
AIエージェントを"事業に載せる"ために【第3回】AI導入を止めないために、実務で先に設計すべきこと


— AI導入を"事業に載せる"ために、いま設計すべきこと(全3回)
こんにちは!Qualitegコンサルティングチームです。
今回の「AI導入を“事業に載せる”ために、いま設計すべきこと」シリーズも、いよいよ第3回です。
第1回では、実際のAI導入事故を通じて、AIエージェントのリスクが単なる技術不良ではなく、権限や運用設計の不在から生まれることを見てきました。第2回では、事故が起きたときに責任をどこに置くのか、法務・契約・組織の観点から責任分解の難しさを整理しました。
では、AI導入を止めずに前に進めるためには、実務として何を先に設計しておくべきなのでしょうか。
本記事では、品質保証の転換、人間レビューの限界、海外で進む保険市場の変化も踏まえながら、AIエージェント導入前に設計すべき5つの領域と、経営として先に答えるべき3つの問いを整理します。
1. 品質保証の転換:「AIは自信を持って間違える」を前提にする
従来のソフトウェアの品質保証は、少なくとも同じ入力に対して同じ結果を期待しやすく、仕様・テスト・再現性を軸に品質を確認する考え方に立っていました。
ISACAは2025年12月のレビューで、「ハルシネーションは『癖』ではなく安全リスクである。すべての高インパクトなAIシステムは『時に自信を持って間違える』という前提で設計すべきだ」と指摘しています。
複数の研究やレビューで、AIは誤っている場合でも、確信的・権威的に見える表現を取りうることが問題視されています。誤りであっても確信的に見える——この特性が、品質保証を根本から変える必要がある理由です。
以下の図は、従来の品質保証とAI運用時の品質保証の違いを示しています。
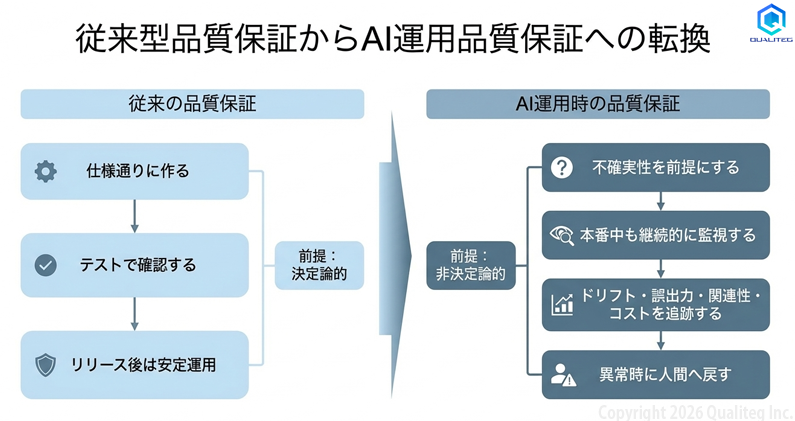
IBMの2026年1月の論考は、この転換を実務に落とすフレームワークとして、精度・ドリフト・コンテキストの関連性・コストといったメトリクスの追跡、推論トレースの即時キャプチャ、プロダクション前のストレステストを推奨しています。
品質保証はモデル評価だけで完結しません。どの出力を監視対象にするか、どの異常を運用上のインシデントとみなすかまで含めて設計する必要があります。
2. 人間レビューの落とし穴:オートメーションバイアス
「AIの出力を人間がチェックすれば安心」——この考え方にも限界があります。

AI & Society誌に2025年7月に掲載されたシステマティックレビュー(Romeo & Conti, 2025)は、35の査読済み研究をレビューした結果、説明可能AI(XAI)や透明性メカニズムは、過度に技術的な説明や逆に単純すぎる説明の場合、特にAIリテラシーの低い実務者において誤った信頼を強化する可能性があると結論づけています。説明を増やしても、判断の正確性が向上するとは限らないという知見は、レビュー体制の設計にとって重要な示唆です。
