
Mistral AI社の最新LLM「Mistral NeMo 12B」を徹底解説

こんにちは。今回は2024年7月19日にリリースされたMistral AI社の最新LLM「Mistral NeMo 12B」をご紹介します。
本モデルの特徴や性能を解説し、実際にChatStreamを使用してチャットの使用感を確かめていきます。
Mistral NeMo 12Bとは
Mistral NeMo 12BはMistral AI社がNVIDIAと協力して開発した最新モデルです。Apache2ライセンスを採用しており、自由に使用、変更、配布が可能な非常に自由度の高いモデルとなっています。

解説動画
本記事の内容は以下の動画にもまとめてありますので、あわせてごらんくださいませ
主な特長
本モデルには3つの大きな特長があります:
- 大きなコンテクストサイズと高い推論性能
- 多言語性能
- 効率的なトークナイザー
1. 大きなコンテクストサイズと高い推論性能
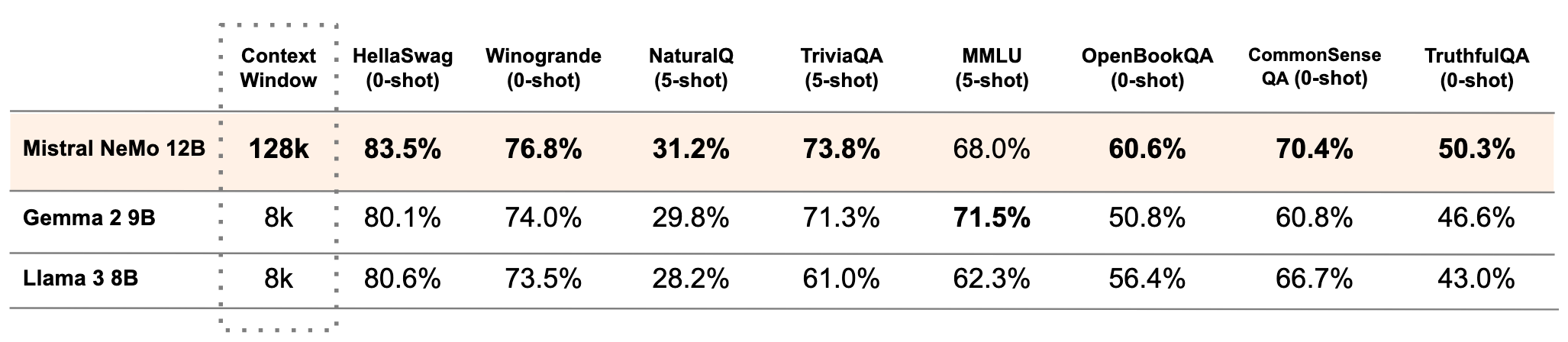
Mistral NeMo 12Bは120億パラメータの比較的小型のモデルですが、同サイズカテゴリーの中でも高い性能を発揮しています。Google社のGemma2 9BやMeta社のLlama3 8Bと比較すると、特にコンテキストウィンドウが際立っています。Mistral NeMo 12Bのコンテキストサイズは128000で、これは他の2つのモデルの16倍のサイズです。
2. 多言語性能
Mistral NeMo 12Bは多言語対応に優れています。英語はもちろん、日本語、フランス語、ドイツ語、スペイン語、イタリア語、ポルトガル語、中国語、韓国語、アラビア語、ヒンディー語など、幅広い言語で高いパフォーマンスを発揮します。
- マルチタスク言語理解ベンチマーク「MMLU」のスコア:68%(GPT-3.5 Turboの69.8%と同等)
- 日本語理解能力を評価したJMMLUのスコア:59%
3. 効率的なトークナイザー
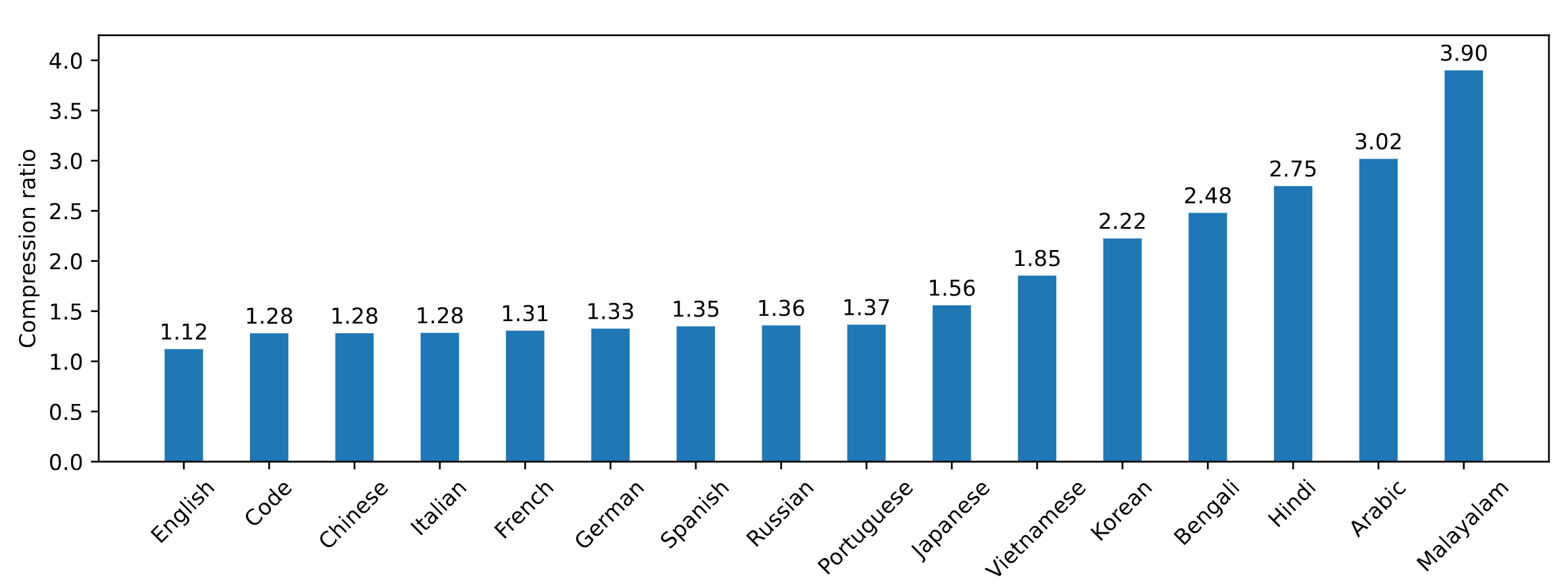
