
LLM推論基盤プロビジョニング講座 第5回 GPUノード構成から負荷試験までの実践プロセス


こんにちは!これまでのLLM推論基盤プロビジョニング講座では、推論速度の定義、リクエスト数見積もり、メモリ消費量計算、推論エンジン選定について詳しく解説してきました。
今回は、残りのステップである「GPUノード構成見積もり」「負荷試験」「トレードオフ検討」について一気に解説し、最後に実際のサーバー構成例をご紹介します。
LLM推論基盤プロビジョニング講座 シリーズ記事一覧
- 第1回 基本概念と推論速度
- 第2回 LLMサービスのリクエスト数を見積もる
- 第3回 使用モデルの推論時消費メモリ見積もり
- 第4回 推論エンジンの選定
- 第5回 GPUノード構成から負荷試験までの実践プロセス
- 番外編 KVキャッシュのオフロード戦略とGQA
STEP5:GPUノード構成見積もり
GPUメモリから考える同時リクエスト処理能力
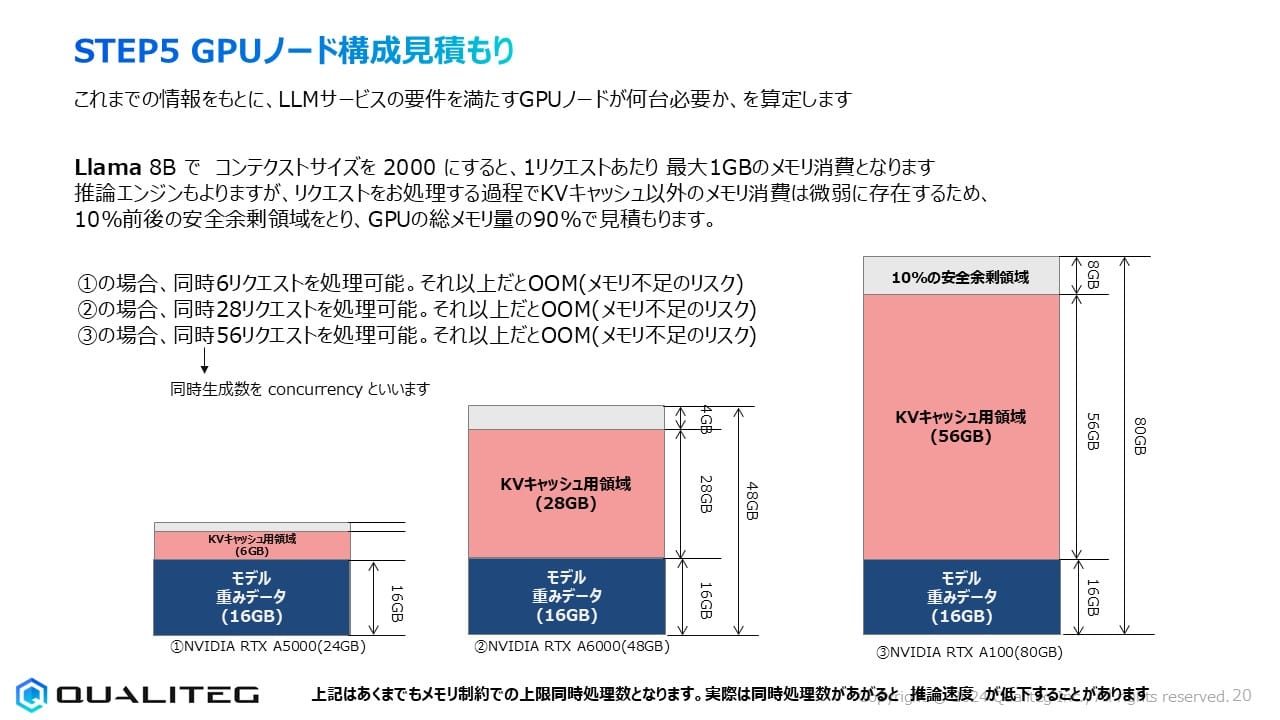
LLMサービスを構築する際、どのGPUを何台選ぶかは非常に重要な決断です。今回はLlama 8Bモデルを例に、GPUメモリ容量と同時リクエスト処理能力の関係を見ていきましょう。
GPUメモリの使われ方を理解する
ここは復習となりますが、
LLM推論においてGPUメモリは主に2つの用途で消費されます
- モデル重みデータ: LLMモデル自体を格納するためのメモリ
- KVキャッシュ: ユーザーとの対話コンテキストを保持するための一時メモリ
Llama 8Bを16ビット精度で実行する場合、モデル重みデータは約16GBのメモリを占めます。これは固定的なメモリ消費で、GPUに一度ロードしたら変化しません。
一方、KVキャッシュはユーザーリクエストごとに消費されるメモリです。コンテクストサイズ2000トークンの場合、1リクエストあたり約1GBのメモリを消費します。つまり、どれだけのユーザーリクエストを同時に処理できるかは、モデル重みデータをロードした後に残る「KVキャッシュ用領域」の大きさで決まります。
これをふまえて、GPUメモリ容量と同時リクエストの関係をみてみましょう。
GPUの種類によってGPUメモリ容量は固定的に決まるので、どのGPUをつかうか=どのくらいのGPUメモリが使えるか、と読み替えてもよいでしょう。(もちろんメモリ容量以外にもフィーチャーの違いはありますが話をシンプルにして考えます)
