
ChatStream🄬でLlama-3-Elyza-JP-8B を動かす

こんにちは、本日は Llama-3-Elyza-JP-8B を使ってみました。
昨日 2024年6月26日に発表(https://prtimes.jp/main/html/rd/p/000000046.000047565.html)された Llama-3-Elyza-JP-8B は 70B 版では「GPT-4」を上回る性能の日本語LLMといわれています。
今回、当社でも Playground 環境に Llama-3-Elyza-JP-8B を搭載して試してみましたのでご紹介します。
70B(700億パラメータ)版は GPT-4 を上回るとのことですので、8B(80億パラメータ)版はGPT-3.5 と比較してみることにいたしました。
(性能比較は https://note.com/elyza/n/n360b6084fdbd の記事に詳しく書いてあります。)
AWQ量子化版を使用してみる
今回は、A4000 というスモールGPUで推論サーバーを構築するため、AWQ により 4bit 量子化バージョンの https://huggingface.co/elyza/Llama-3-ELYZA-JP-8B-AWQ を使用いたしました。
もとが 8B(80億) パラメータ相当ですので、 4bit 量子化すると、モデルサイズは 2B(20億)パラメータ相当となります。
AWQ量子化版は、 推論エンジンとして vLLM での動作が想定されていますので、今回は、 ChatStream の推論エンジンとして vLLM 0.4.2 を選択して推論環境を構築いたしました。
ChatStream.net (playground)デプロイする
ChatStream SDK を使って Llama-3-Elyza-JP-8B 用の A4000 GPU のサーバーノードを1つ作りました。
作業時間は15分程度です。
このサーバーノードを Playground である ChatStream.net のフロントサーバーに登録すれば出来上がりです。
疎通試験も含めてトータル30分程度で使えるようになりました。
このように、激早で構築することができます。
LLM負荷ツールで計測したところ同時20リクエスト/sまではパフォーマンス低下ほぼ無い安定したスループットを達成しています。
おそらく60リクエスト/s 程度までは問題ないレベルだと思われます。
それを超えるリクエストが想定される場合は、 ChatStream のモデル並列化機能を使って簡単に分散させることも可能です。
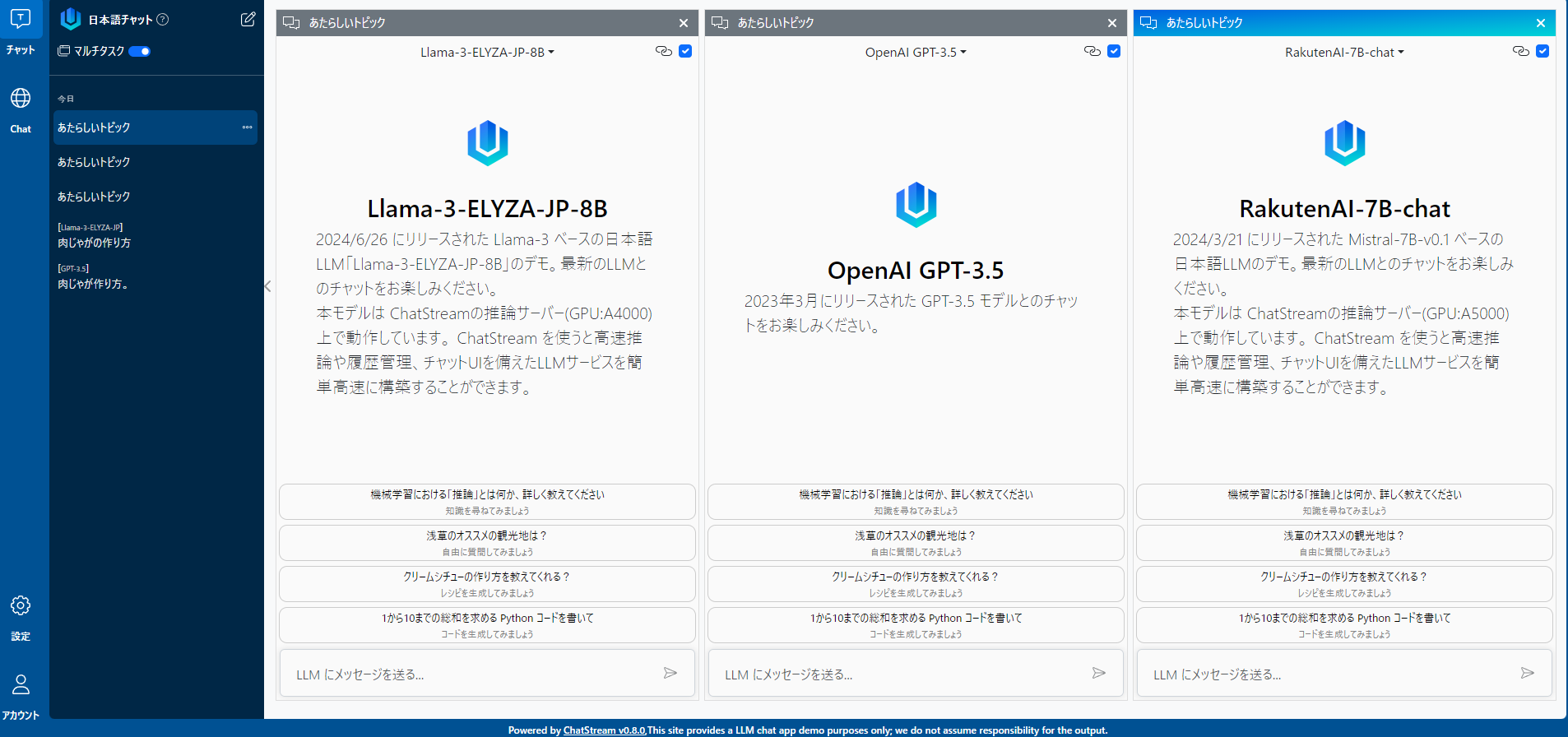
体験デモ
「Llama-3-Elyza-JP-8B」 vs 「GPT-3.5 」
以下URLで、実際に Llama-3-Elyza-JP-8B を体験することができます。
ChatStreamのマルチタスク機能を使って比較用に GPT-3.5 も表示しています。
(マルチタスク機能と入力Syncを使うことで、複数のLLMに同時に質問を投げかけることができます)
「Llama-3-Elyza-JP-8B」 vs 「RakutenAI-7B-chat」 vs 「GPT-3.5」で三つ巴で比較
さらにクエリにmodel_id を追加することで、 RakutenAI-7B-chat も入れて三つ巴で比較するには以下のようにします。
構成
今回作った Llama-3-Elyza-JP-8B 用の構成は以下のようになります。

