
コーディングエージェントの現状と未来への展望 【第2回】主要ツール比較と構造的課題


こんにちは!
今回は、コーディングエージェントシリーズ第2回です!
前回の第1回では、2025年12月時点で百花繚乱状態にあるAIコーディングエージェントの全体像を俯瞰しました。

商用サービスからオープンソースまで20以上のツールを紹介し、それらを「CLIベース」「IDE統合型」「AI特化IDE型」「自律型」の4つのカテゴリに分類しました。
また、コーディングエージェントの本質が「LLM+ツール層」のオーケストレーションシステムであること、つまりLLM自体はコード生成と判断のみを担い、実際のファイル保存やコマンド送信はエージェントフレームワーク側が行うという基本アーキテクチャについても解説しました。
さて、今回は、「実際に使い込むと見えてくる課題」にフォーカスします。
正直なところ、どのツールも「すごい!」と感じる瞬間がある一方で、しばらく使っていると「あれ?」と思う場面に遭遇します。
セッションが長くなると急に性能が落ちたり、昨日教えたはずのことを今日は忘れていたり、ベンチマークで高スコアだったはずなのに自社コードではうまくいかなかったり……。
これらは単なる「まだ発展途上だから」では片付けられない、構造的な課題です。
本稿では、まずCLIベースエージェントの代表格であるClaude Code、Codex CLI、Aiderを詳細に比較したうえで、現在のコーディングエージェントが共通して抱える3つの根本的な問題
——コンテキストウィンドウの限界、セッション間の記憶喪失、ベンチマークと実世界のギャップ——
について、具体的な数値とともに掘り下げていきます。
シリーズ構成(再掲)
| 回 | テーマ | 内容 |
|---|---|---|
| 第1回 | 全体像と基礎 | コーディングエージェントの定義、2025年のツール全体像、4つのカテゴリ分類 |
| 第2回 | 主要ツール比較と構造的課題 | Claude Code・Codex CLI・Aider等の詳細比較、コンテキスト限界、記憶喪失、ベンチマーク問題 |
| 第3回 | Amplifierと未来展望 | Microsoft Amplifierの設計思想、旧版vs新版、永続的記憶の実現方法、今後の論点 |
2-1. CLIベースエージェントの詳細比較
第1回で全体像を概観しましたが、ここからはCLIベースのコーディングエージェントについて、より詳細に比較していきます。
2-1-1. Claude Code
AnthropicのClaude Codeは、2025年2月に正式リリースされたターミナルベースのコーディングエージェントです。Claude 3.5 SonnetやOpus 4.1といった高性能モデルを活用し、最大200,000トークンのコンテキストウィンドウを持ちます。SWE-bench Verifiedで72.7%という高いスコアを記録しており、複雑なコードベースの理解と修正において優れた性能を発揮します。
