
KVキャッシュのオフロード戦略とGQAの実践的理解


こんにちは!
LLM推論基盤プロビジョニング講座、今回は番外編をお届けします!
第3回「使用モデルの推論時消費メモリ見積もり」では、GPUメモリ消費の二大要素としてモデルのフットプリントとKVキャッシュを紹介し、1トークンあたりのKVキャッシュサイズの計算方法を解説しました。
また第4回「推論エンジンの選定」ではvLLMやDeepSpeedなど各推論エンジンの特性を比較し、第5回では量子化や並列化による最適化戦略を解説してきました。
しかし、実はKVキャッシュにはまだまだ掘り下げるべきトピックがあります。
- KVキャッシュをGPUのVRAMからCPU RAMやディスクにオフロードしたらどうなるのか? どのくらい遅くなるのか?
- HuggingFace TransformersとvLLMでは、KVキャッシュの管理方針がなぜ根本的に異なるのか?
- そもそもKVキャッシュが大きくなる原因であるアテンション構造を変えてしまう GQA(Grouped-Query Attention)とは何か? 第5回で紹介した量子化とは別の軸で、KVキャッシュを劇的に小さくする技術です。
今回はこれらのテーマを、PCIe帯域幅の実数値やモデルサイズごとの具体的な計算を交えながら解説していきます。第3回で学んだKVキャッシュの基礎知識があればスムーズに読み進められるとおもいます。
LLM推論基盤プロビジョニング講座 シリーズ記事一覧
KVキャッシュのおさらい
第3回でも解説しましたが、あらためてKVキャッシュの仕組みをおさらいしておきましょう。
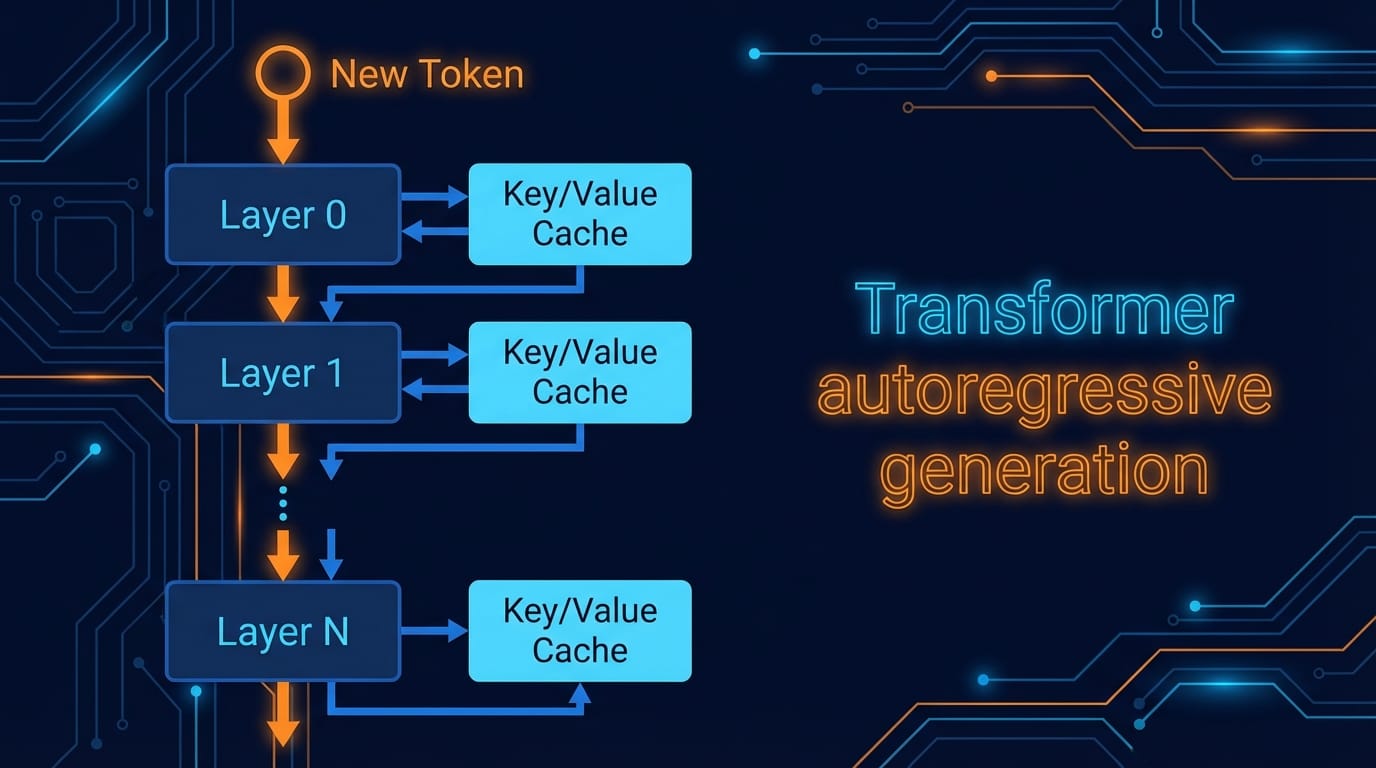
Transformerの自己回帰生成(1トークンずつ生成する推論)では、新しいトークンを1つ生成するたびに、全レイヤーを順番に通す必要があります。
トークン1つ生成するために、全部レイヤーぶんの計算するってことになります。原理的には。
処理の流れは以下のとおりです
- 新しいトークンの埋め込みがLayer 0に入る
- Layer 0で、そのレイヤーの過去のKey・Valueテンソルと合わせてAttentionを計算
- その出力がLayer 1に渡る
- Layer 1で同様にKVを参照してAttention…
- これを最終レイヤーまで繰り返す
- 最終レイヤーの出力から次トークンを予測
ただ、ここで重要なポイントは
過去のトークンに対するKeyとValueの計算結果は毎回同じになるという点
です。
ということで毎トークンで再計算するのは無駄なので、
一度計算したKey・Valueをキャッシュしておきます。
これがKVキャッシュですね
このKVキャッシュですが、
コンテキストが長くなるほど大きくなり、VRAMを圧迫していきます。
KVキャッシュのサイズ感
さて、具体的にどのくらいのメモリを消費するのか、(少し古いモデルですが)Llama 2 7Bを例に計算してみましょう。
モデル構成: 32レイヤー、32ヘッド、ヘッド次元128、FP16
まず、1トークンを処理するときに1つのレイヤーで必要になるKVキャッシュのサイズは以下のとおりです
K: 32ヘッド × 128次元 × 2バイト(FP16) = 8 KB
V: 同じく 8 KB
