
楽観的ロック vs 悲観的ロック:実際のトラブルから学ぶ排他制御

こんにちは!
Qualitegプロダクト開発部です!
「楽観的ロックを実装したのに、まだ競合エラーが出るんですけど...」
これは私たちが実際に経験したことです。
本記事では、楽観的ロックと悲観的ロックの違いを、実際に発生したトラブルを通じて解説します。
抽象的な説明ではなく、
「なぜそれが必要なのか」「どんな問題を解決できるのか」
を実感できる内容を目指します。
目次
- 問題の背景:並列処理で謎のエラー
- ロックなしの世界:なぜ競合が起きるのか
- 楽観的ロックの導入:期待と現実
- 楽観的ロックの限界:解決できなかった問題
- 悲観的ロックによる解決
- 実装時のハマりポイント
- どちらを選ぶべきか:判断基準
- まとめ
1. 問題の背景:並列処理で謎のエラー
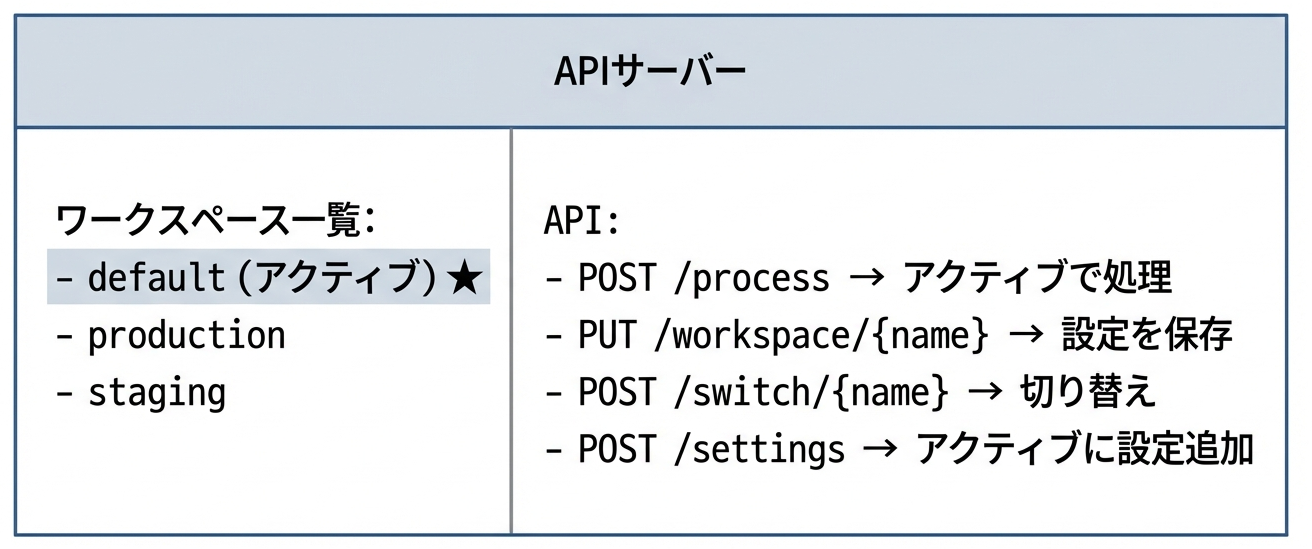
1.1 システムの概要
私たちが開発していたのは、
複数のワークスペースを切り替えて使用するAPIサーバー
でした。
当社AI関係のプロダクトの一部だったのですが、結合テスト兼負荷テストを実行すると、まれに発生してしまっていました。
ユーザーは複数のワーキングセット(設定セット)を作成でき、その中から1つを「アクティブ」として選択できる機能があります。
1.2 発生したエラー
並列でリクエストを処理すると、以下のエラーがランダムに発生しました。
Error: HTTP Error 500: Cannot modify protected workspace 'default'
単独で実行すると成功するのに、複数クライアントが大量同時にアクセスすると失敗します。
しかも、失敗するリクエストは毎回違うという現象です
