
LLM学習の現実:GPU選びから学習コストまで徹底解説

こんにちは!
なぜOpenAIやAnthropicは世界最高水準のLLMを作れるのに、それに肩を並べる日本発のLLMは存在しないのでしょうか?
技術力の差でしょうか。それとも人材の問題でしょうか。
答えはもっとシンプルです。GPUの枚数とお金です。
今日はそんな 「LLMの学習」にフォーカスをあて、そのリアルについて徹底解説いたします!
1. はじめに
「LLMを自分で学習させてみたい」
そう思ったとき、最初にぶつかる壁がGPUの問題です。
どのGPUを何枚使えばいいのか。クラウドで借りるべきか、オンプレで買うべきか。そもそも個人や小規模チームでLLM学習は現実的なのか。
本記事では、こうした疑問に対して、具体的な数字と事例を交えながら答えていきます。
たとえばLLaMA 2の学習にはA100が2,048枚使われました。DeepSeek-V3は約8億円かかりました。では、あなたの手元のGPUでは何ができるのか。そこを明らかにしていきたいと思います。
対象読者は、LLM学習に興味があるエンジニアや研究者です。PyTorchでモデルを書いたことがある程度の知識を前提としますが、分散学習の経験がなくても読み進められるよう心がけました。
2. GPUクラウドとオンプレの選択
クラウドGPUの現実
GPUクラウドサービスを見ると、さまざまなGPUが時間単位で借りられることがわかります。”GPUクラウド”のようなサービスでは、A6000が1時間数十円から、A100 80GBが数百円から利用できます。一見すると手軽に見えますが、自分でGPUを調達してGPUマシンを組む(オンプレ)のとクラウドGPU、どちらを選ぶべきなのでしょうか。
ではコストの観点でみてみるため具体的に計算してみましょう。A100 80GBをクラウドで借りると、安いサービスでも1時間300円程度はかかります。1日8時間、月20日使うとすると、月額4.8万円です。年間で約60万円。一方、A100 80GBの中古価格は180万円程度です。3年使えば元が取れる計算になります。(ただし、そもそこ中古で購入できるほど市場にでまわっていません。それが悩ましいところです)
| 項目 | クラウド(3年間) | オンプレ(3年間) |
|---|---|---|
| 初期費用 | 0円 | 約180万円 |
| 月額費用 | 約4.8万円 | 電気代約1万円 |
| 3年総額 | 約173万円 | 約216万円 |
| 利用時間 | 月160時間 | 無制限 |
毎日8時間程度の利用ならほぼ同等ですが、利用時間が増えるほどオンプレが有利になります。24時間学習を回し続けるようなワークロードでは、オンプレの方が圧倒的に安くなります。
