
日本語対応!Mistral Small v3 解説

こんにちは!
Mistral AIは2025年1月30日、新しい言語モデル「Mistral Small v3」を発表しました。このモデルは、24Bという比較的小規模なパラメータ数ながら、70B以上の大規模モデルに匹敵する性能を実現しています。また日本語対応も謳われており期待の高い小型モデルです!
https://huggingface.co/mistralai/Mistral-Small-24B-Instruct-2501
動画
こちら本ブログの解説動画もご覧いただけます😊
きわだってるのは、レイテンシー最適化
Mistral Small 3のめだった特徴は、その処理性能とレイテンシーの絶妙なバランスではないでしょうか。
公開されている以下の性能評価のグラフによると、トークンあたり約11ミリ秒という業界最速レベルのレイテンシーを達成しています。これは、Qwen-2.5 32Bの約15ミリ秒やGemma-2 27Bの約14ミリ秒と比較して、明確な優位性を示しています。さらに注目すべきは、GPT-4o Miniと比較しても、より低いレイテンシーで同等以上の性能を実現していることです。
(vLLMをつかってバッチサイズ16 H100x4 での計測値のようです)
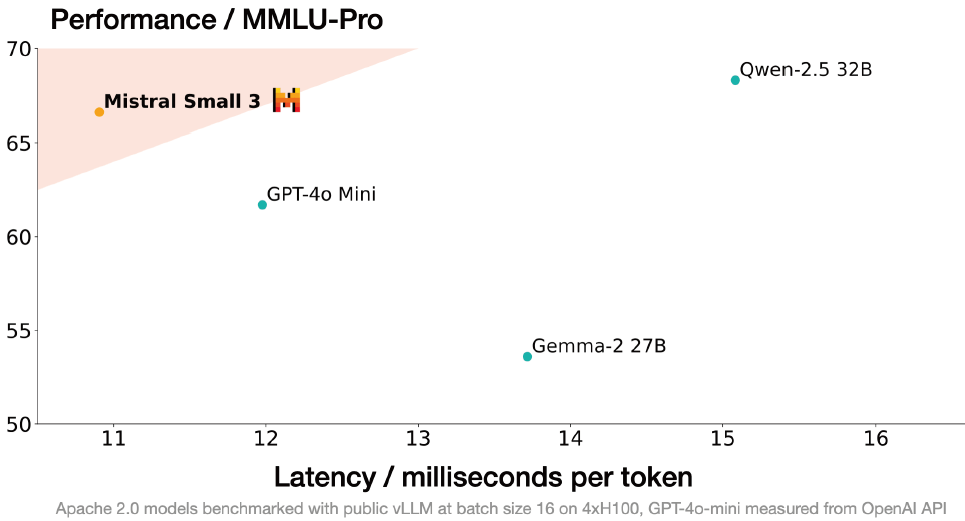
MMLUベンチマークにおいては81%という高精度を達成しながら、150トークン/秒という処理速度を実現しています。これは、同等の性能を持つLlama 3.3 70B instructと比較して3倍以上の高速化が実現されたことになりますね。高速性と精度の両立は、実用的なAIアプリケーションの開発でうれしいですね。
包括的な性能評価と実証された優位性
第三者機関による厳密な評価では、1,000以上の多様なプロンプトを用いた比較テストが実施されました。Gemma-2-27Bとの比較では、実に73.2%のケースでMistral Small 3が優位性を示し、その内訳は53.6%が「明確な優位性」、19.6%が「やや優位」という結果でした。
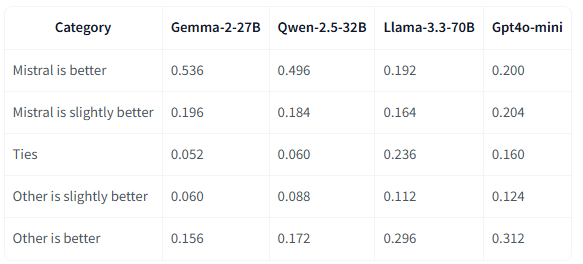
同様に、Qwen-2.5-32Bとの比較でも68%のケースで優位性を示し、より大規模なLlama-3.3-70Bとの比較でも、35.6%のケースで優位、23.6%で同等という結果を残しており軽量級モデルの競争に一石を投じるモデルとなっています
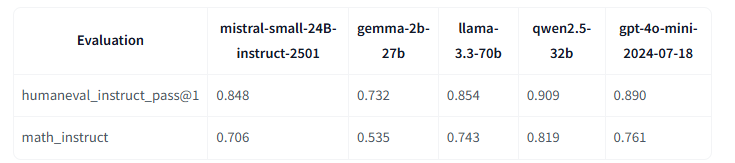
技術的なベンチマークテストにおいてはMMLU Pro(5-shot CoT)で66.3%、GPQA mainで45.3%という高スコアを達成。特に注目すべきは、HumanEvalにおける84.8%という高い合格率と、数学タスクでの70.6%という精度です。さらに、指示追従性能を測るMTBenchでは8.35/10、Arena Hardでは87.3%という優れた結果を示しており、実用的なタスクにおける高い信頼性が証明されています。
さて、庶民感覚からすると、話題のDeepSeek R1 との関係はどうなんだろう?って思うのではないでしょうか。
真面目にいうと、階級が違う(DeepSeekR1はヘビー級で Mistall Smallはライト級ってとこでしょうか。)ので比較してもあまり意味はないっちゃないのですが、ならべてみましょうか。
【コラム】話題のDeepSeek R1 と Mistral Small 24B と比較表
せっかくなので話題のDeepSeek R1 とも比較してみましょう。
以下では、DeepSeek R1(32B規模のバージョンを想定) と Mistral Small v3 24Bを中心に、代表的なベンチマークや主要仕様を比較します。両モデルとも設計や規模が異なるため、厳密な意味での比較は適切ではありません。あくまで目安としてお考えください。
なるべく階級をちかづけるために DeepSeek R1 32B蒸留版でみてみましょう
| 項目 | DeepSeek R1(Distilled 約30B版) | Mistral Small 24B(約24B) |
|---|---|---|
| モデル規模 | 約30〜32B (Distilled版)※ 元のフルモデルは MoE (合計数百B規模) | 約24B (Dense Transformer) |
| ライセンス / 公開度 | DeepSeek/MIT | Apache 2.0 (完全オープン)誰でもダウンロード&商用利用可 |
| MMLU (知識ベンチマーク) | ~80% 前後(推定値)※ Distilled版の推測値。フル版 R1 (MoE数百B) は ~90% 超との報告例あり | 80~81% 程度70B級のモデルに匹敵 |