これは典型的な競合状態(Race Condition)の症状ですね。いちばんいやな感じのやつです。
2. ロックなしの世界:なぜ競合が起きるのか
2.1 用語の定義
さて、本題に入る前に、この記事で使う用語を定義しておきます。
グローバル状態とは、複数のクライアントから共有され、かつ暗黙的に参照される状態のことです。本記事の例では「現在アクティブなワークスペースがどれか」という情報がこれに該当します。
2.2 問題の原因
調査の結果、以下のシナリオで問題が発生していることがわかりました。
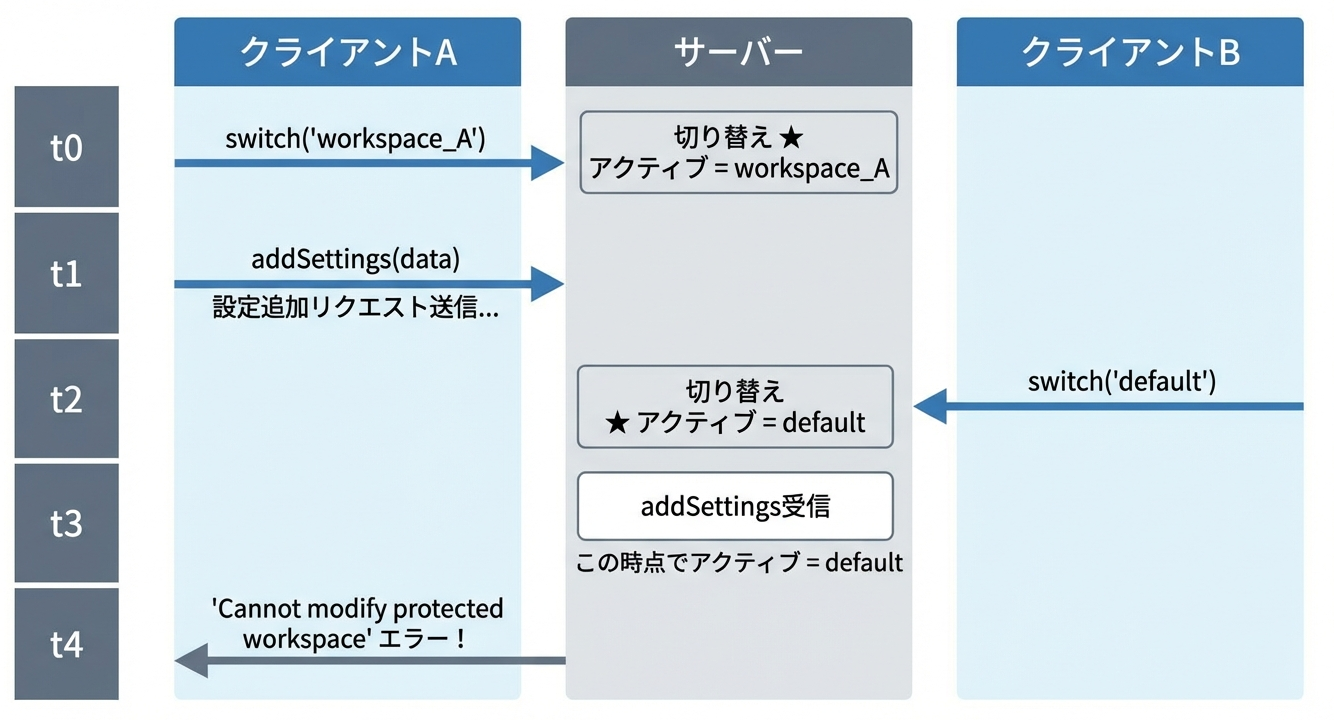
クライアントAの視点で見てみますと、
- 自分のワークスペース
workspace_Aをアクティブ化した - そのワークスペースに設定を追加しようとした
- なぜか
defaultへの変更エラーが返ってきた
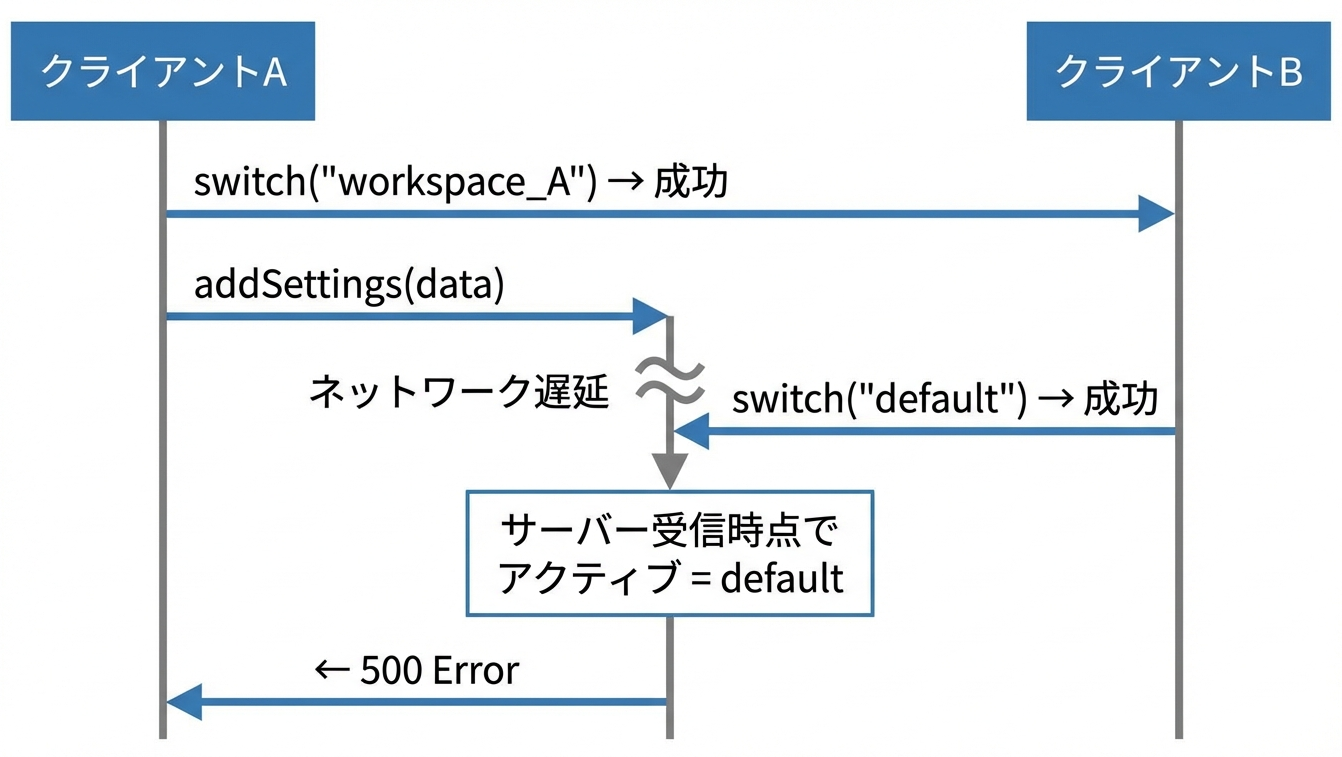
何が起きたかというと、クライアントAがリクエストを送信してからサーバーに到達するまでの間に、クライアントBがアクティブワークスペース(グローバル状態)を切り替えてしまったのです。
2.3 問題の本質
問題の本質はなんだったのでしょう。そう、この問題の本質は、
複数のAPI呼び出しにまたがる操作
にあります。
await client.switch("workspace_A"); // 操作1: 切り替え
await client.addSettings(data); // 操作2: 設定追加 ← ここで問題
await client.process(input); // 操作3: 処理実行
操作1と操作2の間には時間差があり、その間に他のクライアントがグローバル状態を変更できてしまいます。