European Journal of Risk Regulationに2025年7月に掲載された論文は、EU AI ActのArticle 14(4)(b)がオートメーションバイアスに明示的に言及していると分析しています。これはEUのハイリスクAIシステムを前提とした規制上の文脈ですが、日本企業にとっても、人間レビューを単なる形式的承認にしないための設計論として参考になります。法規制が人間レビューの限界を認識し始めているということは、企業側もレビューの設計(頻度、方法、レビュアーの選定とトレーニング、AIの確信度に応じた振り分けルール等)まで踏み込む必要があることを意味しています。
3. 海外で進む保険市場の再編:日本でも運用統制と文書化の重要性は高まっている
保険業界の動きは、AIリスクの性質を端的に映し出しています。
保険業界の動きは、AIリスクが既存の保険商品では整理しにくいリスクとして扱われ始めていることを示しています。ただし、以下で紹介する動きは主に米英など海外市場の事例です。日本でも生成AIリスクを対象にした保険商品は登場していますが、現時点で、既存保険からAIリスクを広く除外する動きが一般化しているとまでは言い切れません。
海外では、保険会社がAI関連の損失を既存保険の対象から切り分けようとする動きと、AI固有のリスクを対象にした新しい保険商品の開発が並行して進んでいます。Harvard Law School Forum on Corporate Governanceに掲載されたHunton Andrews Kurthの分析の分析によれば、保険会社はAI関連の損失が既存の保険でカバーされることを懸念し、AI固有の除外条項の導入を進めています。同事務所の別の記事によると、Berkleyは初の「絶対的(Absolute)」AI除外条項を導入しました。
一方で、Hunton Andrews Kurthの報告によれば、Armilla Insurance ServicesによるAI責任保険は、2025年春にLloyd'sの保険会社による引受商品として報じられました。ハルシネーション、モデル性能の劣化、アルゴリズムの故障といったAI固有のリスクをカバーする内容です。
注目すべきは、少なくとも保険引受や補償範囲の議論において、運用統制や文書化の成熟度が従来以上に重視される方向にあるとの見方が出ている点です。
日本でも、生成AIの利用に伴う知的財産権侵害、情報漏えい、ハルシネーションによる名誉毀損等を対象にした保険商品は登場しています。ただし、現時点では、海外で見られるような広範なAI除外条項やAI責任保険市場の本格的な再編が、日本で一般化しているとまでは言えません。だからこそ日本企業にとって重要なのは、「保険で何とかする」ことではなく、保険やコンプライアンスの検討に耐えうる運用統制・ログ・文書化を先に整えておくことです。
4. ガバナンスの構築:6つの柱
ここまでの品質保証・人間レビュー・保険の動向は、いずれも同じ方向を指しています。AIエージェントの運用における最大のリスクは、技術の不完全さよりも、ガバナンスが未設計であることです。
Mayer Brownが2026年2月に公表した論考をもとに整理すると、AIガバナンスの実務フレームワークは大きく6つの構成要素に分けられます。以下の図はそれを視覚化したものです。