ただし、オンプレには電気代、冷却、設置場所といった隠れたコストがあります。A100は400W、H100は700Wの電力を消費します。8枚のH100を24時間動かせば、電気代だけで月に数万円かかります。
それでも、もしGPUが数枚で済む規模間でLLM学習をやるなら、オンプレを検討する価値は十分ありそうです。
ただ、本当に数枚で済むのか。実際に本格的なLLM学習をゼロから(フルスクラッチ)やるときに、一体どのくらいのGPU枚数が必要かは後述します。
学習と推論、どちらにGPUが使われているのか
世の中のGPU需要について考えてみましょう。
LLM関連でGPUを使っている人たちは、実際には何をしているのでしょうか。
答えは、ほとんどが推論です。
ChatGPTのようなサービスのAPIを叩くとき、裏側ではGPUが推論を行っています。RAG(Retrieval-Augmented Generation)を動かすとき、画像生成AIを使うとき、すべて推論です。
| 用途 | 割合(推定) | 具体例 |
|---|---|---|
| 推論 | 90%以上 | API提供、RAG、チャットボット |
| ファインチューニング | 数% | LoRA、QLoRA |
| フルスクラッチ学習 | 1%未満 | OpenAI、Google、Metaなど |
高性能なLLMのフルスクラッチ学習を行っているのは、OpenAI、Google、Meta、Anthropicといったごく一部の企業だけです。
つまり、「LLM用のGPU」と言っても、ほとんどの人にとっては推論用GPUの話であり、フルスクラッチ学習は極めて特殊なワークロードです。
3. 分散学習の基礎
なぜ分散学習が必要なのか
ここでLLMの学習に話をもどしましょう。
LLMの学習には、1枚のGPUでは到底足りません。理由は二つあります。
一つ目はVRAM(GPUメモリ)の問題です。70億パラメータ(7B)のモデルをFP16で学習する場合、どれだけのVRAMが必要でしょうか。
| 項目 | 必要VRAM |
|---|---|
| モデルの重み(FP16) | 14GB |
| 勾配(gradient) | 14GB |
| オプティマイザ状態(AdamW) | 28GB |
| アクティベーション | 数十GB |
| 合計 | 約100GB |
A100 80GBでも1枚では足りません。7Bという比較的小さなモデルでさえこの状況です。
二つ目は計算時間の問題です。後述するChinchilla則に従えば、7Bモデルの学習には約1400億トークンが必要です。これをA100 1枚で処理すると、数年かかります。現実的な時間で学習を終わらせるには、数百枚から数千枚のGPUを並列で動かす必要があります。
主要な分散学習ツール
