
2024年10月度 最新API価格情報


こんにちは、テクノロジー愛好家の皆さん!10月になり、秋の空気が徐々に冷たくなってきましたね。しかし、テクノロジーの世界では熱いニュースが続いています。今回は、2024年10月度の最新API価格情報について詳しくご紹介します。
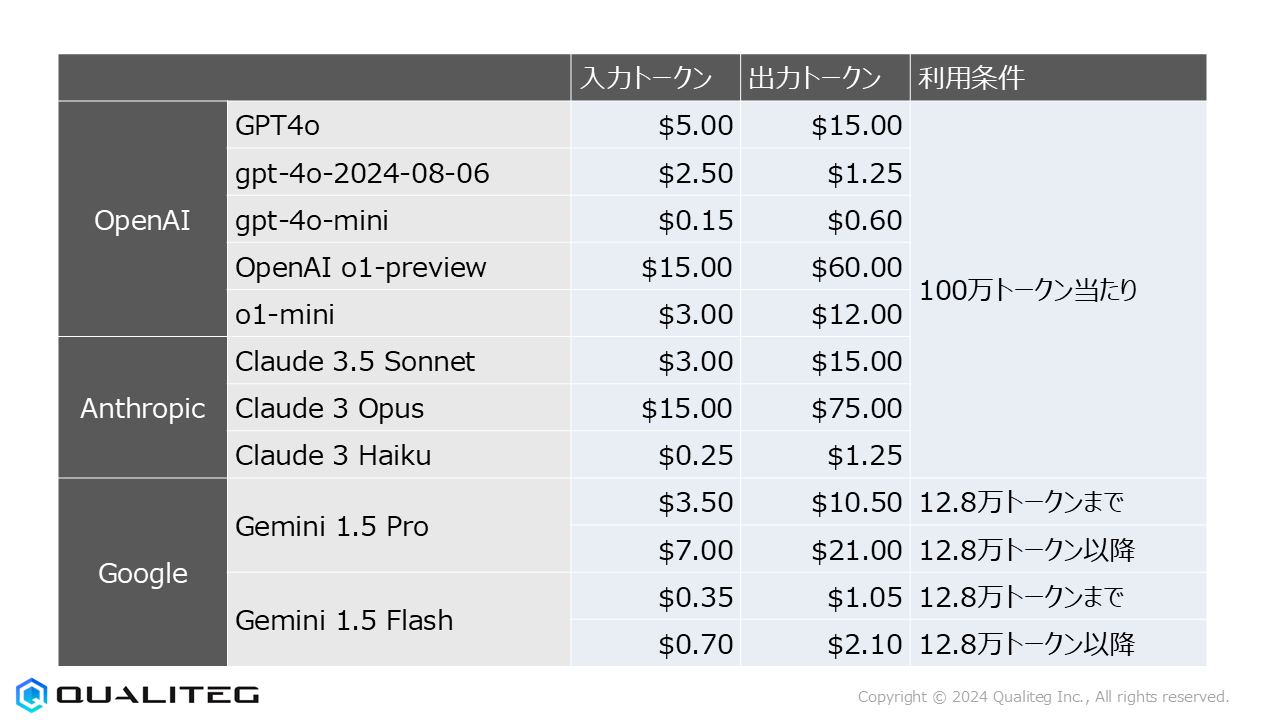
価格比較と選択のポイント
APIプロバイダーを選ぶ際には、単純な価格だけでなく、以下のポイントも考慮することが重要です。
- 使用頻度とスケーラビリティ: 予想されるリクエスト数やデータ量に基づいて、最適なプランを選びましょう。
- サポートとドキュメント: プロバイダーのサポート体制や技術ドキュメントの充実度も重要です。
- セキュリティ: データの安全性を確保するために、セキュリティ機能が充実しているか確認しましょう。
まとめ
2024年10月度の最新API価格情報をお届けしました。OpenAI、Anthropic、GeminiそれぞれのAPIは、利用目的や規模に応じて最適な選択肢が異なります。最新の価格情報を基に、自分のプロジェクトに最適なAPIを選び、効率的な開発を進めましょう。
これからも最新のテクノロジー情報をお届けしていきますので、ぜひご期待ください!