Claude Codeの特徴は「開発者主導」のアプローチにあります。対話的なCLIを通じて開発者と協調しながら作業を進め、破壊的な操作の前には必ず承認を求めます。プロジェクトのコンテキストを保持するためのCLAUDE.mdファイルシステムを採用しており、チーム全体でコーディング規約や設計方針を共有できます。
2-1-2. OpenAI Codex CLI
OpenAIのCodex CLIは、2025年4月にオープンソースとしてリリースされました。Apache 2.0ライセンスで公開されており、コミュニティからの貢献を受け入れています。GPT-5やo3といった最新モデルを活用し、SWE-bench Verifiedで69.1%のスコアを達成しています。
Codex CLIの特筆すべき特徴は、マルチモーダル入力への対応です。スクリーンショットやUI図を入力として受け取り、それに基づいてコードを生成できます。また、サンドボックス環境での安全な動作オプションや、Full Autoモードによる高い自律性も提供しています。
2-1-3. Aider
Aiderは、オープンソースのペアプログラミングツールとして高い評価を得ています。ターミナルベースでありながら、Gitとの深い統合により、変更の追跡とロールバックが容易です。複数のLLMプロバイダー(Anthropic、OpenAI、ローカルモデル等)に対応しており、モデルの切り替えが柔軟に行えます。
Aiderの強みは、自動コミット機能と差分表示にあります。コード変更を自動的にGitコミットとして記録し、変更前後の差分を視覚的に確認できます。また、複数ファイルにまたがる変更を一貫して管理できる点も、実務での利用に適しています。
2-1-4. 比較表
| 項目 | Claude Code | Codex CLI | Aider |
|---|---|---|---|
| 開発元 | Anthropic | OpenAI | OSS (Paul Gauthier) |
| ライセンス | 商用 | Apache 2.0 | Apache 2.0 |
| コンテキスト | 200K tokens | 可変 | モデル依存 |
| SWE-bench | 72.7% | 69.1% | モデル依存 |
| LLM対応 | Claude専用 | OpenAI専用 | 複数対応 |
| Git統合 | あり | あり | ◎ 深い統合 |
| マルチモーダル | 限定的 | ◎ 対応 | モデル依存 |
| 料金 | API従量 | API従量 | API従量 |
2-2. コンテキストウィンドウの限界
さて、ここからは第1回と同様にClaude Codeを例にとって、課題整理をしていきたいとおもいます。ほかのコーディングエージェントでもだいたい似たような課題がありますので、適宜読み替えていただければとおもいます。