ChatStream SDK は、サーバー側はDocker 化されているため、
コンテナを動作させるGPUサーバーさえ準備できれば、モデルの準備から公開までトータル30分程度です。モデル並列などスケールアウトも数分~数十分程度で可能ですので、最新のモデルをすぐにお客様に届けることが可能です。
動画
一連の内容を動画にまとめました。
まとめ
最後までお読みいただき、誠にありがとうございます。私たちQualitegは、LLMをはじめとするAI技術、開発キット・SDKの提供、LLMサービス構築、AI新規事業の企画方法に関する研修およびコンサルティングを提供しております。
今回ご紹介したChatStream🄬 SDK を使うと、最新のオープンソースLLMや、最新の商用LLMをつかったチャットボットをはじめとした本格的商用LLMサービスを超短納期で構築することが可能です。
もしご興味をお持ちいただけた場合、また具体的なご要望がございましたら、どうぞお気軽にこちらのお問い合わせフォームまでご連絡くださいませ。
LLMスポットコンサルご好評です
また、LLMサービス開発、市場環境、GPUテクノロジーなどビジネス面・技術面について1時間からカジュアルに利用できるスポットコンサルも実施しておりますのでご活用くださいませ。

(繁忙期、ご相談内容によっては、お受けできない場合がございますので、あらかじめご了承ください)



