
Python と JavaScript で絵文字の文字数が違う!サロゲートペアが引き起こす位置ずれバグの話

こんにちは!
Qualitegプロダクト開発部です!
PII(個人情報)検出のデモアプリを開発していて、検出したエンティティの位置をハイライト表示する機能を実装していました。
バックエンドは Python(FastAPI)、フロントエンドは JavaScript という構成です。
ある日、テストデータにこんなメール文面を使ったところ、ハイライトの位置が途中から微妙にずれるバグに遭遇しました。
鈴木一郎 様
いつもお世話になっております。
サンプル商事の佐藤でございます。
先日の件、確認が取れましたのでご連絡いたします。
お忙しいところ恐縮ですが、ご確認のほど宜しくお願い致します。
💻 #オンラインでのお打ち合わせ、お気軽に声がけください!
――――――――――――――――――――――――――――――
サンプル商事株式会社
営業部 第一課
山田 太郎 (Yamada Taro)
〒100-0001 東京都千代田区千代田1-1-1 サンプルビル 3F
tel: 03-1234-5678
https://example.com/contact
検出結果をハイライト表示してみると、前半は完璧なのに、途中からずれ始めていました。
何が起きたのか
Python バックエンドは検出結果として各エンティティの start_position と end_position を返します。フロントエンドではその位置を使って text.substring(start, end) でハイライトする部分を切り出します。
前半のハイライトは正確でした:
鈴木一郎→ 正しくハイライトサンプル商事→ 正しくハイライト佐藤→ 正しくハイライト
ところが、メール署名部分に入ると全てのハイライトが1文字分左にずれていました:
- 電話番号
03-1234-5678→03-1234-567とハイライト(先頭にスペース、末尾の8が漏れ) - 人名
山田→\n山とハイライト(改行を含んで田が漏れ) - URL
https://example.com/contact→https://example.com/contacとハイライト(先頭にスペース、末尾のtが漏れ)
途中からずれる?なんでだろう
全部ずれているなら「オフセット計算のバグ」で話は単純です。でも前半は正しくて後半だけずれる。しかもずれ幅は一律で1文字分。
まず考えたのは「途中で位置計算がリセットされるような処理があるのか?」ということ。でもコードを読み返しても、位置はバックエンドから一括で返されていて途中で再計算はしていません。
次に、ずれ始める正確な境界を調べました。正しくハイライトされている最後のエンティティと、ずれ始める最初のエンティティの間に何があるか。