2-2-1. 問題の本質
現在のコーディングエージェントは、すべてコンテキストウィンドウという根本的な制約を抱えています。Claude Codeは200,000トークンの大きなウィンドウを持ちますが、複雑なタスクではこれでも足りません。
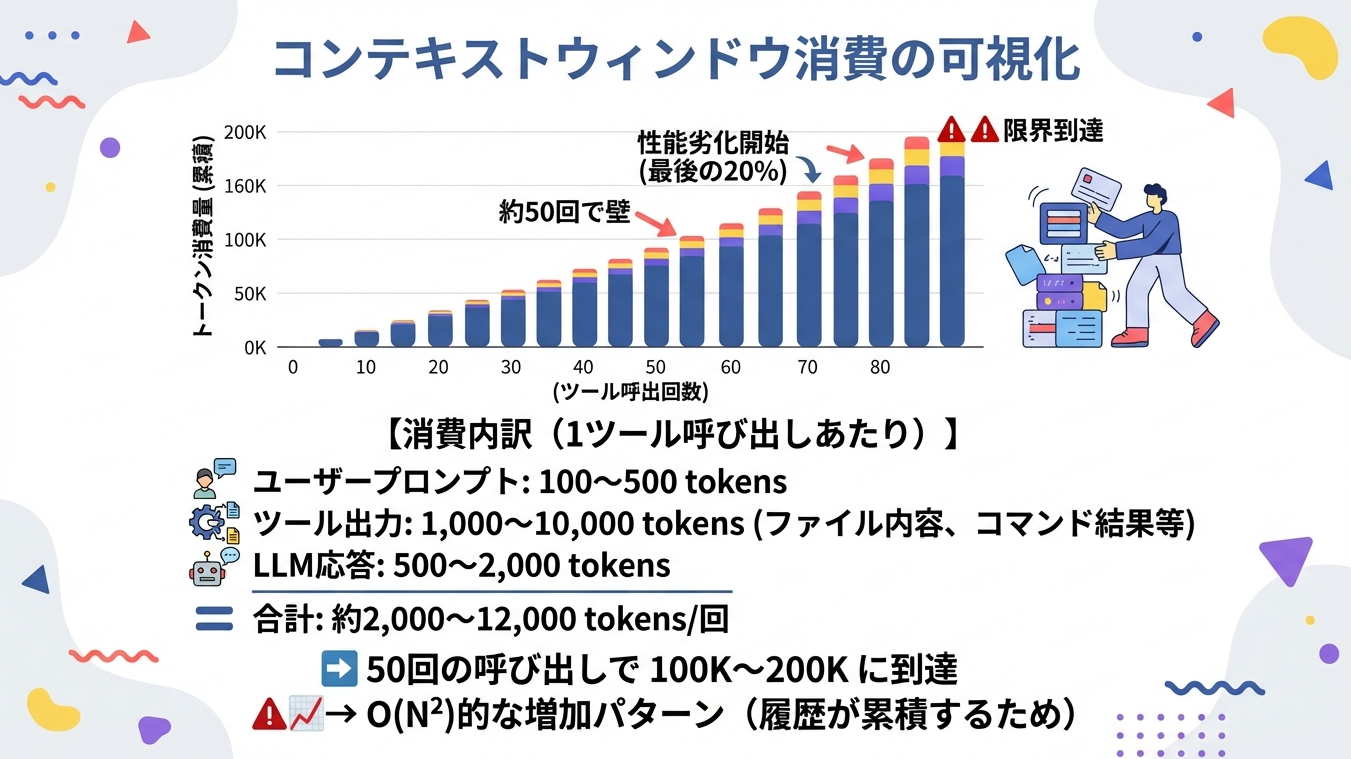
この問題をグラフにしたのが乗ずです。
上部のグラフは、横軸に「ツール呼出回数」、縦軸に「トークン消費量(累積)」をとっています。
見ていただくと分かる通り、消費量は直線的ではなく、回数を重ねるごとに加速度的に増加(右肩上がり)しています。右側のイラストの人物のように、LLMも膨大なデータ量に圧倒されていきます。
2-2-2. 具体的な数値
GitHub Issue #2545で報告されている内容によると、Claude Codeでは約50回のツール使用で200Kトークンの限界に達するケースが多いとされています。
わずか50回程度のやり取りで、累積消費量は100K(10万)トークン付近に達します。ここが最初の大きな「壁」です。各ツール呼び出しで1,000から10,000トークンを消費し、それが累積していくためです。
LLMでは、会話の一貫性を保つために、過去のやり取り(履歴)をすべてコンテキストとして毎回読み込み直します。つまり、新しいやり取りが増えるたびに、「過去の全履歴 + 新しい入力 + 新しい出力」を処理する必要があるため、消費量は雪だるま式(二次関数的)に増えていってしまいます。
つまり、セッションが進むにつれて、過去の会話履歴、ファイル内容、コマンドの出力などが蓄積され、各リクエストのサイズが膨らんでいきます。
その後、コンテキストウィンドウの容量が残り少なくなると(最後の20%)、LLMの性能劣化が始まります。そして80回に達する頃には、トークン上限である200Kトークンの限界に到達し、それ以上の情報を正しく処理できなくなってしまいます。
2-2-3. コンテキスト圧縮の試み
この問題に対処するため、様々なアプローチが試みられています。Anthropicは2025年5月に「コンテキスト管理機能」を発表し、自動要約やスマートな情報選択を導入しました。たとえば、claude-memというコミュニティプラグインは、AIがAI自身の作業を圧縮するというアプローチを採用しています。1,000から10,000トークンのツール出力を約500トークンのセマンティック観察に圧縮し、約50回のツール使用限界を約1,000回(20倍)に拡張することを目指しています。ただし、観察生成に60から90秒の遅延が発生するというトレードオフがあります。
長ったらしくなった履歴を、要約することでトークン数を圧縮しようというこころみですが、要約されたことにより実装上重要なポイントが欠落するがあります。