合計: 約16 KB/トークン/レイヤーつまり、1トークンにつき1レイヤーあたり約16KBのKVキャッシュが蓄積されていきます。
ここで、ユーザーが2048トークン分の文章を入力+生成した状態を考えると
1レイヤーあたり: 16 KB × 2,048トークン = 約32 MB
全32レイヤー合計: 32 MB × 32レイヤー = 約1 GBこの「2048トークン」の部分がコンテキスト長に応じて変わるため、KVキャッシュのサイズはコンテキスト長に比例して大きくなります。
コンテクスト長が8Kトークンなら約4 GB、32Kトークンなら約16 GBがKVキャッシュとして消費されるとうわけです
要するに、ユーザーが大量の文章を入れたり、大量に出力されるような場面では、KVキャッシュもどんどん消費されます
モデルの重み(7B FP16で約14 GB)に加えてこのサイズが必要になりますので、VRAMへの負担は無視できません。
KVキャッシュをCPU RAMやディスクに逃がす
さて、ここで最近話題になるのがコストの高いGPUのRAM(VRAM)の消費量をなるべくおさえたいということで、KVキャッシュをCPU側のメモリやSSDなどのディスクに逃がせないか、といったアイデアです。
結論からいうと、逃すことが可能です。
たとえば、HuggingFace Transformersでは、KVキャッシュをGPUのVRAMからCPU RAMやディスクにオフロードすることができます。
シンプルな方法
KVキャッシュの実体はPyTorchのテンソルなので、.to("cpu") で簡単にCPU RAMに退避できます。
# CPU RAMに退避
cpu_cache = tuple(
tuple(t.to("cpu") for t in layer)
for layer in past_key_values
)
# 使うときにGPUに戻す
gpu_cache = tuple(
tuple(t.to("cuda") for t in layer)
for layer in cpu_cache
)
ディスクに保存する場合は torch.save を使います。
import torch
torch.save(past_key_values, "kv_cache.pt")
past_key_values = torch.load("kv_cache.pt", map_location="cuda")
HuggingFace の OffloadedCache
Transformers 4.36以降では Cache クラスが導入されており、OffloadedCache を使えばレイヤーごとに自動でCPUオフロードしてくれます。
output = model.generate(
input_ids,
cache_implementation="offloaded",
max_new_tokens=100,
)
内部的には、Layer Nを計算中にLayer N+1のKVキャッシュを非同期でプリフェッチすることで、転送のオーバーヘッドを緩和しています。
オフロードのボトルネック:PCIe転送速度
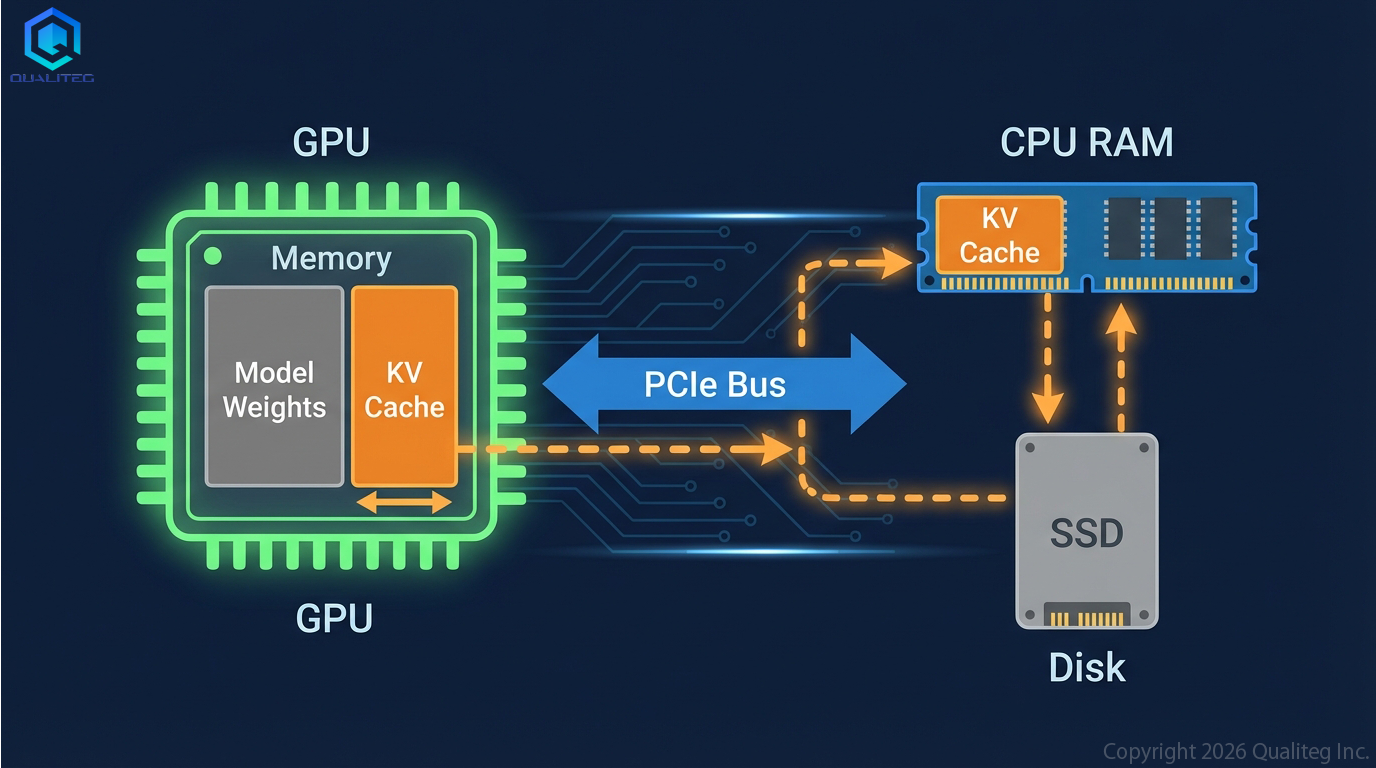
さて、技術的にはKVキャッシュをGPUの中から追い出す=オフロードすることは可能ですが、ここでまず問題になるのがKVキャッシュをGPU外に出す、KVキャッシュを読み取るときの読み書きスピードです。