これは
TOCTOU(Time Of Check To Time Of Use)問題
と呼ばれる典型的な競合状態です。
DBでいうと、「トランザクション」操作に近いですね。
3. 楽観的ロックの導入:期待と現実
3.1 楽観的ロックとは
さて、ここで考え付くのは楽観的ロックです。
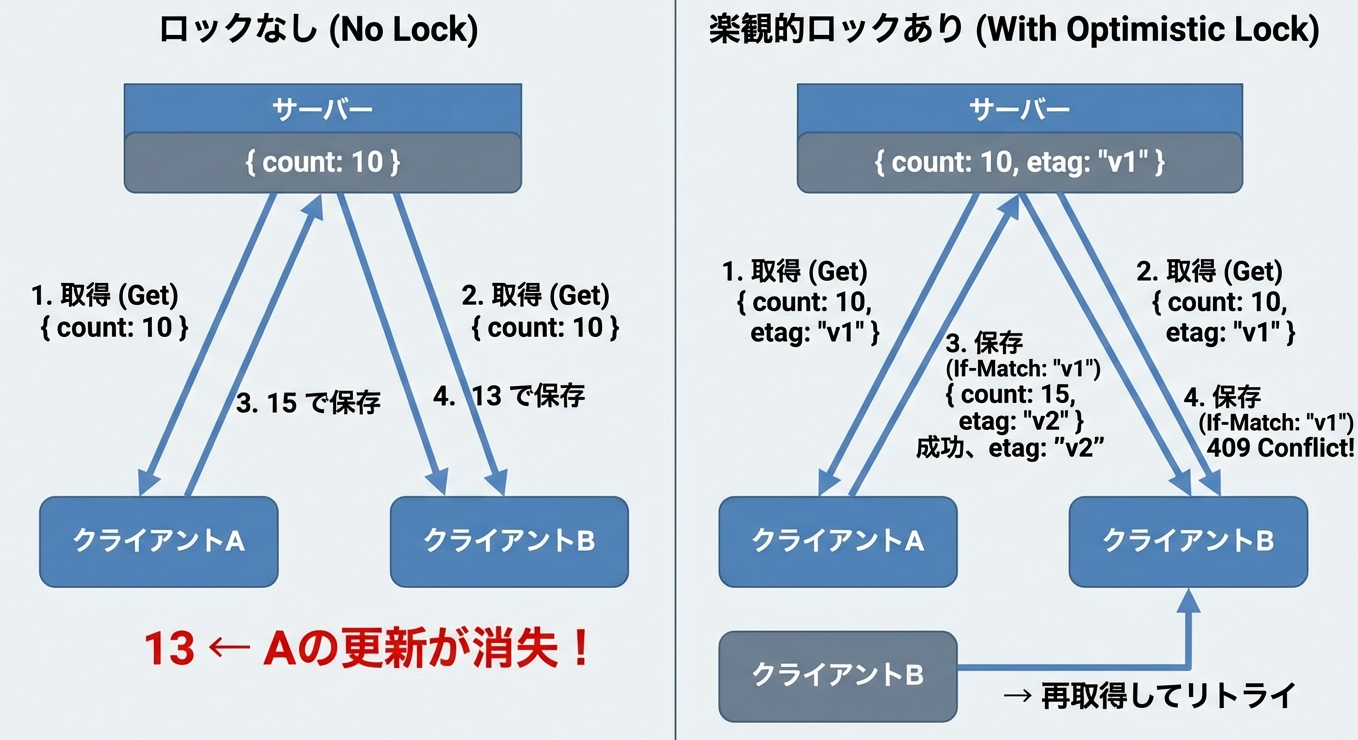
「楽観的ロック(Optimistic Locking)」は、競合はめったに起きないという前提に基づく方式です。
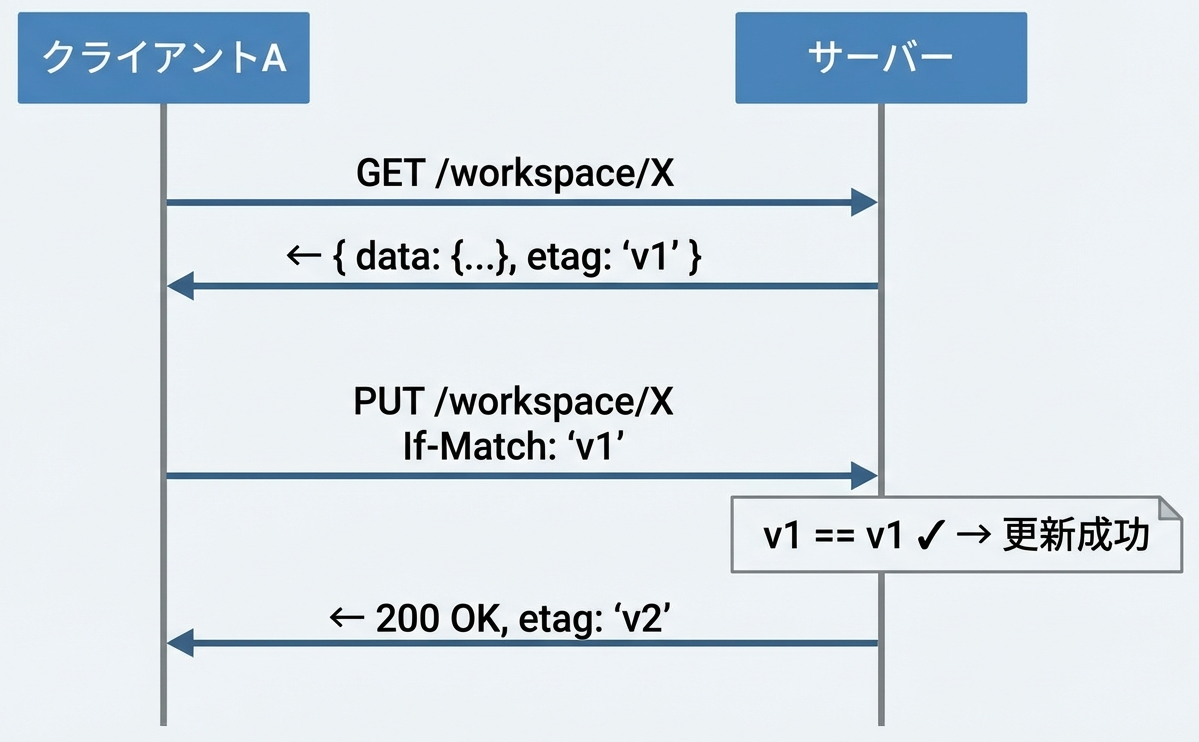
基本的な仕組みは以下のとおりです。
- データ取得時にバージョン情報(ETag等)を受け取る
- 更新リクエストにバージョン情報を含める
- サーバーはバージョンが一致する場合のみ更新を許可
- 不一致の場合は「409 Conflict」を返す
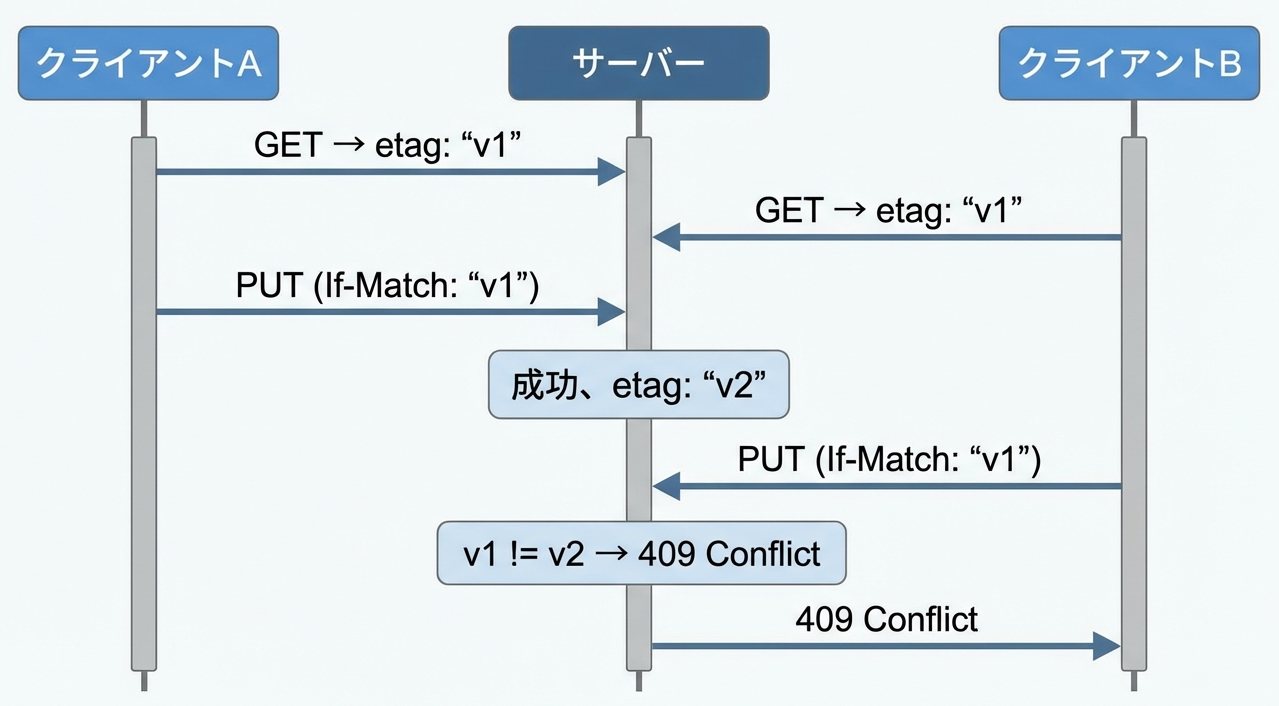
そして、競合が発生した場合はこうなります。
3.2 楽観的ロックが解決できること
楽観的ロックに解決できることはなんでしょうか。
はい、楽観的ロックはLost Update(更新の消失)問題を解決することができます。
4. 楽観的ロックの限界:解決できなかった問題
4.1 期待した動作
そして、排他制御なら楽観的ロックと短絡して、さっそくその実装してみました。
競合問題が解決されると信じて
4.2 現実
しっかし、、、同じエラーが発生し続けました。。
4.3 なぜ解決できなかったか
なぜうまくいかなかったか、いろいろ分析デバッグするなかで、3つの理由にきづきました。(まなびました)
1. 競合しているのはワークスペースの「内容」ではない