2-3. セッション間の記憶喪失
2-3-1. 「毎日ゼロから」問題
Claude Codeの最も大きな課題は、セッションをまたいだ記憶の保持ができないことです。
セッションが終わると、次のセッションでは、Claude Codeにとっては
「初見」
になるため、またゼロからいろいろと説明する必要があります。
ここが人間との違いで、毎日昨日のことを全部わすれるエンジニアみたいな感じです。ただし、飲み込みがめっちゃはやい為、毎日ゼロから教えてもなんとかなるというわけではあります。
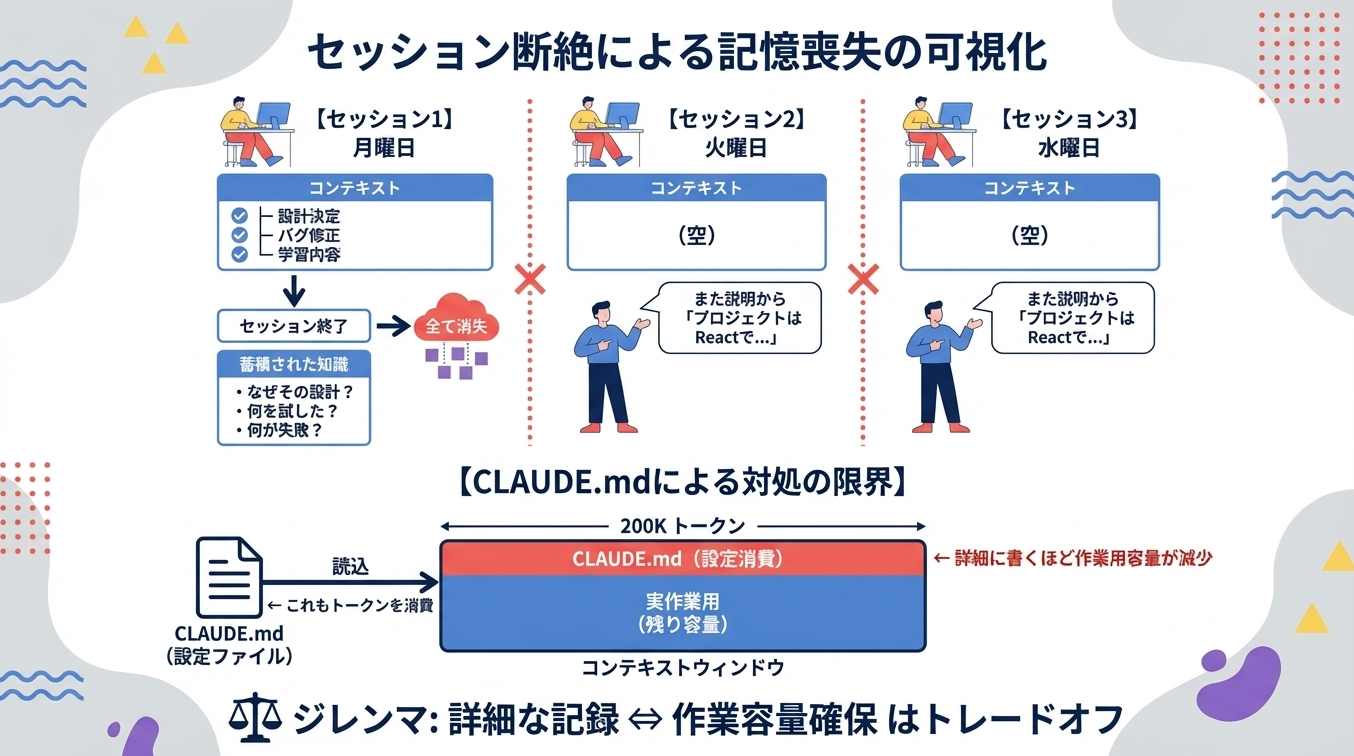
2-3-2. CLAUDE.mdの限界
さて、こうした課題に対処するため、CLAUDE.mdファイルによる永続的な記憶システムは導入されていますが、これはあくまでMarkdownファイルを手動で管理する仕組みであり、会話から自動的に学習するものではありません。また、CLAUDE.mdファイルの内容もコンテキストウィンドウを消費するため、詳細な情報を記録すればするほど、実際の作業に使える容量が減少するというジレンマがあります。
2-4. ベンチマークと実世界のギャップ
2-4-1. SWE-benchの限界
SWE-benchは、コーディングエージェントの性能を測定するための標準的なベンチマークとして広く使用されています。しかし、このベンチマークには重大な限界があります。
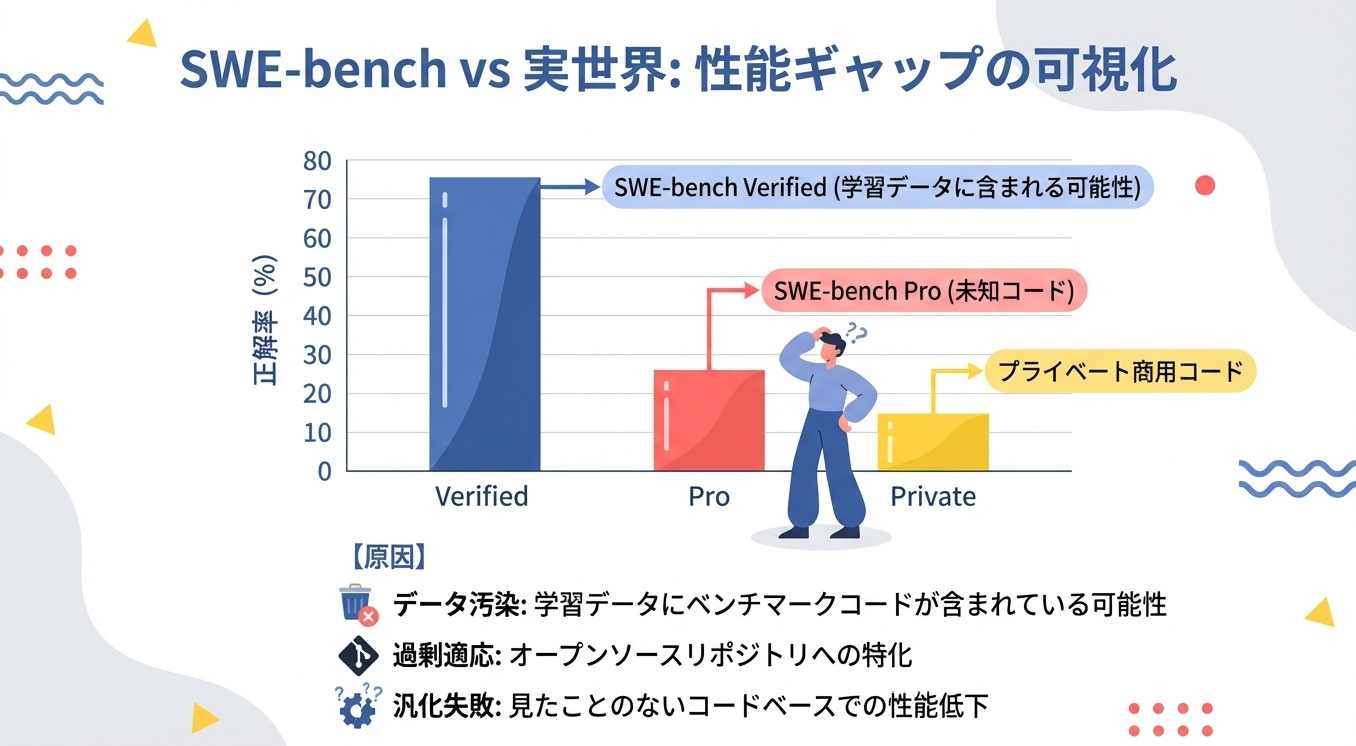
2-4-2. SWE-bench Proの衝撃
Scale AIが2025年に発表したSWE-bench Proでは、従来のSWE-bench Verifiedで70%以上のスコアを達成していたモデルが、23%程度まで性能が低下することが報告されています。この原因として、データ汚染(学習データにベンチマークのコードが含まれている可能性)と、オープンソースリポジトリへの過剰適応が挙げられています。
2-4-3. プライベートコードでの性能低下
特に興味深いのは、プライベートな商用コードベースを使用した評価では、さらに性能が低下する点です。Claude Opus 4.1は22.7%から17.8%へ、GPT-5は23.1%から14.9%へと低下しました。これは、現在のコーディングエージェントが見たことのないコードベースに対しては、期待されるほどの汎化性能を持っていないことがわかります
2-5. Claude Codeの4つの構造的問題(まとめ)
ここまでの分析を踏まえ、Claude Codeが抱える構造的問題を整理しておきます
| 問題 | 内容 | 影響 |
|---|---|---|
| 記憶喪失 | セッションをまたぐと全て忘れる | 毎回ゼロから説明が必要 |
| コンテキスト溢れ | 約50回のツール使用で限界 | 長時間作業が困難 |