CPU ↔ GPU間のデータ転送はPCIeバスを介して行われます。
で、そのスピード、つまり、帯域幅はPCIのバージョンと使えるレーン数で決まります。
| PCIe世代 | x16 片方向帯域 | 実効スループット |
|---|---|---|
| PCIe 3.0 | 約16 GB/s | 約12〜13 GB/s |
| PCIe 4.0 | 約32 GB/s | 約25 GB/s |
| PCIe 5.0 | 約64 GB/s | 約50 GB/s |
※PCIのスピードやレーン数についてはこちらの記事(「[PC自作日記1] 現代の自作PCアーキテクチャを理解する」)で詳しく解説しています
実際にどのくらい遅くなるか
ちょっとふるいですが、Llama 2 7B(32レイヤー、FP16)、コンテキスト2048トークンの場合で見積もってみましょう。
先ほど説明したとおり、1トークン生成するごとに全レイヤーを通す必要がありますので、各レイヤーのKVキャッシュをGPUに転送 → 計算 → CPUに戻す、というサイクルが発生します
さきほどの2048トークンぶんの分量ですと、1レイヤーあたり約32 MB × 32レイヤー = 約1 GBの転送量になりますので、PCIe 4.0(実効25 GB/s)なら片道約40msかかります。
| シナリオ | 速度 |
|---|---|
| GPU のみ(VRAM内完結) | 約15 ms/token |
| オフロード(プリフェッチなし) | 約80 ms以上/token |
| オフロード(プリフェッチあり) | 約40〜50 ms/token |
これを、GPUのみで完結する場合とくらべますと、おおよそ 3〜5倍遅くなる 計算です。
PCI転送だけでこれだけ遅くなります。
ただ、mレイヤーは順番に処理されるので、Layer Nの計算中にLayer N+1を非同期転送する「パイプライン化」が可能ですので、計算時間が転送時間を上回る場合は、転送コストを隠蔽できます。
逆に長コンテキストで1レイヤーあたりの転送量が大きくなると、計算時間を超えてしまいボトルネックになります。
コンテキスト長と転送コストの関係
| コンテキスト長 | 1レイヤーKVサイズ | 全レイヤー転送量 | 転送時間(PCIe 4.0) |
|---|---|---|---|
| 2K | 32 MB | 約1 GB | 約40 ms |
| 8K | 128 MB | 約4 GB | 約160 ms |
| 32K | 512 MB | 約16 GB | 約640 ms |
32Kコンテキストでは1トークンの生成に0.6秒以上かかる計算になり、リアルタイム用途ではかなり厳しくなります。
たとえ、PCIを4.0の2倍程度はやくなるPCI5.0にしてもリアルタイム用途では厳しいです。
ディスク(SSD)への保存はさらに遅く、NVMe SSDで3〜7 GB/s、SATA SSDで約0.5 GB/sです。
これでは、リアルタイム推論には向かず、セッション間でキャッシュを再利用する用途に限られるというのが実情です。
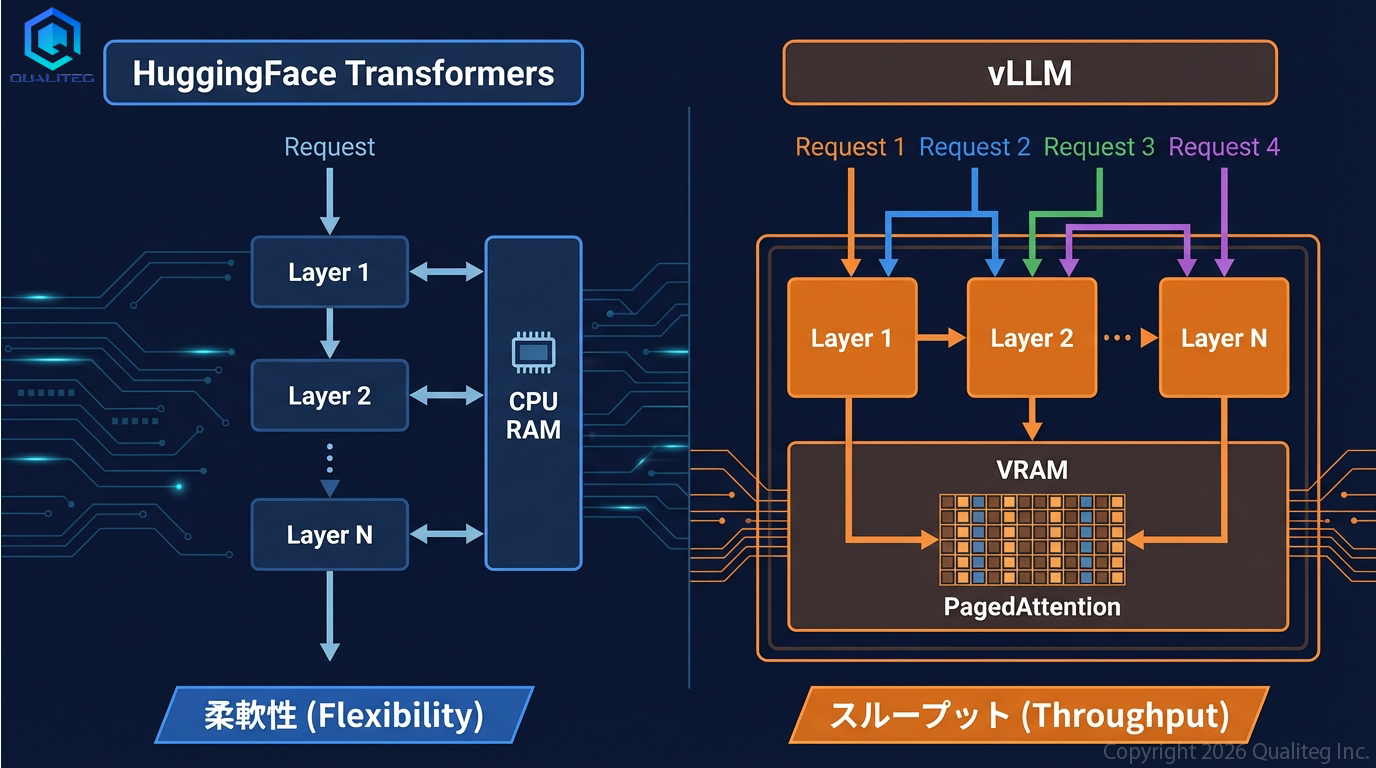
vLLMとの設計思想の違い
