
Google GenAI SDK のストリーミングでマルチターン画像編集🍌が不安定になる問題と対処法

こんにちは!
Gemini 3 Pro Image (Nano banana Pro)を使ったマルチターン画像編集機能を実装していたところ、動いたり動かなかったりするという厄介な問題に遭遇しました。
本記事では、この問題の現象、原因調査の過程、そして解決策を共有します。
問題の現象
実行環境
Google GenAI SDKライブラリ(pip): google-genai 1.56.0
期待する動作
- ユーザー: 「かわいい子猫の画像を生成して」
- Gemini: 子猫の画像を生成
- ユーザー: 「この子にメガネをかけて」
- Gemini: 同じ子猫にメガネをかけた画像を生成
実際に起きた現象
- ユーザー: 「かわいい子猫の画像を生成して」
- Gemini: 茶色の子猫の画像を生成
- ユーザー: 「この子にメガネをかけて」
- Gemini: メガネをかけた女の子の画像を生成


つまり、前回生成した画像を「覚えていない」状態になっていました。
厄介だったのは「再現性のなさ」
この問題が特に厄介だったのは、動いたり動かなかったりするという点でした。
- 同じコードなのに、タイミングによって成功したり失敗したり、と挙動が変わる
- サーバー再起動したら、タイミングからは長時間動作しなくなる
- 開発環境では動いたが、ステージングでは動かない
同一コードで急に動かなくなると、「いったん再起動しよう」などとりあえずやってしまうと、環境の固定が崩れてしまい、問題の切り分け難しくなり「さっきまで動いてたのに...」という状況が発生し、原因特定に時間がかかりました。
原因調査
thought_signature の仕組み
Gemini 3 Pro Image のマルチターン画像編集は、thought_signature という仕組みに依存しています。
- 画像生成時に、モデルは
thought_signatureを返す - これは生成した画像の情報(構図、色、内容など)を保持する約2MBのデータ
- 次のターンでこれを渡すことで、前回の画像を「覚えている」状態になる
Google の公式ドキュメントによると
If you use the official Google Gen AI SDKs and use the chat feature, thought signatures are handled automatically.
ということで、つまり、SDK のチャット機能を使えば自動管理されるはず...でした。
この thought_signature という仕組みをつかえば、テキストチャットで行う毎回それまでのすべての履歴を送信する、ということを避けることができます。
SDK のチャットセッション
私たちのアプローチでは Google GenAI SDK の client.aio.chats.create() でチャットセッションを作成し、chat.send_message_stream() でメッセージを送信していました。
# チャットセッション作成
chat = client.aio.chats.create(model="gemini-3-pro-preview", config=config)
# メッセージ送信(ストリーミング)
response_stream = await chat.send_message_stream(content_parts)
async for response in response_stream:
# レスポンス処理
...