競合しているのは「アクティブなワークスペースが何か」というグローバル状態です。
2. ETagを付けても意味がない
ETagは「データの内容が変わっていないか」のチェックです。「アクティブなワークスペースが変わっていないか」はチェックできません。
3. そもそもリソースが違う
クライアントAは workspace_A を操作したいのに、サーバーは default を操作しようとしています。これはどのリソースを操作するかの競合なのです。
4.4 楽観的ロックの本質的な限界
✅ 楽観的ロックが対応できる:
- 単一リソースへの同時書き込み
- 同じファイルを2人が同時に編集
❌ 楽観的ロックが対応できない:
- 複数API呼び出しにまたがる操作の保護
- グローバル状態の保護
楽観的ロックは「変更の検出」はできるが、「操作の排他」はできないのです。
より厳密に言えば、楽観的ロックは「単一リソースの状態遷移」に対してのみ排他性を持ち、「複数リソースや複数操作の整合性」は保証しません。
これは、さっきちょっとふれたデータベースのトランザクション境界の議論と本質的に同じ問題です。
そうした本質を忘れていた私は見事に失敗してしまいました
4.5 補足:API設計を変えれば解決できた?
さて、百戦錬磨のエンジニアなら、ここまで読んで
「API設計を変えれば楽観的ロックでも解決できるのでは?」
と思った方もいるかもしれません。
その通りです!
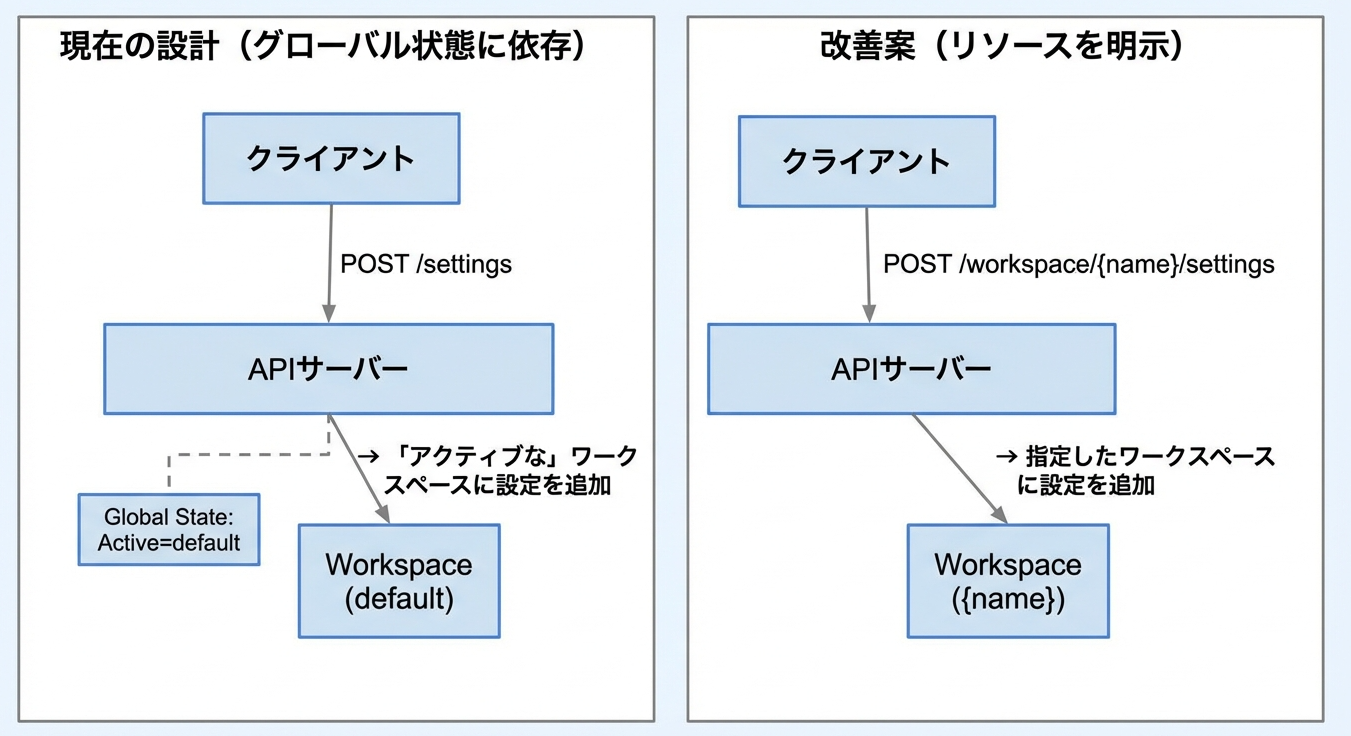
改善案の設計なら、リクエスト自体に操作対象が含まれるため、グローバルな「アクティブ状態」に依存しません。各ワークスペースに対して楽観的ロック(ETag)を適用すれば、競合を検出できます。
では、なぜ悲観的ロックを選んだのでしょうか?