第4回でvLLMとHuggingFace Transformers(QCT)の違いを紹介しましたが、ここではKVキャッシュ管理の観点からもう少し掘り下げてみましょう。
HuggingFace Transformersや当社独自のQCTをつかう場合、アーキテクチャがシンプルでKVキャッシュのオフロードが比較的やりやすいのですが、vLLMだと実はKVキャッシュのオフロードの難易度が高くなります。
なぜなら同じKVキャッシュの管理でも、両者はまったく異なるアプローチを取っているからです。
HuggingFace Transformers
- シンプルなforループでレイヤーを1つずつ順番に処理します
- 各レイヤーのKVキャッシュを好きなタイミングで出し入れできます
- 基本的に1リクエストずつのシーケンシャル処理です
- バッチ処理やプロトタイピングに向いています
vLLM
- PagedAttention でKVキャッシュを固定サイズブロックに分割し、VRAM内で効率管理します
- 連続バッチング で複数リクエストを同時処理します
- 基本的に全部VRAMに載る前提で設計されています
- 同時数十リクエストを捌き、スループット数百〜1000+ tokens/secを実現します
vLLMにもKVキャッシュのCPUスワップ機能は存在しますが、推論中に毎トークン転送するのではなく、リクエストがプリエンプト(中断)されたときにそのリクエストのKVブロックをCPUに退避し、再開時に戻すというスケジューリングの一環として使われます。
| HF OffloadedCache | vLLM | |
|---|---|---|
| 目的 | VRAMに入らないKVを退避 | スケジューリングで一時退避 |
| タイミング | 毎トークン、レイヤーごと | リクエスト中断/再開時 |
| レイテンシ影響 | 常に遅くなる | 退避中のリクエストだけ遅延 |
なぜこの違いが生まれるか
HuggingFace Transformersはシンプルな単一リクエストの推論ループだからこそ、各レイヤーで .to("cpu") / .to("cuda") を挟むだけでオフロードが実現できます。一方、vLLMは連続バッチングで複数リクエストを同時処理しているため、毎レイヤーでPCIe転送を待つとパイプライン全体が詰まってしまいます。
これは柔軟性 vs スループットのトレードオフです。
個人で大きいモデルを動かしたいならHFのオフロード、複数ユーザーへのサービングならvLLMでVRAMに収まる構成を選ぶのが定石になります。
さらに、vLLMはモデルアーキテクチャごとの最適化も随所にいれており、スループットを出せるぶん、リアルタイムなKVキャッシュオフロードを手軽にやるのがかなり難しくなっています。
HuggingFace Transformersの同時処理能力
同時処理能力についてもみておきましょう。
HuggingFace Transformers単体では、基本的に1リクエストずつの処理になります。model.generate() は同期的・ブロッキングで、並行処理の仕組みは内蔵されていません。
ただし、FastAPIなどでラップしてマルチスレッドで model.generate() を呼ぶ場合、VRAMに余裕があれば2〜3リクエストが同時に走ることはあります。PyTorchのCUDAは同一GPU上で複数カーネルをある程度並行実行できるためです。