GPUメモリ容量と同時リクエスト処理数の関係
現在、8Bのモデルを実サービスでつかうことはほとんどありませんが、仮に8Bのモデルで事足りる要件があるとき、それを以下3種類のNVIDIA GPUにいれて使用する例で比較してみましょう。
RTX A5000(24GB)- エントリーモデル
モデル重みデータ16GBをロードした後、残りは約6GB(安全領域10%を考慮)。これは6件の同時リクエスト処理に相当します。小規模導入や部門単位の利用に適しています。
RTX A6000(48GB)- ミッドレンジモデル
同じモデルでも28GBのKVキャッシュ領域が確保でき、28件の同時リクエストを処理可能。中規模企業や複数部門での共有利用に最適です。
RTX A100(80GB)- ハイエンドモデル
56GBものKVキャッシュ領域により、理論上56件もの同時リクエストを処理できます。大規模な社内サービスや、多くのユーザーが利用するシステムに向いています。
Aシリーズはアンペア世代と呼ばれ、2025年現在ではやや古いGPUに相当しますが、(今思えば)性能に対してかなりリーズナブルな価格設定で、今でも現役です。
理論値と実際の性能差に注意
メモリ計算に基づく同時処理数は「理論上の上限」であることを忘れないでください。実際には、同時リクエスト数が増えるにつれて推論速度(トークン生成速度)は徐々に低下します。これはGPUの計算リソースが複数のリクエスト間で共有されるためです。
例えば、A100で50件の同時リクエストを処理すると、メモリ的には問題なくても、各リクエストの推論速度が目標を下回る可能性があります。STEP1で設定した推論速度(例:25トークン/秒)を維持できる実際の同時リクエスト数は、負荷試験を通じて検証する必要があります。
選定のポイント
GPUを選ぶ際のポイントをまとめますと
- ピーク時の同時リクエスト数を把握する
STEP2で計算したピーク時のリクエスト数をカバーできるか? - 推論速度の要件を考慮する
同時処理数を増やすと推論速度は低下する - コストパフォーマンスを検討する
高価なGPU一台か、安価なGPU複数台か? - 拡張性を見据える
将来的なユーザー増加に対応できるか?