LLMに限らず、大きなモデルを学習学習するには複数のGPUが必要になります。
複数のGPUで学習をすることを「分散学習」といいます。これを実現するためのツールはいくつかあるのでご紹介します。
| ツール | 特徴 | 用途 |
|---|---|---|
| PyTorch DDP | PyTorch標準、導入が簡単 | 小〜中規模の分散学習 |
| DeepSpeed ZeRO | メモリ効率に優れる | 大規模モデルの学習 |
| PyTorch FSDP | PyTorchネイティブ | DeepSpeedの代替 |
| Hugging Face Accelerate | 設定が簡単 | 手軽に分散学習を始めたい場合 |
PyTorch DDP(Distributed Data Parallel)は、各GPUが同じモデルのコピーを持ち、異なるデータで学習して、勾配を平均化します。実装が比較的簡単で、小規模な分散学習ではこれで十分です。
しかし、DDPには限界があります。各GPUがモデル全体を持つため、モデルサイズがGPUのVRAMを超えると使えません。
そこで登場するのがDeepSpeedのZeROオプティマイザです。ZeROは、モデルの重み、勾配、オプティマイザの状態を複数のGPUに分散して保持します。

ZeRO-3を使えば、理論上はGPUの枚数に応じてどんな大きなモデルでも学習できるようになります。
NVLinkとは何か、なぜ重要なのか
分散学習でGPUを並列に動かす場合、GPU間でデータをやり取りする必要があります。勾配の同期、アクティベーションの転送など、大量のデータがGPU間を行き来します。このとき、GPU間通信の速度がボトルネックになることがあります。
通常、GPU間の通信はPCIeバスを経由します。たとえば、PCIe 4.0 x16の帯域幅は約32GB/sです。PCIe 5.0でさえ、その2倍の64GB/sです。
しかし、これでは大規模なモデルの学習にはあまりにも遅すぎます。
そこで登場するのがNVLinkです。NVLinkはNVIDIAが開発したGPU間の高速通信規格で、PCIeの10倍の帯域幅を持ちます。
| 接続方式 | 帯域幅 | NVLink比 |
|---|---|---|
| NVLink(H100) | 900 GB/s | 1x |
| NVLink(A100) | 600 GB/s | 0.67x |
| PCIe 5.0 x16 | 64 GB/s | 0.07x |
| 100GbE | 12.5 GB/s | 0.014x |
| 10GbE | 1.25 GB/s | 0.0014x |
ただし、すべてのGPUがNVLinkを使えるわけではありません。ここが重要なポイントです。
| GPU | NVLink対応 | 最大接続数 |