| 方法 | 同時処理数 | 備考 |
|---|---|---|
| 素のHF | 1 | — |
| マルチスレッド + FastAPI | 2〜3 | VRAM次第 |
| 複数GPUで複数プロセス | GPU数分 | メモリ×N |
| HF TGI | 数十〜 | vLLM寄りの設計 |
とはいえ、各リクエストが独立にアテンション計算を行うため、バッチ化の恩恵がなくVRAM効率は良くありません。vLLMとの差はスループットで文字通り桁違いになります。
バッチ処理ならHFが輝く
一方で、オフラインのバッチ処理ならHuggingFace Transformersは良い選択肢です。
- リアルタイム性が不要なので、オフロードの遅延も許容できます
- 1件ずつ順番に処理すればよく、並行処理の複雑さがありません
- コードがシンプルで、前処理・後処理のカスタマイズが自由です
- KVキャッシュをディスクに保存して再利用できます
大量のドキュメント要約、データセットへのラベル付け、夜間バッチ推論など、「寝ている間に終わればいい」用途には十分実用的です。
小さいGPUで大きいモデルを動かす
KVキャッシュのオフロードだけでは不十分で、モデルの重みがVRAMに載らなければそもそも動きません。
GPU VRAMに必要なもの
| 対象 | 7B FP16 | 70B FP16 |
|---|---|---|
| モデルの重み | 約14 GB | 約140 GB |
| KVキャッシュ | 1〜数 GB | 10 GB〜 |
| アクティベーション | 数百 MB | 数 GB |
device_map="auto" による自動分配
HuggingFace Transformersの device_map="auto" を使えば、VRAMに入るレイヤーはGPUに、残りはCPU RAMに、それでも入らなければディスクに自動配置されます。
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-70b-hf",
device_map="auto",
offload_folder="offload",
)
これなら8GBのGPUでも70Bモデルが一応動きます。ただし速度は大幅に低下します。
| 構成 | 70Bの速度感 |
|---|---|
| 全部GPU(A100 80GB × 2) | 約30 tokens/sec |
| GPU + CPUオフロード | 約2〜5 tokens/sec |
| GPU + ディスクオフロード | 約0.1〜0.5 tokens/sec |
量子化との組み合わせ
第5回で解説した量子化と組み合わせるのが最も現実的です。モデルサイズを小さくしたうえでオフロードを使います。
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-70b-hf",
load_in_4bit=True, # 140GB → 約35GB
device_map="auto", # 残りはCPUへ
)
24GB GPU 1枚で完結するモデルサイズの目安(4bit量子化時)
| モデル | 4bitサイズ | 24GBに載る? |
|---|---|---|
| 7B | 約4 GB | 余裕 |
| 13B | 約7 GB | 余裕 |