ひとえに私の見識が足りなかった、、んですが、もう少し言い訳をしてみると、
1. 既存APIの後方互換性
多くのクライアントが現在のAPIを使用しており、API変更は全クライアントの修正が必要になる予感があった
2. 「アクティブ状態」パターンは珍しくない
実は、このパターンは様々なツールで採用されており、現行設計がそうなっていた
- Git:
git commitは「現在のブランチ」に対して動作 - シェル: コマンドは「現在のディレクトリ」で実行
- エディタ: 「現在のファイル」に保存
3. 設計変更のコストと時間
問題は「今」発生しており、API再設計には時間がかかりそうだった
教訓をまとめると、以下のようになります。
- 楽観的ロックの限界というより、
「グローバル状態に依存する設計」と楽観的ロックの相性が悪い - 新規設計なら、リソースを明示するRESTfulなAPIを検討すべき
- 既存システムでは、(なんとかするために)悲観的ロックが現実的な解決策になることも多い
5. 悲観的ロックによる解決
5.1 悲観的ロックとは
そこで、既存API設計を壊さず、競合状態の問題を解決するため悲観的ロックを導入することにしました。
「悲観的ロック(Pessimistic Locking)」は、競合は頻繁に起きるという前提に基づく方式です。
基本的な仕組みは以下のとおりです。
- 操作開始前に明示的にロックを取得
- ロック保持中は他のクライアントをブロック(または拒否)
- 操作完了後にロックを解放
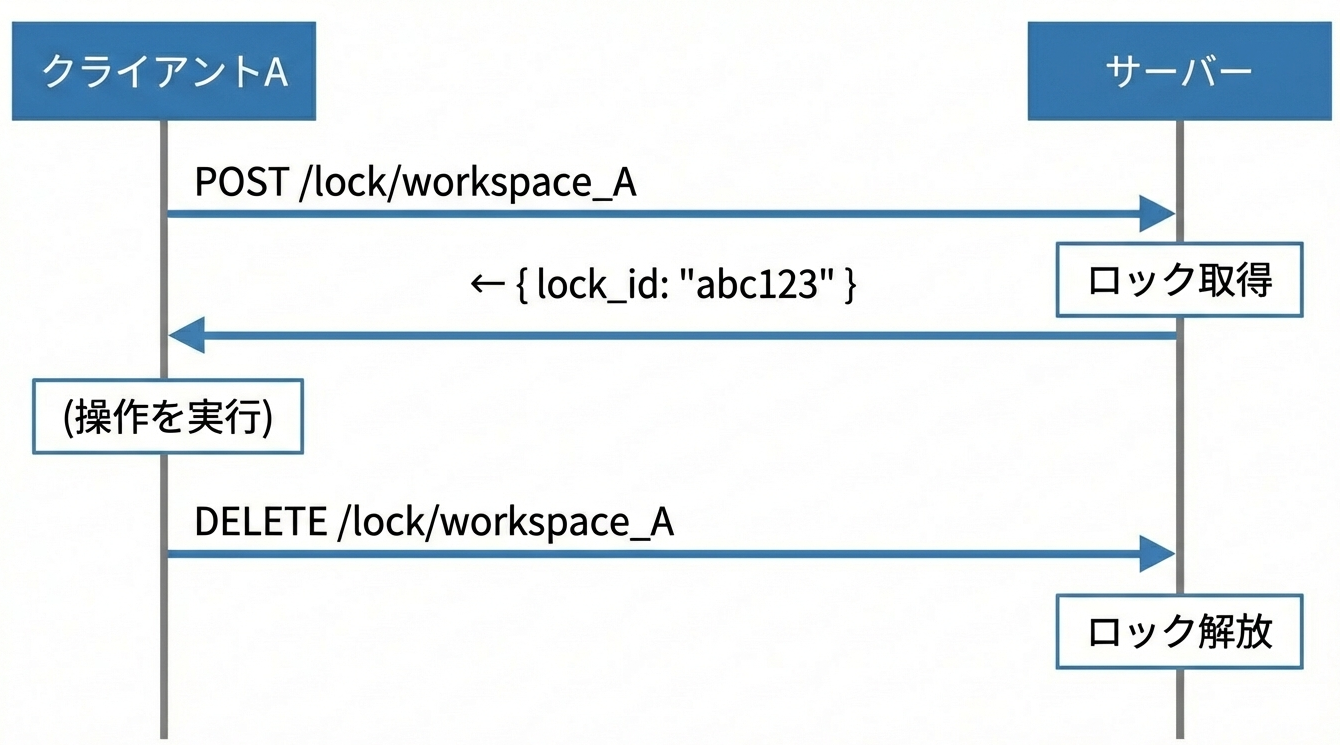
ロック中に別のクライアントがアクセスした場合はこうなります。
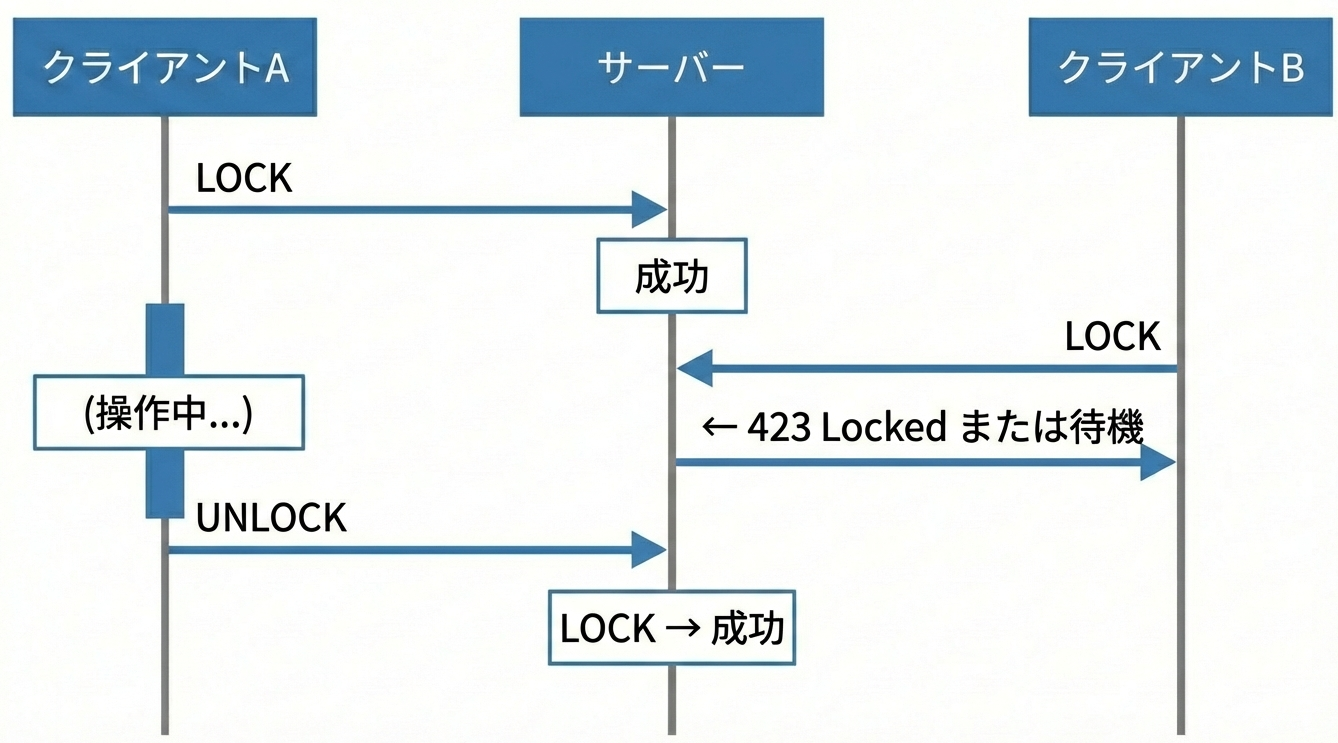
※なお、423 Locked はWebDAV拡張(RFC 4918)で定義されたステータスコードです。一般的なREST APIでは 409 Conflict や 429 Too Many Requests を使うケースもあります。どれを使うかはAPI設計のポリシー次第ですが、「ロックされている」という意味を明確に伝えたい場合は 423 が適切です。
5.2 問題への適用
悲観的ロックを使うと、競合は以下のように解決できます。
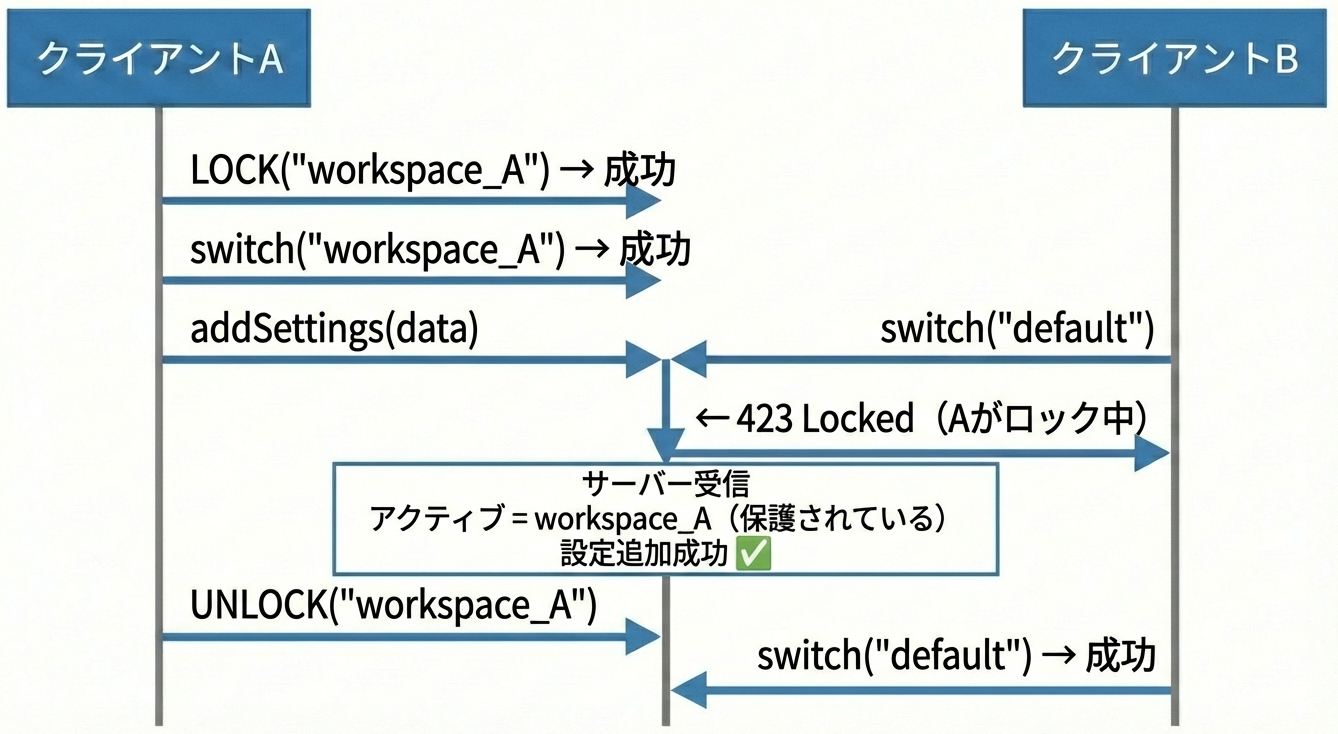
5.3 実装のポイント
悲観的ロックを実装する際の重要なポイントを3つ紹介します。