|---|---|---|
| A6000 / RTX 6000 Ada | ○ | 2枚まで |
| A100 / H100 | ○ | 8枚まで(NVSwitch経由) |
| L40S | × | - |
ちなみに、A6000やRTX 6000 Adaは、NVLinkに対応していますが、2枚までしか接続できません。3枚以上のA6000を使う場合、NVLinkは使えず、PCIe経由の通信になります。L40Sは、Ada Lovelaceアーキテクチャのデータセンター向けGPUですが、NVLinkには対応していません。
複数ノードの通信ボトルネック
さらに難しいのが、複数のサーバー(ノード)にまたがる分散学習です。
1台のサーバー内であれば、NVLinkやPCIeで高速に通信できます。しかし、複数のサーバー間の通信は、ネットワーク経由になります。前述の表の通り、10GbEはNVLinkの約700分の1、100GbEでも約70分の1の帯域しかありません。
この帯域幅の差が、分散学習の設計に大きな制約を与えます。
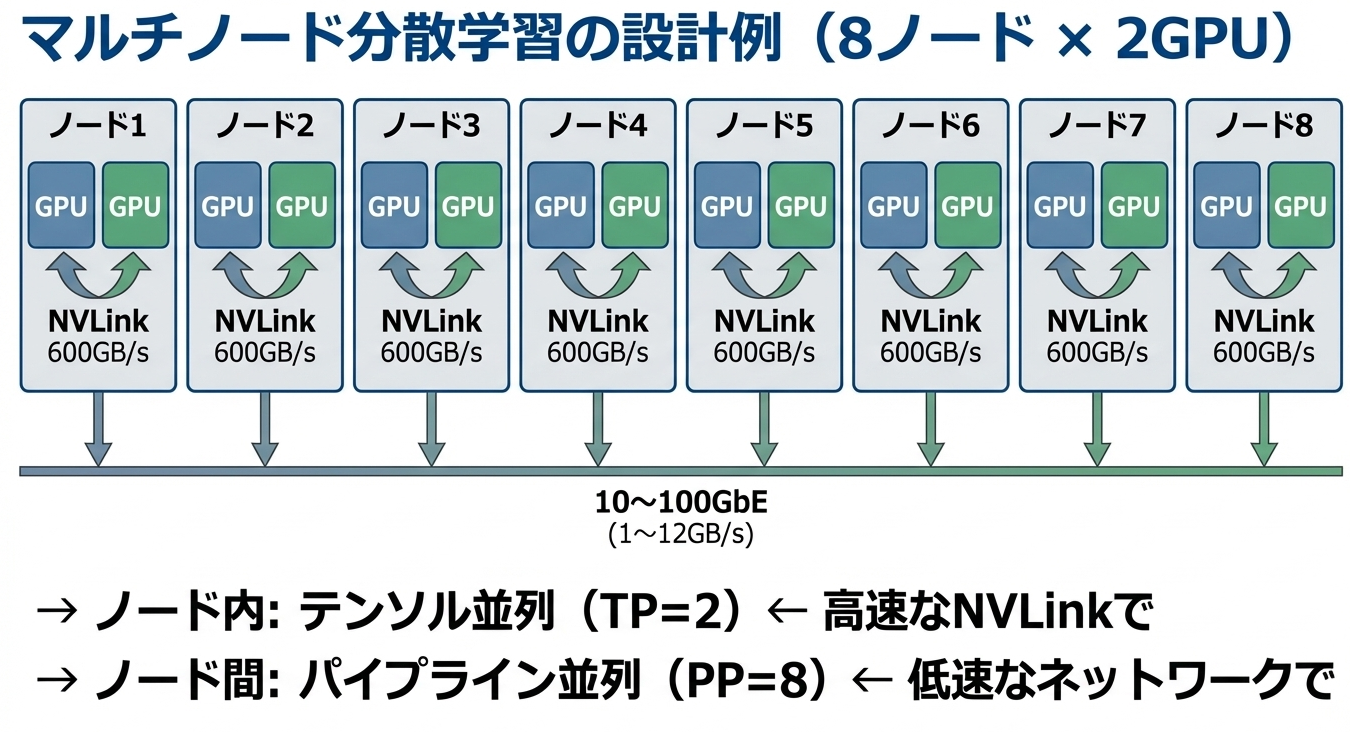
頻繁に通信が必要な処理(テンソル並列など)はノード内のNVLinkで完結させ、通信頻度が低い処理(パイプライン並列など)をノード間で行う、という設計が一般的です。
4. LLM学習に必要な計算量
スケーリング則とは何か(2020年、OpenAI)
LLMの学習に必要な計算量を理解するには、スケーリング則の歴史を知る必要があります。
2020年、OpenAIは「Scaling Laws for Neural Language Models」という論文を発表しました。この論文では、言語モデルの性能(perplexity)がモデルサイズ、データ量、計算量の3つの要素に依存し、これらを増やすと予測可能な形で性能が向上することが示されました。
具体的には、モデルサイズを10倍にすると、性能はべき乗則に従って向上します。データ量を10倍にしても、計算量を10倍にしても、同様に性能が向上します。そして重要なのは、この関係が驚くほど広い範囲で成り立つことです。数千万パラメータから数千億パラメータまで、同じ法則が当てはまります。
当時、この論文は「モデルを大きくすれば性能が上がる」という解釈で受け止められました。OpenAI自身もこの方針に従い、GPT-3(1750億パラメータ)を開発しました。
しかし、この解釈には問題がありました。
Chinchilla則とは何か(2022年、DeepMind)
2022年、DeepMindが「Training Compute-Optimal Large Language Models」という論文を発表しました。通称Chinchilla論文です。