| 30B | 約17 GB | ギリギリ載る |
| 70B | 約35 GB | 載らない |
70Bの4bit(約35GB)は24GBのVRAMには収まりません。device_map="auto" で半分程度をCPU RAMに配置することで動作はしますが、CPU上のレイヤー処理は遅くなります。GPU 1枚で完結させたいなら、24GB × 2枚(48GB)か、A6000(48GB)やA100(80GB)が必要です。
KVキャッシュのCPUオフロードが活きるシナリオ
ここまで読んで「オフロードは遅くなるだけでは?」と思われたかもしれません。KVキャッシュ「だけ」をCPUに逃がして意味がある場面は、モデルの重みはGPUに載るが、コンテキストが長くてKVキャッシュがVRAMを溢れる場合です。
30Bモデル × 24GB GPUの具体例
30Bモデルを4bit量子化(約17GB)で24GB GPUに載せると、残り約9GBをKVキャッシュに使えます。
GQA対応モデル(KVヘッド8)の場合、1トークンあたりのKVキャッシュサイズは以下のとおりです:
K + V: 64レイヤー × 8ヘッド × 128次元 × 2バイト × 2(KV) = 256 KB/トークン
9GBで約36,000トークン分のKVキャッシュが格納できます。フルアテンション(KVヘッド64)なら約4,500トークンで一杯になります。
| KVヘッド構成 | 9GBで入るトークン数 |
|---|---|
| GQA(KV 8ヘッド) | 約36K |
| MQA(KV 1ヘッド) | 約288K |
| フルアテンション(64ヘッド) | 約4.5K |
この表をみると、同じ9GBでもアテンション方式によって格納できるトークン数が桁違いに異なることがわかりますね。GQAについては次のセクションで詳しく解説します。
有効なユースケース
- 長文書のバッチ分析 — 論文や契約書を丸ごと入力して要約します。バッチ処理なので遅くてもOKです
- RAGで大量チャンクを一度に入力 — 検索で絞らず全部コンテキストに突っ込んで精度を上げたい場合に有効です
- KVキャッシュの再利用 — 同じシステムプロンプト(数千トークン)のプリフィル結果をCPU RAMに保持しておき、リクエストごとにGPUに転送します。長いプロンプトだと、毎回プリフィルを再計算するよりPCIe転送の方が速くなる逆転ポイントがあります
GQA/MQA — KVキャッシュ問題を根本から緩和する
ここまではKVキャッシュの「運用」を見てきましたが、そもそもKVキャッシュが大きくなる原因はAttentionヘッドの数にあります。これを構造的に解決するのがGQA(Grouped-Query Attention)とMQA(Multi-Query Attention)です。
第5回では量子化によってモデルのフットプリントを小さくするアプローチを紹介しましたが、GQAはそれとは別の軸で、アテンション構造そのものを変えてKVキャッシュを劇的に小さくする技術です。
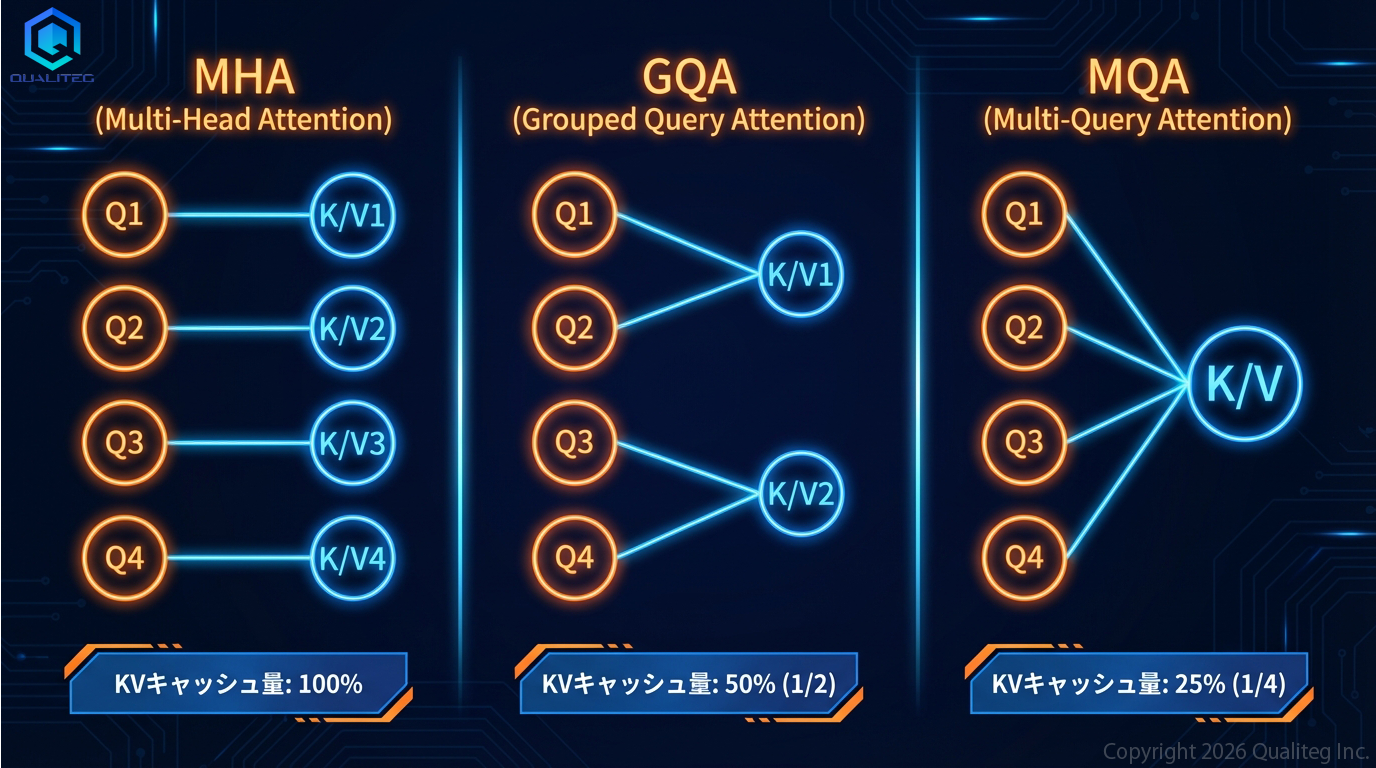
MHA(Multi-Head Attention)— 従来方式
Query、Key、Valueそれぞれが同じ数のヘッドを持ちます。
Q: 64ヘッド
K: 64ヘッド ← 全部独立