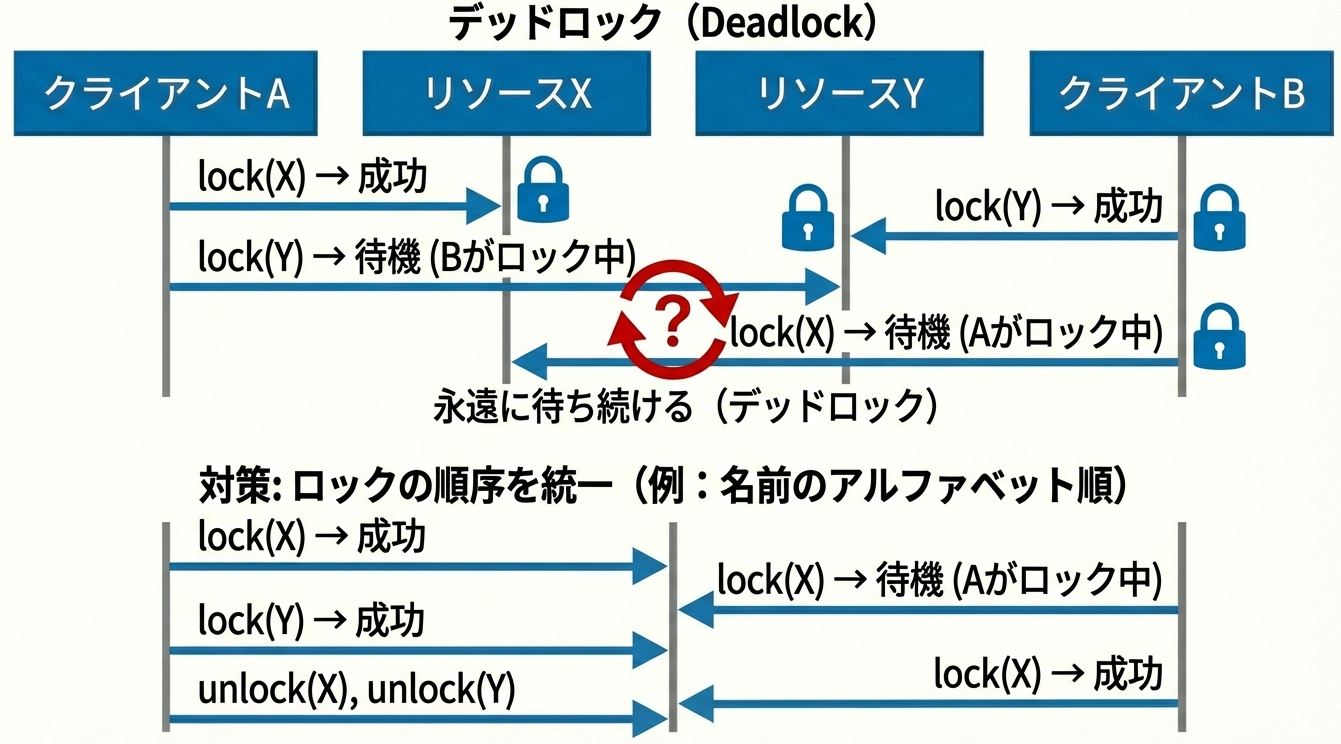
1. デッドロック対策
2. ロック解放忘れ対策
// try-finallyで確実に解放
const lock = await acquireLock(resource);
try {
await doSomething();
} finally {
await releaseLock(lock);
}
3. タイムアウト設定
ロックには有効期限を設定し、クライアントが異常終了した場合でも自動的に解放されるようにします。
6. 実装時のハマりポイント
ここまでいかがでしたでしょうか。
実はロックうんぬんのまえに、いろいろハマったので、後学のため、少しここに残しておきたいと思います。
悲観的ロックを実装・運用する中で、私たちが実際にハマった問題とその対処法を紹介します。
6.1 ロック以前の問題:前提ロジックのバグ
問題:ロック検証は成功しているのに、操作が失敗する
クライアント: LOCK("workspace_A") → 成功
クライアント: switch("workspace_A") → 成功
クライアント: addSettings(data) → 423 Locked ??
なぜ?ロックを持っているはずなのに...
原因:サーバー側でアクティブなワークスペースを取得するロジックにバグがありました。
サーバーの getActiveWorkspaceName() が返す値:
期待: "workspace_A"(クライアントがアクティブ化したもの)
実際: "default"(バグにより常にdefaultを返していた)
→ サーバーは "default" のロックをチェック
→ クライアントは "workspace_A" のロックしか持っていない
→ 423 Locked
教訓:ロック機構自体は正しくても、ロック対象を特定するロジックにバグがあると全てが崩壊します。これは泣けました。
ロック関連のデバッグでは「何のロックをチェックしているか」を必ずログ出力するようにしましょう。
6.2 プロキシ/ゲートウェイの透過性問題
問題:ロック解放のDELETEリクエストがタイムアウトする
クライアント: DELETE /lock/workspace_A
X-Lock-Id: abc123
Body: { "resource": "workspace_A" }
→ リクエストが120秒後にタイムアウト
原因:nginxのリバースプロキシ設定で、DELETEリクエストのボディが(ある条件だと)転送されない設定になっていました。
