
革新的なコード生成LLM "Codestral Mamba 7B" を試してみた

今日は、2024年7月16日にリリースされた新しいコード生成LLM、"mistralai/mamba-codestral-7B-v0.1"(通称:Codestral Mamba 7B)を試してみました。
このモデルは、新しいMambaアーキテクチャを採用しており、Apache2ライセンスで公開されています。
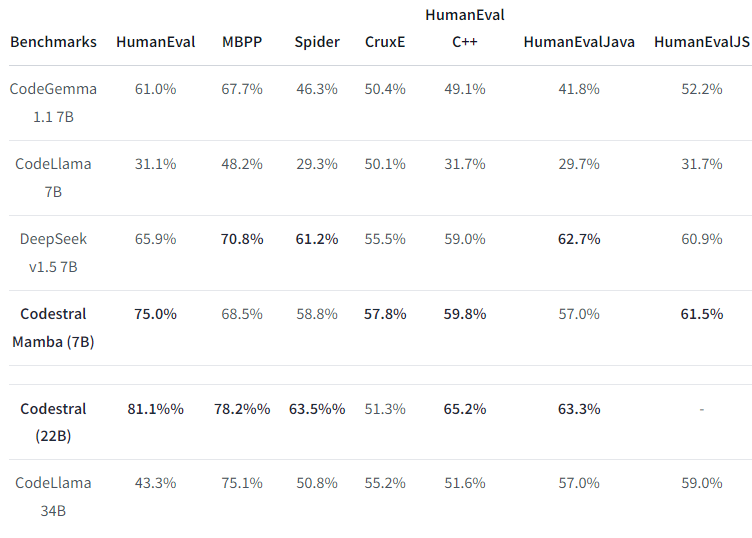
コード生成のSOTAモデルに迫る性能
Mamba アーキテクチャを採用した Codestral 7B ですが、Human Eval で 75% を達成しており、Transformerベースのコード生成 SOTA モデルと同等のパフォーマンスを実現しています。
さらに、シーケンス長に対しての処理劣化がないため、かなり期待のできるモデル&アーキテクチャといえますね。
動画にまとめています
"mistralai/mamba-codestral-7B-v0.1" の試用レポートはこちらの動画にもまとめてありますので、よろしければ、こちらもご覧くださいませ
Codestral Mamba 7Bの特徴
- 無限の長さのシーケンスをモデル化する能力
- 長いシーケンスでも高速処理が可能
- Transformerベースの最高性能モデルと同等のパフォーマンス
実験内容
- Pythonプログラムの生成
- 1から1000までの和の計算
- 1から100までの偶数の表示
- フィボナッチ数列の生成
- 摂氏から華氏への変換
- ランダムパスワードの生成
- リスト内の2番目に大きい数の抽出
- コード補完
- 文字列反転関数
- 平均計算関数
- リストのフラット化関数
- BMI計算関数
- 長文指示によるコード生成
- Mistral LLMを使用した対話型チャットの作成
結果
Codestral Mamba 7Bは、各タスクにおいて満足のいく出力をだしてくれました。プログラムの生成では正確なコードを出力し、コード補完では適切な実装を提案してくれました。長文指示に対しても、APIを使用した対話型チャットのコードを生成するなど、柔軟な対応を見せてくれていました。
まとめ
今回はCodestral Mamba 7Bのファーストルックレポートをお届けいたしました。
様々なPythonプログラムの生成や関数の補完を通じて、その性能の高さと可能性を実感することができました。
まだ、本格的なコード生成を試せていないため、これから実務レベルのコードが生成できるのか、という観点でさらに試してみたいと思います!