V: 64ヘッド ← 全部独立
MQA(Multi-Query Attention)— 極端な共有
2019年にGoogleのNoam Shazeerが論文「Fast Transformer Decoding: One Write-Head is All You Need」で提案しました。KとVを全ヘッドで共有します。
Q: 64ヘッド
K: 1ヘッド ← 全Qヘッドがこの1つを共有
V: 1ヘッド
KVキャッシュが1/64になります。推論速度は大幅に向上しますが、品質がやや落ちるのが課題でした。
GQA(Grouped-Query Attention)— バランスの取れた中間
2023年5月にGoogleのJoshua Ainslieらが論文「GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints」(arXiv:2305.13245)で提案しました。Qヘッドをグループに分けて、グループごとにK, Vを共有します。
Q: 64ヘッド(8グループ × 8ヘッド)
K: 8ヘッド ← 各グループに1つ
V: 8ヘッド
KVキャッシュが1/8になり、品質と効率のバランスが優れています。
視覚的なイメージ
MHA: Q₁→K₁ Q₂→K₂ Q₃→K₃ Q₄→K₄ (各自専用)
GQA: Q₁→K₁ Q₂→K₁ Q₃→K₂ Q₄→K₂ (グループで共有)
MQA: Q₁→K₁ Q₂→K₁ Q₃→K₁ Q₄→K₁ (全員同じ)
GQAの動機
KVキャッシュ削減が主要な動機の一つですが、それだけではありません。自己回帰生成のボトルネックは計算ではなくメモリ帯域です。
毎トークンで巨大なKVキャッシュをVRAMから読み出す必要があります。
つまり、KVキャッシュのサイズ(VRAM容量の問題)と読み出し帯域(速度の問題)の両方を同時に改善することが目的です。推論のメモリ帯域ボトルネックを解消する中で、KVキャッシュ削減も自然についてきたという方が正確でしょう。
GQAの採用タイムライン
GQAの論文発表から実際のモデルへの搭載は非常に速く、わずか2ヶ月で業界の主要モデルに採用されました。以下、各ソースで裏取りしたタイムラインをまとめます。
| 時期 | モデル | 方式 | 備考 |
|---|---|---|---|
| 2019年 | MQA論文(Shazeer) | MQAの提案 | 「Fast Transformer Decoding」 |
| 2022年4月 | PaLM(Google) | MQA | 大規模モデルとしてMQAを初採用 |
| 2023年5月 | GQA論文(Ainslie et al.) | GQAの提案 | arXiv:2305.13245 |
| 2023年5月頃 | Falcon 7B / 40B | MQA / GQA | 7Bは1グループ(MQA相当)、40Bと175Bは8グループ |
| 2023年7月 | Llama 2 | GQA(8グループ) | 70Bのみ。7Bと13BはMHAのまま |
| 2023年10月 | Mistral 7B | GQA(8グループ) | 小型モデルでもGQA採用 |
| 2023年12月 | Mixtral 8x7B | GQA(8グループ) | MoEアーキテクチャでもGQA |