| 単一エージェント | 設計もデバッグも全て1人 | 専門性が薄い |
| 単線試行錯誤 | 並行して試せない | 効率が悪い |
これらは現在のアーキテクチャに起因する構造的な問題であり、モデルの性能向上だけでは解決が難しい課題です。
本質的には、もっとセッションあたりの記憶量、つまりコンテクストサイズを20万トークンよりも大きくすることですが、それがAI提供側としてもなかなか簡単では無く、長期的な技術革新が必要だったりします。あと単に技術だけでなく、コンテクストサイズを大きくすると、提供側のリソース増強なども必要となり、コストバランスも見極めないといけないため難易度が高いです。現状、Anthropic社のClaudeは20万トークン。Google社のGemini 3 は 100万トークンです。コンテクストサイズが大きいほど、こうしたコーディングタスクでは有利になりますが、たとえ100万トークンあっても大規模な開発ではまったく足りておらず、コンテクストサイズの増大が見込めない前提で、どんな工夫ができるのか、を考えるのが短期的には重要なテーマとなります。
(それでも2022年に出たChatGPTをはじめ、黎明期のLLMは3万トークンくらいしかコンテクストサイズが無かったことを考えると着実に進化しています。)
第2回まとめ
本稿では、主要なCLIベースエージェントの比較。Claude Codeを例にとって現在のコーディングエージェントが抱える構造的な課題を分析しました。
ポイント
- Claude Code、Codex CLI、Aiderはそれぞれ異なるアプローチを持つ
- コンテキストウィンドウは約50回のツール使用で限界に達する(O(N²)増加)
- セッション間の記憶喪失は、CLAUDE.mdでも根本解決にならない
- SWE-bench Verifiedの70%は、実世界では20%台に低下する
- これらは構造的問題であり、モデル性能向上だけでは解決困難
- コンテクストサイズを増大できるのが良いが短期的には期待できない
次回予告:第3回「Amplifierと未来展望」
最終回となる第3回では、MicrosoftのAmplifierがこれらの課題にどう取り組んでいるかを詳細に解説します。
- Amplifierの設計思想:専門エージェント、Knowledge Graph、マイクロカーネル
- 旧版(Claude Code寄生型)vs 新版(独立フレームワーク型)の違い
- 料金モデルの大きな変化:Maxプラン定額から従量課金へ
- 永続的記憶の3つのアプローチ:ファイルベース、RAG、Knowledge Graph
- 今後の論点:コンテキスト限界後の世界、マルチエージェント協調
特に、旧版では月額$100-200のMaxプランに収まっていた利用が、新版では月額$500-1,200超にもなりうるという料金問題について詳しく解説します。
それでは、次回またお会いしましょう!