この論文は、OpenAIのスケーリング則の解釈を大きく修正しました。
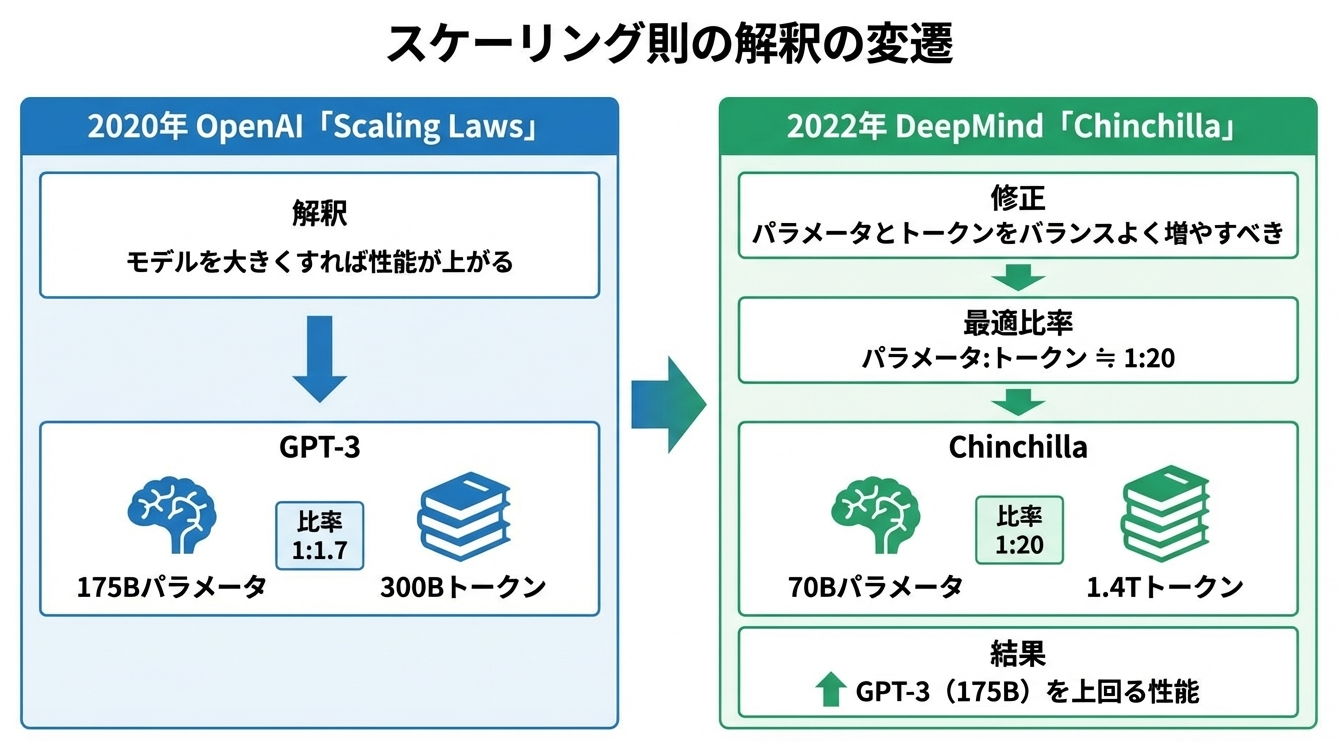
DeepMindの研究者たちは、同じ計算予算を使う場合、モデルサイズとデータ量(トークン数)のバランスが重要であることを発見しました。その最適な比率は、
パラメータ数:トークン数 ≒ 1:20
です。
この観点からGPT-3を見ると、明らかに「学習不足」でした。1750億パラメータに対して3000億トークンしか学習していません。最適比率に従えば、3.5兆トークン程度が必要だったことになります。
DeepMindはこの理論に基づいて、700億パラメータのChinchillaモデルを1.4兆トークンで学習させました。そして、この700億パラメータのモデルが、1750億パラメータのGPT-3を上回る性能を示したのです。パラメータ数は半分以下なのに、です。
計算量の見積もり方
LLM学習に必要な計算量は、以下の式でおおよそ見積もることができます。
計算量(FLOP) ≈ 6 × パラメータ数 × トークン数
なぜ6倍なのでしょうか。Transformerの学習では、フォワードパスで約2倍、バックワードパスで約4倍の計算が必要とされており、合計で約6倍になります。
この式とChinchilla則を組み合わせると、興味深いことがわかります。モデルサイズを2倍にする場合、Chinchilla則に従うとトークン数も2倍にする必要があります。すると、計算量は4倍になります。つまり、モデルサイズに対して計算量は二乗で増加するのです。
| モデルサイズ | 最適トークン数 | 計算量 | 10B比 |
|---|---|---|---|
| 10B | 200B | 1.2×10²² FLOP | 1x |
| 70B | 1.4T | 5.9×10²³ FLOP | 50x |
| 100B | 2T | 1.2×10²⁴ FLOP | 100x |
10倍のモデルを最適に学習するには、100倍の計算量が必要です。この二乗則が、大規模モデルの学習コストを爆発的に増加させる原因です。
実際の学習時間
この計算量を実際の学習時間に換算してみましょう。A100 80GBのBF16理論性能は312 TFLOP/sですが、実効性能はその30〜50%程度、つまり100〜150 TFLOP/s程度です。
| モデル | 計算量 | A100 1枚での所要時間 |
|---|---|---|
| 10B | 1.2×10²² FLOP | 約2.5年 |
| 70B | 5.9×10²³ FLOP | 約125年 |
| 100B | 1.2×10²⁴ FLOP | 約250年 |
だから数千枚のGPUが必要になるわけです。