現実的なアプローチ
予算と性能のバランスを取るなら、RTX A6000クラスのGPUが多くの企業にとって現実的な選択肢です。これなら中規模の同時リクエスト(20〜30件程度)を処理でき、コスト面でもA100より大幅に抑えられます。
利用者が少ない小規模導入ならRTX A5000も検討価値があります。逆に、大規模な全社的サービスや、特に高い推論速度が求められる用途では、A100の投資効果が得られるでしょう。
どのGPUを選ぶにせよ、メモリ計算だけでなく実際の負荷試験を行い、ユーザー体験に直結する「推論速度」と「応答時間」を検証することを忘れてはいけません。
モデルを小さくするか、GPUを増やすか
さて、前節では、1台のGPUのメモリと同時アクセスについてみました。
1台のGPUが多くのリクエストを捌くと1つのリクエストあたりの推論速度が落ちることを説明いたしました。また1つのGPUにのせられるモデルサイズはGPUに搭載されるGPUメモリに制約されることもこれまで見てきた通りですね。
では、ここからはさらにメモリを効率化したり、さらに推論速度を増やすためのテクニックについてみていきたいとおもいます。
実際のサービスでは、より大規模なLLMモデルの運用や、多数の同時リクエストを処理する必要があります。
このようなとき効率的なGPUノード構成を設計するには、主に「量子化アプローチ」と「並列化アプローチ」の2つの戦略があります。
さっそく、それぞれの特徴と適用シーンを見ていきましょう。

量子化によるメモリ効率化
量子化とは、モデルの精度を若干犠牲にする代わりに、メモリ使用量を大幅に削減する技術です。同時処理数を増やすためには、KVキャッシュ用領域を広げる必要があり、そのためにはモデルのフットプリント(GPUに読み込まれる際のメモリ使用量)を削減することが効果的です。
例えば、標準的な16ビット精度(FP16)のモデルを8ビット(INT8)や4ビット(INT4)に量子化することで、モデルのフットプリントを半分あるいは4分の1に削減できます。これにより、同じGPUメモリ内に保存できるKVキャッシュの量が増え、同時に処理できるリクエスト数を増やすことが可能になります。
量子化は特に以下のケースで有効です
- 単一GPU内で同時リクエスト処理能力を高めたい場合
- コスト効率を重視する場合
- 推論速度よりも処理能力を優先する場合
ただし、量子化レベルを下げるほど生成品質に影響が出る可能性があるため、サービス要件に合わせた適切なバランスを見つけることが重要です。
ひとことに量子化といっても、その手法は1つではなく複数の効果的な方法が提案されています。またモデルの構造により使用できる量子化手法、できない量子化手法があります。昨今ではオープンモデルが出ると速くて数時間以内に量子化モデルが HuggingFace にアップロードされる傾向があり自分で量子化をしなくてもコミュニティが量子化してくれたモデルを気軽に試すこともできるようになってきました。
主要な量子化アルゴリズム比較表
| アルゴリズム | 特徴 | 主な利点 | 適した用途 |
|---|---|---|---|
| AWQ | アクティベーション特性を考慮した重み量子化 | ・高い精度保持<br>・チャネル単位の混合精度<br>・推論速度の大幅向上 | ・限られたGPUメモリでの大規模モデル実行<br>・NVIDIA GPUでの高速推論 |
| GPTQ | 層ごとの逐次量子化と誤差補正 | ・実装が比較的容易<br>・広いモデル互換性<br>・Hugging Face対応 | ・バッチ処理が少ない推論<br>・幅広いモデルタイプに適用 |
| bitsandbytes | ダイナミックな8ビット/4ビット量子化 | ・PyTorchとの緊密な統合<br>・LLM.intオプティマイザ<br>・学習時量子化対応 | ・Hugging Faceモデルの学習・推論<br>・限られたGPUでの大規模モデル微調整 |
| GGUF | 統一されたモデルフォーマットと量子化 | ・CPU推論との相性良好<br>・オープンソースエコシステム<br>・KVキャッシュ量子化対応 | ・コンシューマーハードウェアでの推論<br>・Llama/Mistralモデルファミリー |
| QLoRA | 量子化モデルの低ランク適応微調整 | ・メモリ効率的な微調整<br>・量子化モデルの直接調整<br>・大規模モデルのメモリ要件削減 | ・限られたGPUリソースでの微調整<br>・量子化と微調整の両立 |