ドキュメント通りなら、これで thought_signature は自動管理されるはず。しかし実際には動作しませんでした。
GitHub Issue #1791 の発見
調査を進める中で、GitHub で関連する issue を発見しました。
[Bug] ChatSession history fragmentation when using send_message_stream with Thinking (Gemini 3 Pro)
https://github.com/googleapis/python-genai/issues/1791
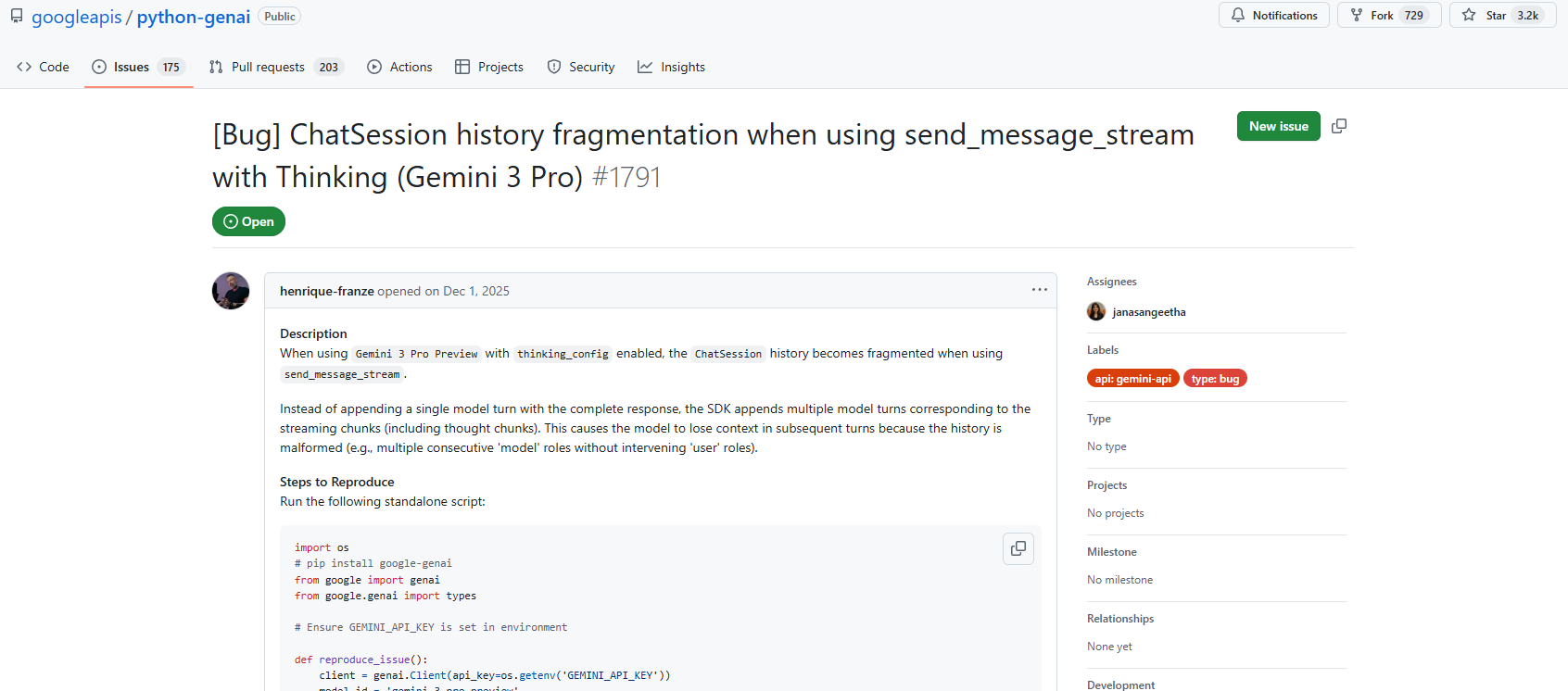
この issue によると
When using Gemini 3 Pro Preview with thinking_config enabled, the ChatSession history becomes fragmented when using send_message_stream. Instead of appending a single model turn with the complete response, the SDK appends multiple model turns corresponding to the streaming chunks.
つまり、send_message_stream() を使うと、チャット履歴が断片化されてしまうというバグが報告されていました。
期待値
[User, Model] # 2エントリ
実際
[User, Model, Model, Model, Model, ...] # 複数のModelエントリ
ストリーミングのチャンクごとに履歴エントリが追加されてしまい、会話構造が壊れるとのこと。
「動いたり動かなかったり」の理由
この issue を読んで、「動いたり動かなかったり」の理由が推測できました。
- 同じサーバーインスタンス内で連続してリクエストすると、セッションがメモリ上に残っているため動くことがある
- サーバー再起動や新しいセッションでは、壊れた履歴から再開しようとして動かない
- タイミングやネットワーク状況によって、履歴の断片化の程度が変わる
これが再現性のない挙動の原因でした。
解決策
非ストリーミング版を使う
issue #1791 を参考に、send_message_stream() の代わりに send_message() を使うことにしました。
# 修正前(ストリーミング)
response_stream = await chat.send_message_stream(content_parts)
async for response in response_stream:
# 処理
...