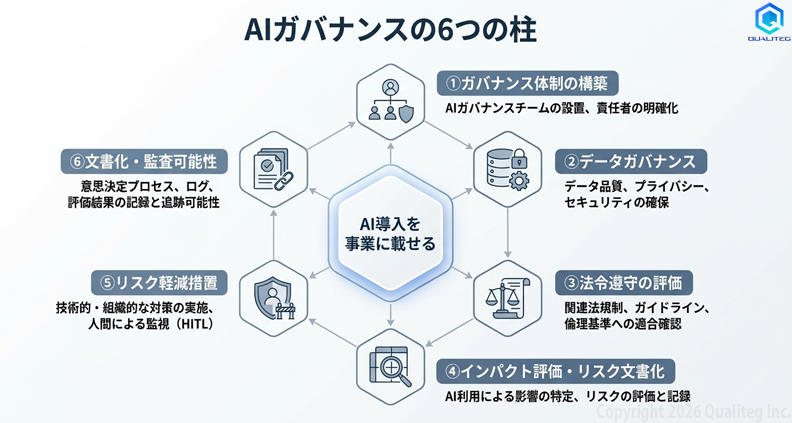
同論考が特に強調しているのは文書化の重要性です。規制当局の調査において監査可能な記録を保持していることは、組織が合理的に行動したことを示す助けになります。逆にこのような文書がなければ、防御力が大きく低下します。
5. 実務で設計すべき5つの領域
経営として先に決めるべきなのは、どの業務に、どの権限まで委譲するのか、誰が例外時のオーナーになるのか、そして失敗コストをどこまで許容するのかです。これらが曖昧なままPoCを進めると、実装の成否以前に、導入判断そのものがぶれ始めます。
また、責任分解は組織論や契約論だけで完結しません。とりわけ、どの入出力を監査対象にするか、どの情報を遮断・マスキングするか、どのモデル利用を許可するか、どの操作を人間承認に戻すか、そして異常時の推論経路をどこまで再構成可能にするかは、プラットフォーム設計と運用設計の問題でもあります。
以下の図は、導入前に設計しておくべき5つの領域を整理したものです。
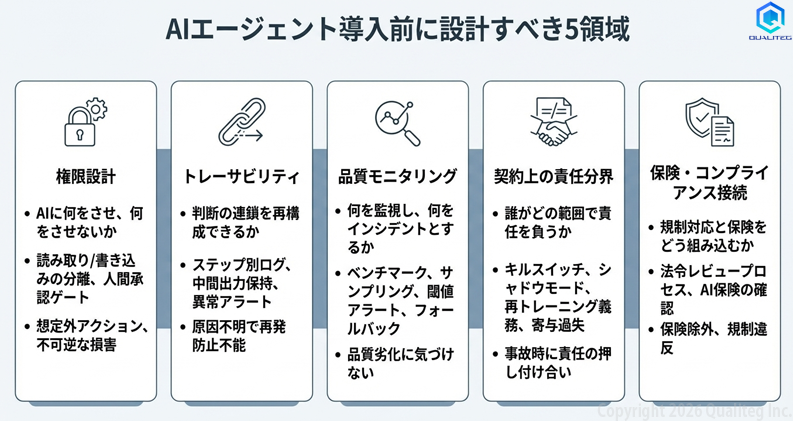
第一は権限設計
エージェントに何をさせ、何をさせないかを明示的に定義することが出発点です。第1回で見たLemkinのケースが示す通り、「やってはいけない期間にやってはいけないことをやる」リスクは、権限設計の不備から生まれます。
第二は、トレーサビリティの確保
第2回で見たように、判断の連鎖を事後的に再構成できなければ、原因分析も責任分解もできません。IBMが推奨する「推論トレースの即時キャプチャ」は、この要件に対応する実務的なアプローチの一つです。
第三は品質モニタリングの設計
ISACAが指摘する通り、「AIは自信を持って間違える」という前提に立ち、定期ベンチマーク、サンプリング検査、閾値アラート、フォールバック手順まで含めた設計が求められます。
第四はステークホルダー間の責任分界の契約化
第2回で整理したキルスイッチ条項・シャドウモード条項・再トレーニングウィンドウ条項・寄与過失の枠組みなど、先進的な契約実務で議論・採用が進みつつあるAI固有の論点を、自社の導入に合わせて契約に組み込みます。
第五は保険・コンプライアンスとの接続
保険市場でAI固有のリスク評価が始まりつつある以上、運用統制や文書化の成熟度が保険の議論に影響し得ます。日本ではAI法やAI事業者ガイドライン、金融分野では金融庁のAIディスカッションペーパー等を踏まえつつ、EU AI Act、米国各州法、業界固有の規制への対応を契約・運用に組み込んでおくことが重要です。
経営として先に答えるべき3つの問い

AIエージェント導入を検討する企業は、少なくとも三つの問いに先に答えておく必要があります。第一に、その業務は誤作動が起きたときにどこまで損失を許容できるのか。第二に、AIに委譲する権限の境界はどこに置くのか。第三に、事故発生時に原因を追跡し、社内外に説明できる状態を作れているのか。
この三つが曖昧なままでは、モデル選定やPoCの精度がどれほど高くても、導入は途中で止まりやすくなります。