量子化のビット数と効果
| ビット数 | メモリ削減率 | 速度向上 | 精度影響 | 推奨用途 |
|---|---|---|---|---|
| 8ビット | 約50% | 1.5-2倍 | 最小限 | 高精度が必須の本番環境 |
| 4ビット | 約75% | 3-4倍 | 小~中程度 | 一般的なLLMアプリケーション |
| 1+ビット | 約87-90% | 5-7倍 | 大きい | 極めて限られたリソース環境、精度より速度優先の場合 |
量子化選択のポイント
使用するハードウェア、モデルタイプ、必要な精度、リソース制約に基づいて最適なアルゴリズムとビット数を選択しましょう。最新のLLM推論環境では、4ビット量子化が精度と効率のバランスが最も優れた選択肢となっています。また4ビット量子化が普及するにつれNVIDIA GPU側にもGPUネイティブな4ビット量子化がサポートされるようになってきており、さらなる高速化に貢献しています。
並列化による処理能力の向上
さて、もう一つの重要なアプローチが「並列化」です。これは複数のGPUをクラスターとして活用し、負荷を分散させる方法です。並列化には主に二つの方式があります
モデル並列化
1つのGPUにおさまらない大きなフットプリントのモデルを使用する場合に適用します。モデルの重みを複数のGPUに分散させて格納する技術です。例えば、70B(700億パラメータ)クラスのモデルは、単一のミドルレンジGPUにはロードできないため、複数のGPUに分散させて使用するのが一般的です。
モデル並列化は以下の場合に有効です
- 大規模なモデル(70B~100B以上など)を使用する場合
- 高い生成品質を維持したまま、大規模モデルを運用したい場合
- 量子化による品質低下を避けたい場合
データ並列化
小さなGPUで同時処理数を増やしたい場合に適用します。複数のGPUをクラスター化して負荷を分散させる方法です。各GPUには同じモデルのコピーがロードされ、異なるリクエストが各GPUに分配されます。
データ並列化は以下の場合に有効です
- 中小規模のモデル(7B〜13Bクラス)で高いスループットが必要な場合
- 多数の同時ユーザーをサポートする必要がある場合
- リソースを効率的に使用したい場合
これらの戦略を適切に組み合わせることで、コスト効率と性能のバランスが取れたGPUノード構成を実現できます。なお、具体的なGPUノード構成の見積もりは専門エンジニアによるきめ細かな設計が推奨されます。
以下、当社Youtubeチャンネルで並列化の具体例を解説していますので、あわせてごらんくださいませ
STEP6:負荷試験
GPUノード構成が決まったら、次は実際のピーク負荷を再現してシステムが要件を満たせるかを検証する「負荷試験」を実施します。これはLLMサービスを本番環境に展開する前の重要なステップです。

負荷試験の概要
ピーク時の同時リクエストをエミュレーションできる負荷試験ツールを使用して、以下のような観点から性能を検証しま:
- 同時リクエスト処理能力(Concurrency)
- GPU消費メモリ量
- 推論速度(トークン/秒)
- レスポンス時間
- システム安定性
負荷試験には、LocustやJMeterなどの一般的なWebアプリケーション用負荷試験ツールも使用可能です。また、当社Qualitegではアルファ版ながらLLM専用の負荷試験ツール「LLMLoad」も提供しております。
実施要項と測定手順
効果的な負荷試験のために、以下のような手順で実施します
- テスト用プロンプトの準備
最大シーケンス長に近い文章生成を行わせるプロンプトを用意します。実際のユースケースに近いプロンプトを用いることが重要です。 - 段階的な負荷テスト
同時リクエスト数(Concurrency)を徐々に上げていきます。例えば、1, 5, 10, 20, 30と段階的に増やして、各ステップでの性能を測定します。 - 各段階での測定
各Concurrencyレベルにおいて、推論速度(トークン/秒)と実際の消費メモリ量を計測します。特に重要なのは、STEP1で設定した最低推論速度(例:25トークン/秒)を下回らないこと、そしてGPUメモリ使用量が総容量の90%程度に収まることです。 - 限界値の特定
これらの測定を通じて、ピーク時に最低推論速度を達成できるGPUユニット数を確定します。 - 問題の特定と解決