新しい圧縮技術「Tekken」の採用により、自然言語テキストやソースコードの処理効率が大幅に向上しています。特に日本語では1.56倍の効率化を実現しています。
実際のチャット体験
ChatStream.netを使用して、Mistral Nemo 12Bとのチャットを試してみましょう。
以下URLで実際にチャットを試すことができます
https://chatstream.net/?model_id=mistral_nemo_instruct_2407&ws_name=chat_app
上記動画では以下のようなものを試してみました
- Mistral AI社について日本語で質問
- 同じ質問を英語で回答してもらう
- フランス語での回答を試す
- 映画「タイタニック」に関する質問
- ジェームズ・キャメロン監督の作品について質問
- 「ターミネーター2」の登場人物について質問
- 同じ質問を英語で行い、回答の正確性を比較
結果として、英語での回答のほうが日本語よりも正確性が高いことが分かりました。
コード生成能力
また、温度変換やリスト処理のPythonコードを生成してもらったところ、正確なコードと丁寧な説明が得られました。
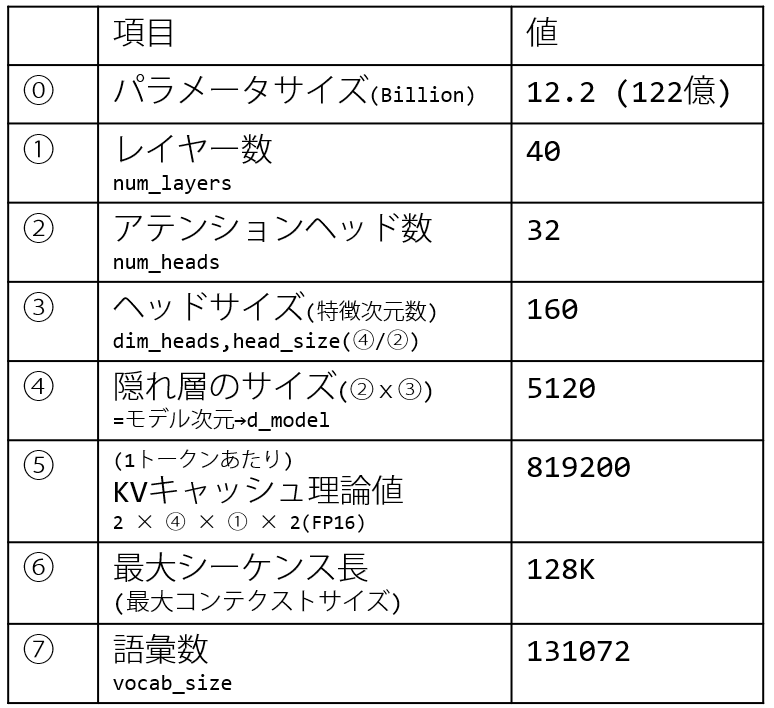
モデルアーキテクチャ詳細
推論環境
今回使用した推論環境は以下のとおりです。
- GPU:A5000
- OS:Ubuntu
- 推論エンジン:当社オリジナルのダイナミックバッチ・連続バッチ推論エンジン(通称"クラシックエンジン")
- 推論サーバー:ChatStream Server
- UI:ChatStream WebUI
ChatStream SDKを使用することで、約20分でMistral NeMo 12Bのチャット環境をインターネットに公開することができました。

まとめ
Mistral NeMo 12Bは、コンパクトなサイズながら高い性能を持つ多言語LLMです。特に大きなコンテキストサイズと効率的なトークナイザーが特徴的で、RAGなどの実践的な用途に強みを発揮しそうです。
生成AIのお悩み、LLMを活用した新規事業、LLMサービスの構築については、当社Qualitegまでお気軽にご相談ください。