| コード生成 (HumanEval 等) | ~90% pass@1(Distilled版でもコード能力が高い傾向)※ 実運用タスクに近い大規模テストでは要検証 | ~85% pass@1コード対応ベンチマークで高水準 |
| 推論速度 (参考) | - 30〜40 token/s 程度 (A100 80GB, FP16時)※ モデルサイズがやや大きめ。- フル版はさらに低速になる場合あり | - 40〜50 token/s 程度 (A100 80GB, FP16)- レイヤー圧縮と高速化実装により低レイテンシに注力- 4bit/8bit量子化でさらに高速化可能 |
| 学習データ / 手法 | - 超大規模 (~14.8T tokens) のWeb/書籍/ドメインコーパス- RL (強化学習) や MoE を活用し高精度化 (フル版) | - 多言語 + コード中心- Instruction Tuningのみ (RLHFなし)- 汎用用途におけるベースモデルとしての性格が強い |
注: 各数値・推論速度・ベンチマークスコアなどは、コミュニティや企業レポートを参照した推定値も含んでいます。正式なデータはモデル提供元の最新ドキュメントをご確認ください。
注意事項
- そもそもモデル階級(設計思想・規模)が異なり、正確な意味で比較するのは難しいですがミーハー精神で比較してます。DeepSeek R1 はフル版では数百B (MoE) という超大規模に分類される一方、Mistral Small 24B は「軽量かつ高速」を目指した中規模モデルです。
- したがって上記表の数値はあくまで同程度のパラメータ規模を持つ DeepSeek R1 Distilled 版との参考比較にすぎません。最終的には導入環境やタスク要件によって、どちらが向いているか異なります。
多言語処理能力の卓越性
さてさて、Mistral Small 3の多言語処理能力にも注目ですね。
日本語では約73%という優れた性能を示しており、欧州言語圏では、フランス語で約78%、ドイツ語で約77%、スペイン語で約78%、ロシア語で約75%という高いスコアを達成しています。アジア言語においても、中国語で約72%、韓国語では約58%とやや低めながらも、全体として非英語コンテンツに対する優れた処理能力を実証しています。
この多言語対応力は、131,000語という豊富な語彙を持つTekkenトークナイザーの採用と、32,000トークンという広範なコンテキストウィンドウの実装によって支えられています。これにより、複雑な文脈理解や長文処理において、より自然で正確な言語処理が可能となっています。
実装アーキテクチャと技術的革新
Mistral Small 3の技術的な革新性は、そのアーキテクチャ設計にも表れています。BF16形式での効率的な処理を実現し、システムプロンプトへの最適化対応を強化することで、より自然な対話と正確な応答を可能にしています。標準的な実行環境ではBF16またはFP16形式で約55GBのGPU RAMを必要としますが、量子化オプションの実装により、より軽量な環境でも運用が可能です。
また、量子化により、単一のRTX 4090グラフィックスカードや32GBのRAMを搭載したMacBookでも実行可能です。この実用的な要件設定により、中小規模の組織や個人開発者でも、高性能な言語モデル活用の選択肢がまた1つ追加されましたね。
プラットフォーム展開と開発環境の充実
現在、当社ChatStreamをはじめ、Hugging Face、Together AI、Fireworks AIなどの主要プラットフォームですでに利用可能となっており、開発者は自身のプロジェクトに容易に組み込むことができます。さらに、NVIDIA NIM、Amazon SageMaker、Groq、Databricks、Snowflakeなどの主要クラウドプラットフォームでも近日中にサービス提供が開始される予定です。
またローカルにおいても、vLLMなど使いやすいエンジンの互換性があるため、既存のAIプロジェクトへの統合を容易にする重要な特徴となっています。
まとめ
DeepSeek R1の話題でもちきりのLLM界隈ですが、Mistral Small 3も着実に性能をあげてきており軽量高性能なAIモデルの実用化における重要なマイルストーンとなるのではないでしょうか。特に日本にNative対応している点はわたしたち日本人には大きなポイントですね!
なお、当社ChatStreamを使うと、Mistral Small 3 も、ノーコードでデプロイすることができ、本格的な商用LLMサービスを簡単に構築することが可能です!Mistal Small3 を使用した商用開発についていつでもお気楽にご相談くださいませ!