もし期待通りの結果が得られない場合は、STEP4(推論エンジン選定)とSTEP5(GPUノード構成見積もり)に戻り、GPUの種類や構成を見直します。必要に応じて何度も繰り返しテストを行います。
負荷試験は単なる形式的な手続きではなく、実際のサービス品質を左右する重要なプロセスです。特に、最大同時ユーザー数の見極めや、エラー発生時の挙動など、本番環境でのトラブルを未然に防ぐための貴重な情報を得ることができます。
STEP7:トレードオフ検討負荷試験
最後のステップとして、負荷テストの結果を基にコストと性能のトレードオフを検討します。このプロセスは、最終的なGPU構成を決定するための重要な判断ポイントとなります。

トレードオフ検討の要点
複数のGPUノード構成で測定結果が出そろったら、以下のような観点から最適な構成を検討します
- 高性能GPUと低性能GPU
当然ながら、先端のデータセンター用GPU(A100, H100,B200など)を利用するとconcurrencyを高くできてリッチな体験を提供できますが、GPUコストも比例して高くなります。一方、低性能なGPUを複数台でテンソル並列化するとコストは抑えられますが、ネットワークレイテンシにより推論速度が低下する可能性があります。この場合、concurrencyを最低限にする必要が出てくることもあります。 - モデルサイズによる考慮点
小さなモデル(7B以下)の場合はテンソル並列化の必要性は低いですが、大規模モデル(70B以上)ではネットワークレイテンシの影響が気になるため、十分な測定を繰り返す必要があります。 - コストと体験のバランス
最終的には、許容できるコストの範囲内で最高のユーザー体験を提供できる構成を選ぶことになります。ここでは、初期コスト(CAPEX)と運用コスト(OPEX)の両方を考慮することが重要です。
これらの検討を通じて、最終的なGPU構成が決まり、調達すべきGPU台数が確定します。重要なのは、単純に「最高性能」や「最低コスト」を追求するのではなく、サービス要件に最適なバランスを見つけることです。
総括:LLM推論基盤プロビジョニングの体系的アプローチ
この講座全体を通じて、LLM推論基盤を構築するための7つのステップについて解説してきました
- 推論速度の定義
サービス要件に基づく推論速度目標の設定 - リクエスト数見積もり
ユーザー数と利用パターンからの同時リクエスト数計算 - 使用モデルの推論時消費メモリ見積もり
モデルのフットプリントとKVキャッシュ計算 - 推論エンジンの選定
用途に合った最適な推論エンジンの選択 - GPUノード構成見積もり
量子化と並列化戦略の検討と構成設計 - 負荷試験
実際の使用条件に近い環境での性能検証 - トレードオフ検討
コストと性能のバランスを考慮した最終決定
これらのステップを体系的に実施することで、過剰投資を避けつつ、必要十分な性能を持つLLM推論基盤を構築することができます。
特に初期段階での正確な見積もりと計画が、後の大幅な設計変更や予算超過を防ぐ鍵となります。
LLM技術は日進月歩で進化しており、推論技術も急速に発展しています。最新の技術動向を常にキャッチアップしながら、自社のニーズに最適な推論基盤を設計・構築することが重要です。また、実際の運用フェーズに入ってからも継続的なモニタリングと最適化が必要となります。
LLMの自社活用を検討されている企業の皆様にとって、この講座が効率的な推論基盤構築の一助となれば幸いです。GPU資源を最大限に活用し、コスト効率の高いLLMサービスを実現するためのプランニングに、ぜひこの7ステップアプローチをお役立てください。
LLM/AIセキュリティのことなら株式会社Qualiteg
私たちQualitegは、LLMの推論・サービング基盤を実際に設計してきたエンジニアリングチームを有しており推論エンジンを単なる箱として扱わず、アテンション計算やKVキャッシュの挙動など深い知見をベースにしたローカルLLM技術のご支援を提供しています。「VRAMに収まる構成はどこか」「vLLMとHugging Face、判断軸は何か」「既存モデルを自社ドメインへ適応させる最短経路は」「オープンLLMと商用LLMの使い分け」「セキュアなローカルLLM構成はどうすればいいか」「ローカルLLMとGPUの選び方」「GPUデータセンターの需要と市場予測」「AI市場予測」などコア技術からAI市場分析まで、お気軽にご相談くださいませ。