100Bモデルを3ヶ月で学習するには、約1000枚のGPUが必要になります。
2025年現在となってはそれほど大規模というわけでもない100B規模のモデルでさえ、1000枚のGPUと3か月という期間が必要になります。これを知っただけでも、どれだけLLMの学習が大変かわかるとおもいます。
1枚何百万円もするGPUを千枚単位で調達ができる事業体は日本ではほとんどおらず、国をあげたAI推進施策にのっかるしかないというのが現状です。
いうまでもなく、個人や小さな研究室等でまともに使える規模をもつLLMのフルスクラッチ学習は不可能に近いというのが現実です。
ただ、上記はフルスクラッチで完全にゼロから学習させる場合であり、LLM開発はそれ以外にもいくつかの段階があります。
5. LLM開発の4つの段階
LLMの開発には、関与の深さによって4つの段階があります。それぞれ必要なリソースと技術的難易度が大きく異なります。
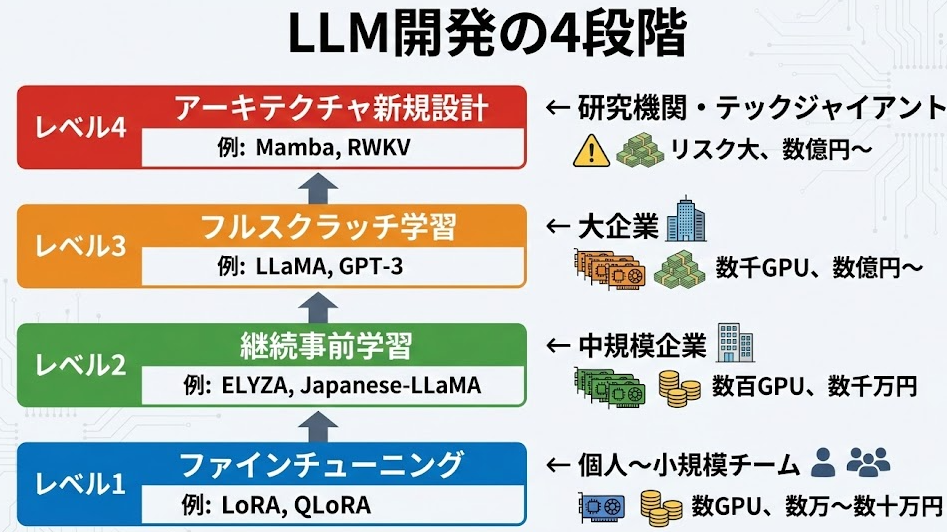
レベル1:ファインチューニング
最も手軽なのがファインチューニングです。これは、既存の学習済みモデル(LLaMA、Mistral、Qwenなど)を、特定のタスクに適応させる手法です。
ファインチューニングで行うのは、モデルの「振る舞い」を調整することです。チャット形式で応答するようにする、特定のフォーマットで出力させる、特定のタスク(要約、翻訳など)に特化させる、といった目的で行います。モデルが持っている知識自体を大きく変えるわけではありません。
必要なデータ量は数千から数万サンプル程度です。計算量はフルスクラッチ学習の100分の1から1000分の1以下です。LoRA(Low-Rank Adaptation)やQLoRA(Quantized LoRA)といった手法を使えば、VRAM使用量も大幅に削減できます。QLoRAなら、70Bモデルのファインチューニングを24GBのGPU1枚で実行することも可能です。
レベル2:継続事前学習
次の段階が継続事前学習(Continued Pre-training)です。これは、既存のモデルに新しい知識や言語能力を追加する手法です。
たとえば、英語中心で学習されたLLaMAに日本語能力を追加したい場合、日本語のテキストを大量に読ませる継続事前学習を行います。あるいは、医療や法律といった専門分野の知識を強化したい場合に、その分野の文書で継続事前学習を行います。
ファインチューニングとの違いは何でしょうか。ファインチューニングが「振る舞い」を調整するのに対し、継続事前学習は「知識」を追加します。必要なトークン数は、フルスクラッチの10%〜20%程度です。
レベル3:フルスクラッチ学習