# 修正後(非ストリーミング)
response = await chat.send_message(content_parts)
# 処理
...
結果
非ストリーミング版に変更したところ、マルチターン画像編集が安定して動作するようになりました。
- 子猫を生成 → 同じ子猫にメガネを追加
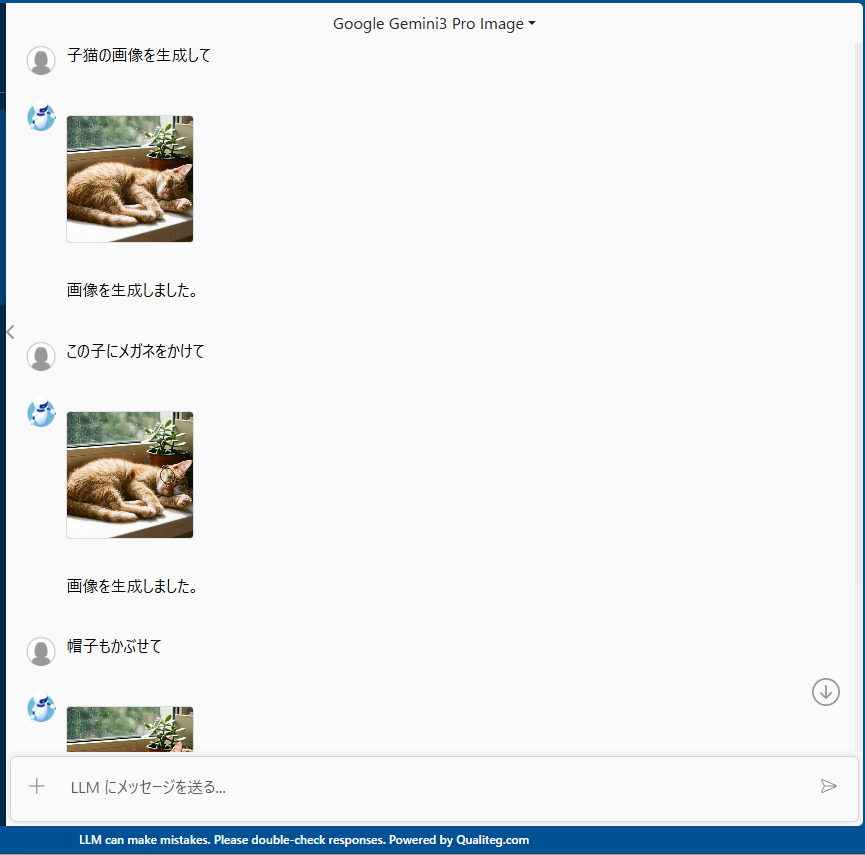

- 何度試しても同じように
- サーバー再起動後も動作
まとめ
問題
Google GenAI SDK の send_message_stream() を使うと、チャット履歴が断片化され、thought_signature が正しく管理されない。
影響
Gemini 3 Pro Image のマルチターン画像編集が不安定になる(動いたり動かなかったりする)。
解決策
send_message_stream() の代わりに send_message() を使う。
副作用
- リアルタイムのストリーミング表示ができなくなる(文章+SVG出力などでの逐次表示に影響)
- 画像生成完了まで結果が返ってこない
- ただし、進捗表示(「処理中です...」など)のサブメッセージを別途実装すれば UX への影響は最小限で済む
今後
- SDK のバグ修正を待つ
- issue #1791 の進捗を監視
- 修正されたらストリーミング版に戻すことを検討
参考リンク
- GitHub Issue #1791 - ChatSession history fragmentation
- Google GenAI Python SDK
- Gemini API Image Generation Documentation
最後に
同一コードで「動いたり動かなかったりする」バグは、原因特定が非常に難しいですね。今回のケースでは、SDK の内部動作を疑うまでに時間がかかりました。
同じ問題で困っている方の参考になれば幸いです。
それでは、次回またお会いしましょう!