...ご確認のほど宜しくお願い致します。 ← ここまでは正常
💻 #オンラインでの... ← ここを境に
サンプル商事株式会社 ← ここからずれ始める
...💻?この絵文字、もしかして。
ブラウザの開発者ツールで確認してみると:
"💻".length // => 2 ...えっ?
💻 は1文字のはずなのに .length が 2 を返す。ここにバグの原因がありました。
原因: Unicode のコードポイントとコードユニットの違い
Python の文字列
Python 3 の文字列は Unicode コードポイントの列です。
text = "💻オンライン"
print(len(text)) # => 6
print(text[0]) # => "💻"
print(text[1]) # => "オ"
💻 (U+1F4BB) は1つのコードポイントなので、Python では長さ 1 です。
JavaScript の文字列
JavaScript の文字列は UTF-16 コードユニットの列です。
const text = "💻オンライン";
console.log(text.length); // => 7
console.log(text[0]); // => "\uD83D" (サロゲートの片割れ。単体では表示できない)
console.log(text[1]); // => "\uDCBB" (サロゲートの片割れ。単体では表示できない)
console.log(text[2]); // => "オ"
💻 (U+1F4BB) は BMP(基本多言語面, U+0000〜U+FFFF)の外にあるため、JavaScript ではサロゲートペア "\uD83D\uDCBB" として2つのコードユニットで表現されます。よって長さは 2 です。
ずれの仕組み
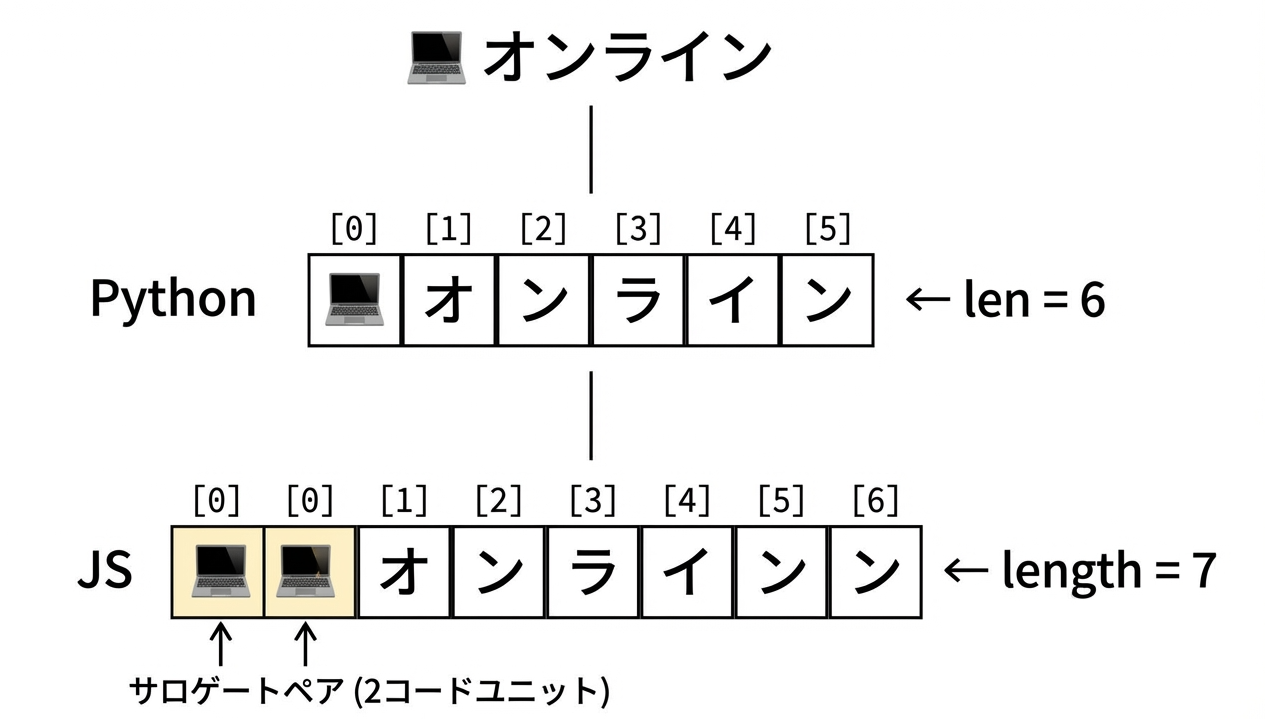
Python が start_position=1(= "オ")を返しても、JavaScript の text[1] はサロゲートの後半 \uDCBB を指します。JavaScript で "オ" にアクセスするには text[2] が必要です。
つまり、BMP外の文字が1つあるごとに、それ以降の全ての位置が+1ずつずれていくのです。
解決策: Array.from() でコードポイント単位にする
JavaScript の Array.from() は文字列をイテレータで走査するため、コードポイント単位で分割されます。
const text = "💻オンライン";
const codePoints = Array.from(text);
console.log(codePoints.length); // => 6 ← Python と一致!