フルスクラッチ学習は、ランダム初期化された重みから、モデルをゼロから学習させる手法です。LLaMAやGPT-3の学習がこれに該当します。
Transformerというアーキテクチャ自体は既存のものを使いますが、モデルの重みは完全に新規に学習します。言語の基本構造から世界知識まで、すべてをデータから学習させます。
Chinchilla則に従うと、100Bモデルなら2兆トークン、計算量にして約1.2×10²⁴ FLOPが必要です。これをH100で3ヶ月で終わらせるには、約1000枚のH100が必要です。
レベル4:アーキテクチャからの新規設計
最も挑戦的なのが、アーキテクチャからの新規設計です。MambaやRWKVといったアーキテクチャがこれに当たります。成功すれば計算効率の大幅な改善が期待できますが、失敗すれば数億円が無駄になるリスクがあり、研究機関か大企業でなければ手が出せません。
どの段階を選ぶべきか
ほとんどの組織にとって、レベル1(ファインチューニング)かレベル2(継続事前学習)が現実的な選択肢です。LLaMA、Mistral、Qwenといった高性能なオープンモデルが公開されている今、ゼロからモデルを学習する合理性は限られています。
6. 学習タイプ別の詳細比較
3つの学習タイプの比較
| 項目 | ファインチューニング | 継続事前学習 | フルスクラッチ |
|---|---|---|---|
| 目的 | 振る舞いの調整 | 知識の追加 | ゼロからの学習 |
| データ量 | 数千〜数万サンプル | フルの10〜20% | Chinchilla則に従う |
| 計算コスト比 | 1 | 10〜20 | 100 |
| 70Bの所要時間 | 数時間〜数日 | 数週間 | 数ヶ月(数千GPU) |
| 用途例 | チャットボット、タスク特化 | 日本語追加、専門知識強化 | 独自基盤モデル構築 |
フルスクラッチ学習の詳細
フルスクラッチ学習では、モデルの重みがランダムに初期化された状態からスタートします。この時点でモデルは、言語というものが何かすら知りません。
学習データとして与えられる大量のテキストを読み込む中で、モデルは次のことを順番に学んでいきます。まず、単語や文字のパターンを学びます。次に、文法的な構造を学びます。そして、事実に関する知識を獲得し、最終的には推論能力を身につけます。これらすべてを、「次の単語を予測する」というシンプルなタスクを通じて学習します。
継続事前学習の詳細:なぜ計算量が減るのか
継続事前学習は、なぜフルスクラッチより計算量が少なくて済むのでしょうか。
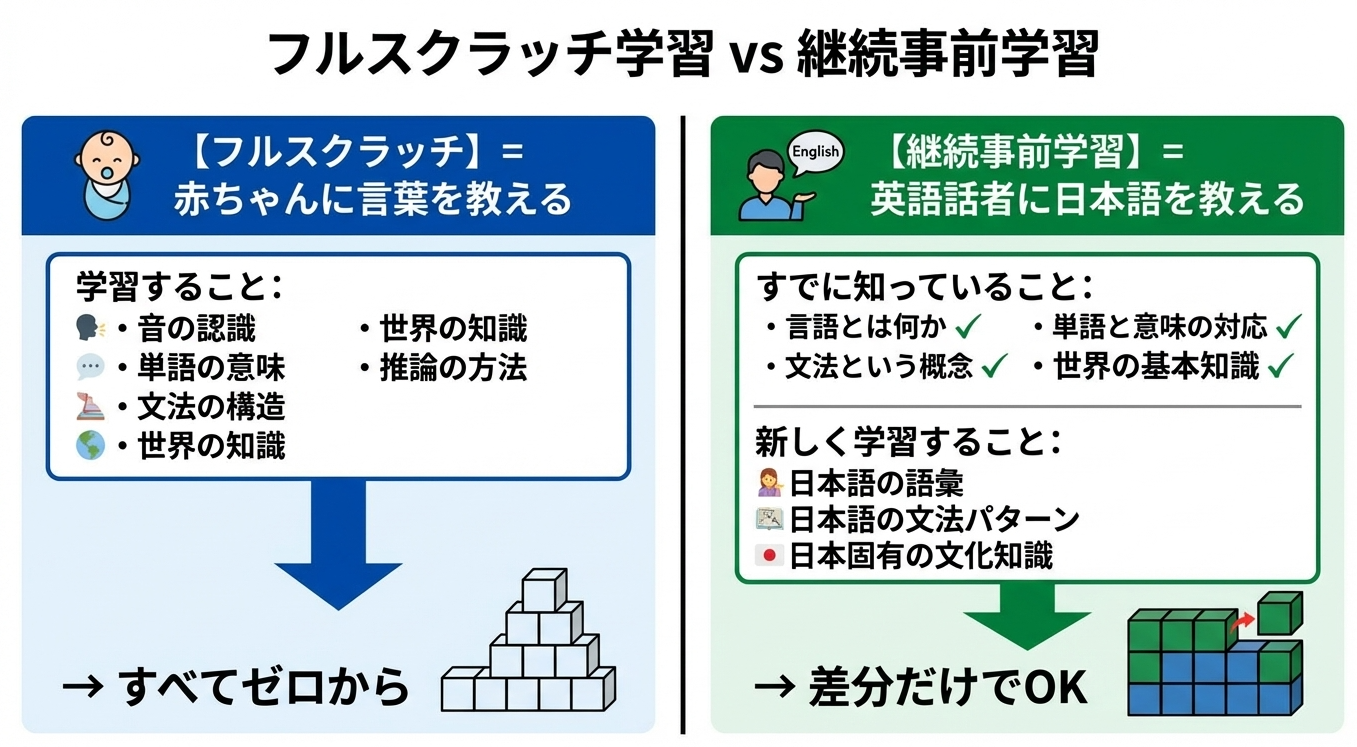
英語で学習されたLLaMAは、すでに「言語モデルとして振る舞う方法」を知っています。日本語の継続事前学習で必要なのは、日本語固有の「差分」だけです。