# nginx.conf(問題のある設定)
location /api/ {
proxy_pass http://backend;
# POST/PUT/PATCHのみボディを転送する設定になっていた
# DELETEにボディがあることを想定していなかった
}
HTTPの仕様上、DELETEリクエストにボディを含めることは許可されています。しかし、
多くのプロキシやフレームワークはDELETEにボディがあることを想定していない
んです。nginxのデフォルト設定では問題ありませんが、カスタム設定を入れている場合は注意が必要です。
教訓:
- ロック操作にはボディが必要になることがある
- プロキシ層での通信を確認する(リクエスト/レスポンスの完全なログ)
- 可能であれば、DELETEのボディではなくクエリパラメータやヘッダーを使う
6.3 ロックの設計を間違える
問題:並列テストが動かないので「複数ロックIDを同時に送れる」ように拡張した
// 誤った解決策
クライアント: X-Lock-Id: lock_A, lock_B, lock_C // 複数ロックを送信
サーバー: いずれかのロックが有効なら許可 // ロックの意味がなくなる!
結果:並列実行できるようになりましたが、ロックの意味が完全に失われました。後で元に戻すことになりました。これはAIコーディングがミスをした例です。目のまえの問題を解決しようとして、無理くりこのとんでも実装をいれてしまいました。
正しい解決策:並列テストを諦め、テストを直列実行するように変更しました。
# テストの実行方法を変更
node --test --test-concurrency=1 tests/*.test.js
教訓:
- AIコーディングはこういう「本質をぶち壊す、目先の対処」をしてしまうので、AIを信じ切ってはいけず、かならずアーキテクチャを理解してる人の目でレビューをしないととんでもないことになります。
- ロック機構を「緩める」方向の変更は、ほぼ間違いです
- 「ロックがあるのに動かない」は、ロックではなく使い方が間違っている
- テストのために本番コードを壊さない
6.4 テスト設計との相性問題
問題:テストを並列実行すると競合エラーが発生
テストA: LOCK("default") → 成功
テストB: LOCK("default") → 待機...
テストC: LOCK("default") → 待機...
テストD: LOCK("default") → タイムアウト!