設計で終わらず、運用に埋め込むまでが勝負
設計書が存在していても、権限設定が曖昧で、ログが取れておらず、レビュー体制が回らず、現場教育が行われていなければ、ガバナンスは実質的に存在しないのと同じです。
AIエージェント導入の成否は、設計の有無ではなく、設計が運用に埋め込まれているかどうかで決まります。
シリーズのまとめ:AI導入はツール導入ではなく、責任と統制の設計である
全3回を通じて見てきたように、AIエージェントの導入は、モデル性能の評価だけでは完結しません。
第1回では、実際に起きた事故から、AIの問題が技術の不完全さではなく設計の不在にあることを見ました。第2回では、法務・契約・組織の観点から、責任分解がなぜ難しいのか、そしてその難しさをどう契約と運用で補うかを整理しました。第3回では、品質保証の転換、人間レビューの限界、保険市場の再編を踏まえ、実務で先に設計すべき5つの領域と、経営として答えるべき3つの問いを示しました。
AIエージェントの問題は「AIが賢いかどうか」だけではありません。権限設計、監査可能性、契約、運用統制、責任分解をどう設計するかにあります。AIエージェントの導入は、もはや単なるPoCではなく、権限設計・監査可能性・契約・運用統制を含む業務設計そのものです。
技術実装とガバナンス設計を分けずに考えることが、これからのAI導入では重要になるでしょう。
構想から運用定着までQualitegが伴走できる領域
今回は、AI導入を止めないために、実務で先に設計すべきことを整理しました。品質保証の転換、人間レビューの限界、保険市場の変化を踏まえると、AIエージェント導入はもはや単なるPoCではなく、構想・設計・統制・運用まで含めた業務設計だということが見えてきます。
特に重要なのは、権限設計、トレーサビリティ、品質モニタリング、契約上の責任分界、保険・コンプライアンス接続を、ばらばらの論点としてではなく、一つの導入アーキテクチャとしてつなげて考えることです。設計書があるだけでは足りず、それが運用に埋め込まれてはじめて、AIは「試す」段階から「事業に載せる」段階へ進みます。
ここまでのシリーズを通じて見てきた論点は、まさにそのために事前に設計しておくべきものです。
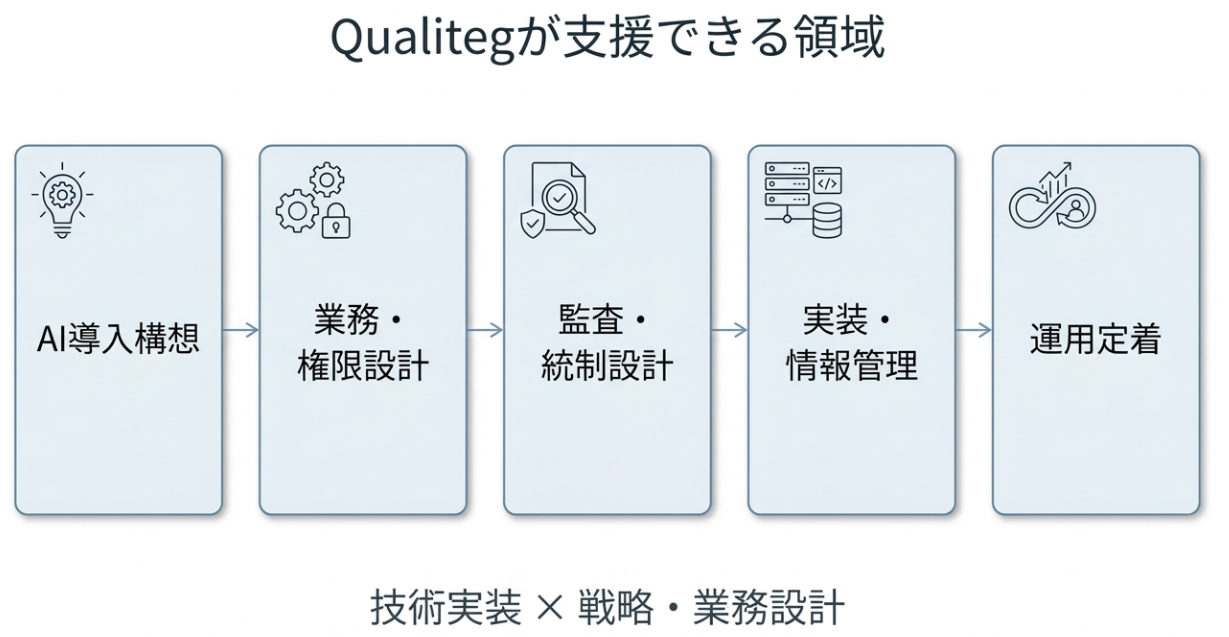
当社では、自社AIプラットフォームの開発・運用で培った実装知見と、AI Transformation・BPR・新規事業開発を含む戦略/業務コンサルティングの両面から、AI導入を「試す」段階で終わらせず、「事業に載せる」ための構想・設計・実装・運用定着まで一気通貫でご支援しています。
AIエージェントの導入では、モデル選定やPoCだけでなく、業務プロセスの再設計、権限設計、監査可能性、情報管理、品質管理、ROIの可視化までを接続して考えることが重要です。Qualitegは、戦略と技術を分断しない体制で、こうした課題に向き合います。
ご関心をお持ちの方は、ぜひお気軽にご相談くださいませ
初期構想の整理、ガバナンス設計、実行基盤の検討、導入後の運用定着まで、課題に応じてご一緒します。



