強みを持っています。vLLMのライバル的存在で、特に大規模な分散環境での実行に適しています。
メリット
- 高速な推論性能を発揮し、特に複数GPU間での分散推論に優れています。
- ZeRO-Inferenceなどの独自のメモリ最適化技術により、限られたGPUメモリでも大規模モデルの実行が可能です。
- Microsoft社による継続的な開発とサポートが期待できます。
デメリット
- vLLMと比較して、対応しているモデルの種類が少ない傾向があります。
- セットアップと設定の複雑さがあり、初心者にはハードルが高い場合があります。
- 最新モデルへの対応が若干遅れる場合があります。
4. Text Generation Inference (TGI)
概要
Hugging Face社が開発した推論エンジンで、同社のTransformersライブラリと緊密に統合されています。多くのモデルに対応し、特にHugging Faceエコシステムを活用している場合に相性が良いエンジンです。
メリット
- 高速な推論性能を提供し、特に短〜中程度のコンテキスト長での処理に効率的です。
- Hugging Face Hubで公開されている多数のモデルに対応しているため、様々なLLMを試す場合に便利です。
- Hugging Faceの他のツールやサービスと統合しやすい設計になっています。
デメリット
- セットアップが複雑で、特に初期設定に時間がかかる場合があります。
- 最適化されていないモデルでは、他のエンジンと比較して推論速度が低下することがあります。
- 大規模な分散環境での利用に関しては、vLLMやDeepSpeedに機能面で劣る場合があります。
5. TensorRT-LLM
概要
NVIDIA社が開発した高速推論エンジンで、同社のGPUに最適化されています。特にNVIDIA A100やH100などの最新GPUで最大のパフォーマンスを発揮するように設計されています。
メリット
- NVIDIA製GPUを「使い切る」ように最適化されておりvLLMやDeepSpeedを超える超高速な推論性能を実現し、特に最新のNVIDIA GPUでは最高クラスの速度を達成します。
- 多彩な並列化技術を実装しており、複数GPUを効率的に活用できます。
- NVIDIA社による継続的な最適化とアップデートが期待できます。
デメリット
- NVIDIA GPU専用ですので、NVIDIA製 GPU にロックインされます。
- セットアップが非常に複雑で、専門知識が必要となる場合が多いです。
- NVIDIA GPU専用であり、他のGPUベンダー(AMD、Intelなど)のハードウェアでは使用できません。
- 配布されるモデルをそのまま使用することはできず、専用のモデルとするためにモデルの変換プロセスが必要です。また、すべてのモデルがスムーズに変換できるわけではありません。NVIDIA GPUに最適化するために「コンパイル」するようなイメージです。
(有名なオープンモデルは既にNVIDIA NIMというマイクロサービス化されているため、オープンもでるとそのまま使いたい場合は、自分で TensorRT LLM をいじるよりも、NVIDIAのクラウドプラットフォームに乗っかってしまう、という手もあります)
推論エンジン選定の実践的アプローチ
実際のプロジェクトでは、以下のステップで推論エンジンを選定することをお勧めします
- 要件の明確化
LLMサービスの要件(推論速度、同時リクエスト処理能力、対応モデル、拡張性など)を明確にします。 - 互換性の確認
採用予定のLLMモデルと互換性のある推論エンジンをリストアップします。ここでは公式ドキュメントやコミュニティの情報を参考にします。 - 初期評価
2〜3の有力候補を選び、簡単なベンチマークテストを実施します。推論速度、メモリ使用量、セットアップの容易さなどを評価します。 - 詳細ベンチマーク
初期評価で良好な結果を示した候補について、より詳細なベンチマークを実施します。実際のユースケースに近い条件でのテストが重要です。 - 拡張性テスト
サービスの成長を見据えて、スケールアウト(複数GPUへの分散)やスケールアップ(より大きなモデルへの対応)のテストも行います。 - 総合評価
パフォーマンス、拡張性、使いやすさ、コスト、コミュニティサポートなどを総合的に評価し、最終決定を行います。
重要なのは、「最も新しい」や「最も人気がある」という理由だけで推論エンジンを選ばないことです。自社の特定のニーズと制約に最も適したエンジンを選定することが、長期的な成功につながります。
ケーススタディ別の推論エンジン選択指針
異なるユースケースで適した推論エンジンが異なる場合があります。以下にいくつかの典型的なケースとおすすめの選択肢を紹介します
ケース1:多様なモデルを試行錯誤したい研究開発環境
- おすすめ:QCT、TGI
- 理由:幅広いモデルへの対応性と、セットアップの容易さが優先される
ケース2:高トラフィックの本番サービス環境
- おすすめ:TensorRT-LLM、vLLM、DeepSpeed
- 理由:高い推論速度と同時リクエスト処理能力が求められる
ケース3:限られたGPUリソースでの運用
- おすすめ:vLLM、DeepSpeed
- 理由:メモリ効率化機能により、限られたリソースでも効率的な運用が可能
ケース4:エンタープライズ向け大規模分散環境
- おすすめ:DeepSpeed、TensorRT-LLM
- 理由:OSSとはいえ、ベンダーの関与が高いためベンダーサポートが期待できる。複数GPU・複数ノードでの分散推論に優れた機能を持つ
まとめと次のステップ
推論エンジンの選定は、LLMサービス構築における重要な決断の一つです。適切なエンジンを選ぶことで、パフォーマンスを最大化し、コストを最適化し、将来の拡張にも対応できる基盤を整えることができます。
今回紹介した各推論エンジンは、それぞれ長所と短所を持っており、すべての状況に最適な「万能」のエンジンは存在しません。自社のLLMモデル、ハードウェア環境、要件に基づいて慎重に選定し、可能であれば実際にベンチマークテストを行うことをお勧めします。
次回のSTEP5「GPUノード構成見積もり」では、選定した推論エンジンを用いて、実際のGPUノード構成をどのように設計するかについて詳しく解説していきます。推論エンジンの特性を踏まえたGPU台数の見積もり、メモリ要件の計算、コスト最適化の方法などを学んでいきましょう。
それでは、次回またお会いしましょう!
LLM/AIセキュリティのことなら株式会社Qualiteg
私たちQualitegは、LLMの推論・サービング基盤を実際に設計してきたエンジニアリングチームを有しており推論エンジンを単なる箱として扱わず、アテンション計算やKVキャッシュの挙動など深い知見をベースにしたローカルLLM技術のご支援を提供しています。「VRAMに収まる構成はどこか」「vLLMとHugging Face、判断軸は何か」「既存モデルを自社ドメインへ適応させる最短経路は」「オープンLLMと商用LLMの使い分け」「セキュアなローカルLLM構成はどうすればいいか」「ローカルLLMとGPUの選び方」「GPUデータセンターの需要と市場予測」「AI市場予測」などコア技術からAI市場分析まで、お気軽にご相談くださいませ。