console.log(codePoints[0]); // => "💻"
console.log(codePoints[1]); // => "オ"
これで Python の位置インデックスがそのまま使えます。
修正前(バグあり)
// NG: UTF-16コードユニット単位 → 絵文字でずれる
const entityText = text.substring(start, end);
修正後
// OK: コードポイント単位 → Python と一致
const codePoints = Array.from(text);
const entityText = codePoints.slice(start, end).join("");
実際の修正では text.length も codePoints.length に置き換えています。
他の解決策
スプレッド構文
Array.from() と同様にコードポイント単位で分割できます。
const codePoints = [...text];
console.log(codePoints.length); // => 6
Python 側で UTF-16 オフセットを返す
バックエンド側を修正する方法もあります。Python で UTF-16 でのバイト位置を計算できます。
def to_utf16_offset(text: str, cp_offset: int) -> int:
"""コードポイントオフセットをUTF-16コードユニットオフセットに変換"""
prefix = text[:cp_offset]
# UTF-16エンコード後のバイト数 / 2 = コードユニット数
# utf-16 だとBOM(2バイト)が先頭に付くため、BOMなしの utf-16-le を使用
return len(prefix.encode('utf-16-le')) // 2
text = "💻オンライン"
print(to_utf16_offset(text, 1)) # => 2 ← JS の substring で使える
ただし、API の利用者に「この位置は UTF-16 オフセットです」と明示する必要がある点に注意です。Python のインデックスと一致しなくなるので混乱を招く可能性があります。
補足: コードポイント数 ≠ 見た目の文字数
今回のバグは Array.from() でコードポイント単位に揃えることで解決しました。Python と JavaScript の両方がコードポイント単位で数えるため、ZWJ sequence(合成絵文字)や結合文字がテキストに含まれていても両者の位置は一致します。つまり今回の実装としてはこれで問題ありません。
ただし、コードポイント数と「見た目の文字数」は必ずしも一致しないという点は知っておくと役立ちます。
// ZWJ sequence: 見た目は1文字だがコードポイントは7つ
const family = "👨👩👧👦";
console.log(Array.from(family).length); // => 7 (👨 + ZWJ + 👩 + ZWJ + 👧 + ZWJ + 👦)
// NFD形式の結合文字: 見た目は1文字だがコードポイントは2つ
const ga = "か\u3099"; // "か" + 結合濁点 = "が"
console.log(Array.from(ga).length); // => 2
「見た目の1文字」単位で正確に扱いたい場合(カーソル位置やテキストエディタの実装など)は、書記素クラスタ単位で分割する Intl.Segmenter が使えます。モダンブラウザおよび Node.js 16+ で利用可能です。
const segmenter = new Intl.Segmenter("ja", { granularity: "grapheme" });
const family = "👨👩👧👦";
const segments = [...segmenter.segment(family)];
console.log(segments.length); // => 1 ← 見た目通り!
影響を受ける文字の一覧
BMP外(U+10000以降)の文字は全てサロゲートペアになります。実用上よく遭遇するのは:
| カテゴリ | 例 | コードポイント |
|---|---|---|
| 絵文字 | 💻 😀 🎉 | U+1F4BB, U+1F600, U+1F389 |
| CJK統合漢字拡張B〜 | 𠮷("よし"の異体字) | U+20BB7 |
| 数学記号 | 𝔸 𝕏 | U+1D538, U+1D54F |
| 音楽記号 | 𝄞 | U+1D11E |
逆に、以下はBMP内なのでサロゲートペアにはなりません:
- 日本語の漢字・ひらがな・カタカナ(ほぼ全て)
- 全角英数字(A, 1 など)
- ASCII文字
まとめ
| Python 3 | JavaScript | |
|---|---|---|
| 文字列の内部単位 | Unicode コードポイント | UTF-16 コードユニット |
len("💻") / .length |
1 | 2 |
"💻"[0] |
"💻" |
"\uD83D"(サロゲートの片割れ) |
| BMP外文字の扱い | 1文字 | サロゲートペア(2単位) |
Python と JavaScript の間で文字列の位置情報をやり取りする場合は、BMP外の文字(絵文字等)の存在を常に考慮すべきです。
JavaScript 側では Array.from() や [...str] を使ってコードポイント配列に変換してからインデックスアクセスすることで、Python との一貫性を保てます。さらに ZWJ sequence や結合文字まで考慮する必要がある場合は、Intl.Segmenter の利用を検討してください。
このバグは「テストデータに絵文字を含めていなかった」ことで見逃されていました。異なる言語間で文字列位置を共有する実装では、テストケースに必ず BMP 外の文字(絵文字、CJK拡張漢字など)を含めましょう。
それでは、また次回お会いしましょう!