原因:全てのテストが同じリソース(default)のロックを取ろうとしていました。当然、この手の並列操作は待たされる(待たされることで破綻を回避するので)ので、テストはタイムアウトしてしまいました。
解決策:テストを2種類に分離しました。
tests_for_functions/ ← ロック不要、並列実行OK
- 読み取り専用の機能テスト
- 状態を変更しないテスト
tests_for_policy_edit/ ← ロック必要、直列実行必須
- ワークスペースを作成・変更するテスト
- グローバル状態を変更するテスト
教訓:
- 悲観的ロックを導入したら、テスト戦略も見直す
- 「並列実行できないテスト」は品質が低いわけではない
- グローバル状態を変更するテストは、そもそも並列実行すべきでない
6.5 ロック漏れの検出の難しさ
問題:時々423エラーが出るが、再現性がない
// 問題のあるコード
await acquireLock("resource");
await doSomething(); // ここで例外が発生すると...
await releaseLock("resource"); // 実行されない!
困難な点:
- 例外が発生しないと問題が顕在化しない
- 本番環境でのみ発生する(テストでは通る)
- ログを見ても原因が特定しにくい
対策:
// 1. withLockパターンを強制
async function withLock(resource, operation) {
const lock = await acquireLock(resource);
try {
return await operation();
} finally {
await releaseLock(resource, lock);
}
}
// 2. 直接のacquire/releaseを禁止(コードレビューで検出)
// 3. ロックのタイムアウトを適切に設定(漏れても自動解放)
// 4. ロックの保持時間を監視(異常に長いロックをアラート)
教訓:ロック漏れは必ず起きる前提で設計しましょう。システム全体がとまるという絶望的状況がおこらないようタイムアウトによる自動解放は必須です。完璧なシステムはありませんので。
7. どちらを選ぶべきか:判断基準
7.1 楽観的ロックが適しているケース
| 条件 | 理由 |
|---|---|
| 競合が稀 | リトライのコストが低い |
| 単一リソースへのアクセス | ETagによる検出が有効 |
| 読み取りが多く、書き込みが少ない | ロックのオーバーヘッドを避けられる |
例:ユーザープロフィール編集、記事の更新、設定ファイルの変更
7.2 悲観的ロックが適しているケース
| 条件 | 理由 |
|---|---|
| 競合が頻繁 | リトライのコストが高い |
| 複数操作の原子性が必要 | 一連の操作を保護できる |
| グローバル状態の保護が必要 | リソース選択自体を保護できる |
例:在庫管理、銀行口座の残高更新、複数ステップの業務フロー
7.3 比較表
| 観点 | 楽観的ロック | 悲観的ロック |
|---|---|---|
| 競合検出タイミング | 書き込み時 | ロック取得時 |
| 競合時の動作 | リトライ | 待機/拒否 |
| 実装の複雑さ | 低〜中 | 中〜高 |
| スケーラビリティ | 高 | 中 |
| デッドロック | なし | 可能性あり |
| 保護範囲 | 単一リソース | 複数リソース・複数操作 |
7.4 併用のパターン
実際のシステムでは、両方を併用することも多いです。
[楽観的ロック] [悲観的ロック]
・個別リソースの更新 ・複数リソースにまたがる操作
・低競合の操作 ・高競合の操作
・読み取り中心の処理 ・複数ステップのトランザクション
8. まとめ
8.1 学んだこと
1. 楽観的ロックは万能ではない
「変更の検出」はできますが「操作の排他」はできません。複数API呼び出しにまたがる操作は本質的に保護できないです
2. 問題の本質を理解することが重要
「何と何が競合しているか」を明確にするのが大事ですね。単一リソースの競合か、グローバル状態の競合かを区別することが大切です。
3. 適切な方式を選択する
競合の頻度、操作の性質、システム要件を考慮し、必要に応じて併用しましょう。
4. 悲観的ロックは「古い設計」ではない
競合が設計上必然である場合、悲観的ロックは最も正直な解決策です。「楽観的ロック=モダン、悲観的ロック=レガシー」という図式は誤りです。
8.2 AIコーディングエージェントを使う際の注意
最近はClaude CodeのようなAIコーディングエージェントを活用する機会が増えていますが、並列処理やロックの実装においては注意が必要です。
AIエージェントの傾向
私たちの経験では、AIコーディングエージェントには以下のような傾向があります。
- 並列処理のコーディングに不慣れ:競合状態やデッドロックなど、非決定的な問題の考慮が抜けがち
- 目の前の問題を直接解決しようとする:「このエラーを解消するには?」という質問に対して、局所的な修正を提案しがち
- 設計レベルの視点に気づきにくい:より根本的な解決策があっても、提示されたコードの範囲内で解決しようとする
今回の例で言えば
本記事の問題も、視点を一段上げれば別の解決策がありました。
目の前の問題:
「グローバル状態への競合をどう防ぐか?」
→ 悲観的ロックで排他制御
一段上の視点:
「そもそもグローバル状態に依存しない設計にできないか?」
→ RESTfulにリソースを明示するAPI設計
→ リソース単位の楽観的ロックで対応可能
AIエージェントに「このエラーを直して」と依頼すると、悲観的ロックの実装を提案してくるかもしれません。それ自体は間違いではありませんが、API設計を見直せば楽観的ロックでシンプルに解決できたという選択肢には気づきにくいのです。
AIをコントロールするために
AIコーディングエージェントを効果的に活用するには、人間側がアーキテクチャレベルの視点を持つことが重要です。
- 「この問題を解決して」ではなく「この問題の原因は何か?設計レベルで解決できないか?」と問いかける
- AIの提案をそのまま受け入れず、「もっとシンプルな方法はないか?」と深掘りする
- 並列処理に関わる実装は特に注意深くレビューする
AIは強力なツールですが、設計判断は人間が主導する必要があります。特に並行処理のような複雑な領域では、AIの提案を鵜呑みにせず、一段上の視点からコントロールすることを心がけましょう。
最後に
並行処理の問題は、一度動いたからといって安心できないという厄介な性質があります。開発環境では動いても、本番の高負荷時に問題が顕在化することも珍しくありません。
「楽観的ロックを入れたから大丈夫」と思い込まず、本当に解決したい問題を楽観的ロックで解決できるのかを冷静に分析することが重要です。
そして、並行処理の設計で最も危険なのは、「どこに状態があるかを、設計者自身が曖昧にしてしまうこと」ではないでしょうか。
本記事の例でも、「アクティブなワークスペース」というグローバル状態の存在を明確に認識していれば、最初から適切な対策を選べたかもしれません。
状態がどこにあり、誰がそれを変更でき、どのように保護するか——この問いに明確に答えられることが、並行処理設計の第一歩です。
同様の問題でお悩みの方の参考になれば幸いです!
それでは次回またお会いしましょう!