| 2024年4月〜 | Llama 3 全サイズ | GQA(8グループ) | 8B〜405Bまで全サイズでGQA |
| 以降 | ほぼ全ての新規モデル | GQA | Gemma, Qwen, OLMo等も採用 |
注目すべきは、Llama 2の7Bと13BはフルアテンションのMHAのままで、70Bだけ にGQAが採用された点です。小さいモデルではKVキャッシュがそこまで問題にならないという判断でしたが、Llama 3以降はすべてのサイズでGQAが標準になっています。
また、GQA論文の正式な学会発表は2023年12月のEMNLP(シンガポール)でしたが、arXivプレプリントが2023年5月に公開された直後から各社が採用に動いており、それだけ業界全体でKVキャッシュが切実な課題だったことの裏返しと言えます。

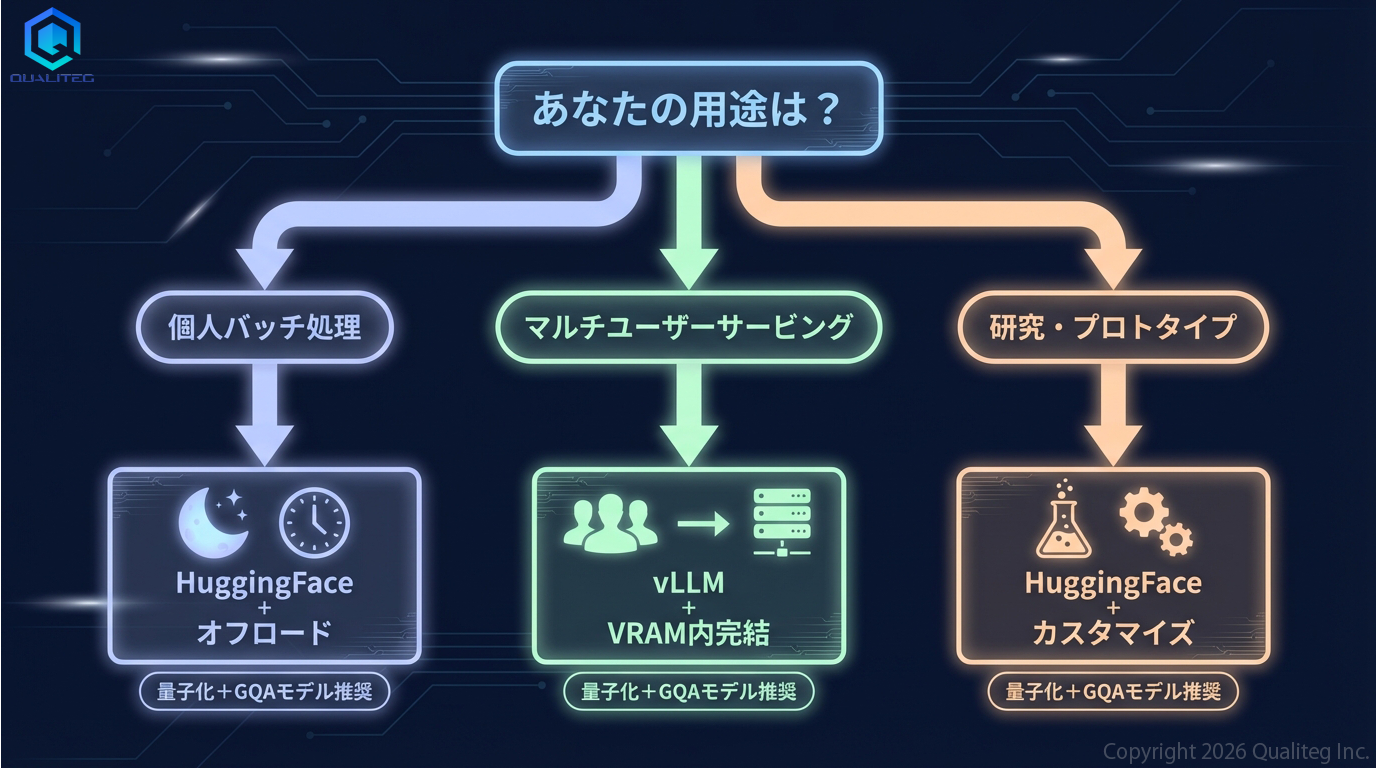
まとめ:実践的な判断フロー
最後に、ここまでの内容を踏まえた実践的な判断フローを整理しておきましょう。
モデル選定時: GQA対応モデルを選びましょう。最近のモデル(Llama 3以降、Mistral等)はほぼ全てGQA対応で、KVキャッシュが大幅に小さくなっています。
VRAMが足りないとき
- まず量子化(4bit/8bit)でモデルサイズを圧縮
- それでも入らなければ
device_map="auto"でCPU RAMにオフロード - KVキャッシュだけ溢れる場合は
cache_implementation="offloaded"を使用 - サービングなら量子化 + vLLMでVRAMに収まる構成を選ぶ
用途で使い分ける
- 個人のバッチ処理 → HuggingFace Transformers + オフロード。遅くても動けばOKです
- 複数ユーザーへのサービング → vLLMまたはTGI。VRAMに収まる構成が前提です
- プロトタイピング・研究 → HuggingFace Transformers。コードがシンプルでカスタマイズしやすいです
KVキャッシュは「見えないVRAM消費者」として軽視されがちですが、コンテキスト長が伸びる昨今のLLMでは、その管理が推論パフォーマンスを左右する重要なファクターになっています。GQAの普及によって状況はかなり改善されましたが、128Kトークンのような超長コンテキストでは依然としてKVキャッシュの扱いが鍵を握ります。
自分の用途とハードウェアに合わせた戦略を選ぶことが、快適なLLM推論への近道です。
それでは、また次の記事でお会いしましょう!
LLM/AIセキュリティのことなら株式会社Qualiteg
私たちQualitegは、LLMの推論・サービング基盤を実際に設計してきたエンジニアリングチームを有しており推論エンジンを単なる箱として扱わず、アテンション計算やKVキャッシュの挙動など深い知見をベースにしたローカルLLM技術のご支援を提供しています。「VRAMに収まる構成はどこか」「vLLMとHugging Face、判断軸は何か」「既存モデルを自社ドメインへ適応させる最短経路は」「オープンLLMと商用LLMの使い分け」「セキュアなローカルLLM構成はどうすればいいか」「ローカルLLMとGPUの選び方」「GPUデータセンターの需要と市場予測」「AI市場予測」などコア技術からAI市場分析まで、お気軽にご相談くださいませ。