具体的なトークン数で言えば、70Bモデルのフルスクラッチには1.4兆トークン必要なところ、継続事前学習なら1000億〜2000億トークン程度で効果が得られます。10分の1から7分の1程度です。
ただし、注意点もあります。継続事前学習では、元のモデルの能力を忘れないようにする必要があります。日本語だけを学習させると、英語の能力が劣化することがあります(Catastrophic Forgetting)。そのため、継続事前学習のデータには、ある程度の英語テキストも混ぜることが一般的です。
ファインチューニングの詳細:LoRA/QLoRAの仕組み
ファインチューニングの目的は、モデルの知識を増やすことではなく、出力の形式や振る舞いを調整することです。
たとえば、LLaMAをそのまま使うと、入力テキストの続きを生成するだけです。「日本の首都は?」と入力しても、「日本の首都は?という問題は地理の授業でよく出題される...」のように、質問の続きを書いてしまうかもしれません。ファインチューニングによって、「質問されたら答える」という振る舞いを学習させます。
LoRA(Low-Rank Adaptation)は、ファインチューニングを効率化する手法です。
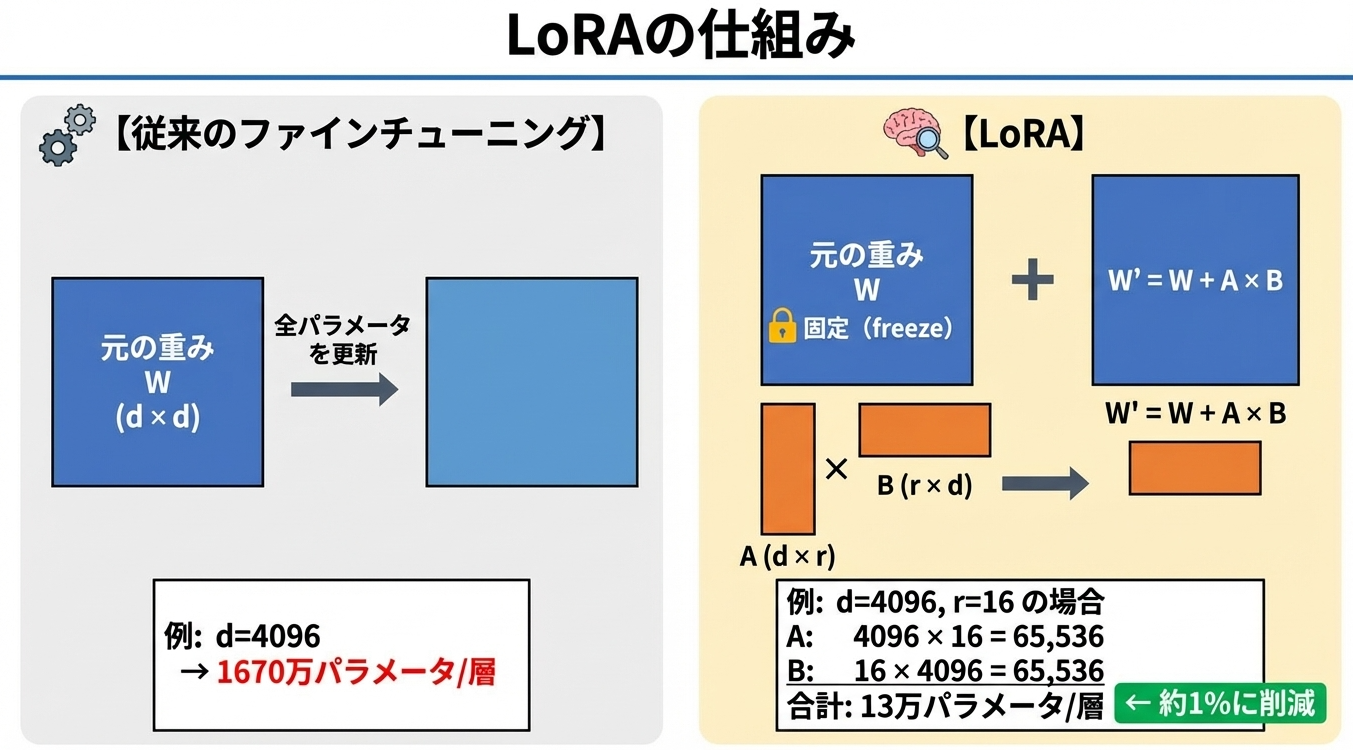
QLoRAはLoRAをさらに進めた手法です。元のモデルを4bit量子化して保持し、LoRAのアダプター部分だけをFP16で学習します。これにより、70Bモデルのファインチューニングが24GB程度のVRAMで可能になります。
7. MoE(Mixture of Experts)の仕組み
MoEとは何か
シャンパンのことではありません。LLM界でのMOEとはMoE(Mixture of Experts)アーキテクチャです。
Mixtral 8x7BやDeepSeek-V3などが採用しています。
MoEの基本的なアイデアは、「すべての入力に対してモデル全体を使う必要はない」というものです。入力に応じて、モデルの一部だけを選択的に使用します。
MoEの概念自体は古く、1991年にJacobs氏とHinton氏(2024ノーベル物理学賞を受賞しましたね!)によって提案されました。2017年にGoogleのShazeerらがTransformerへの適用を試み、2023年から2024年にかけてMistralのMixtralやDeepSeekの成功により一気に主流となりました。
MoEの構造
通常のTransformerでは、各層が「Attention → FFN」という構造になっています。MoE Transformerでは、FFNの部分が複数のExpert(それぞれがFFN)になり、入力ごとに一部のExpertだけが選択されます。
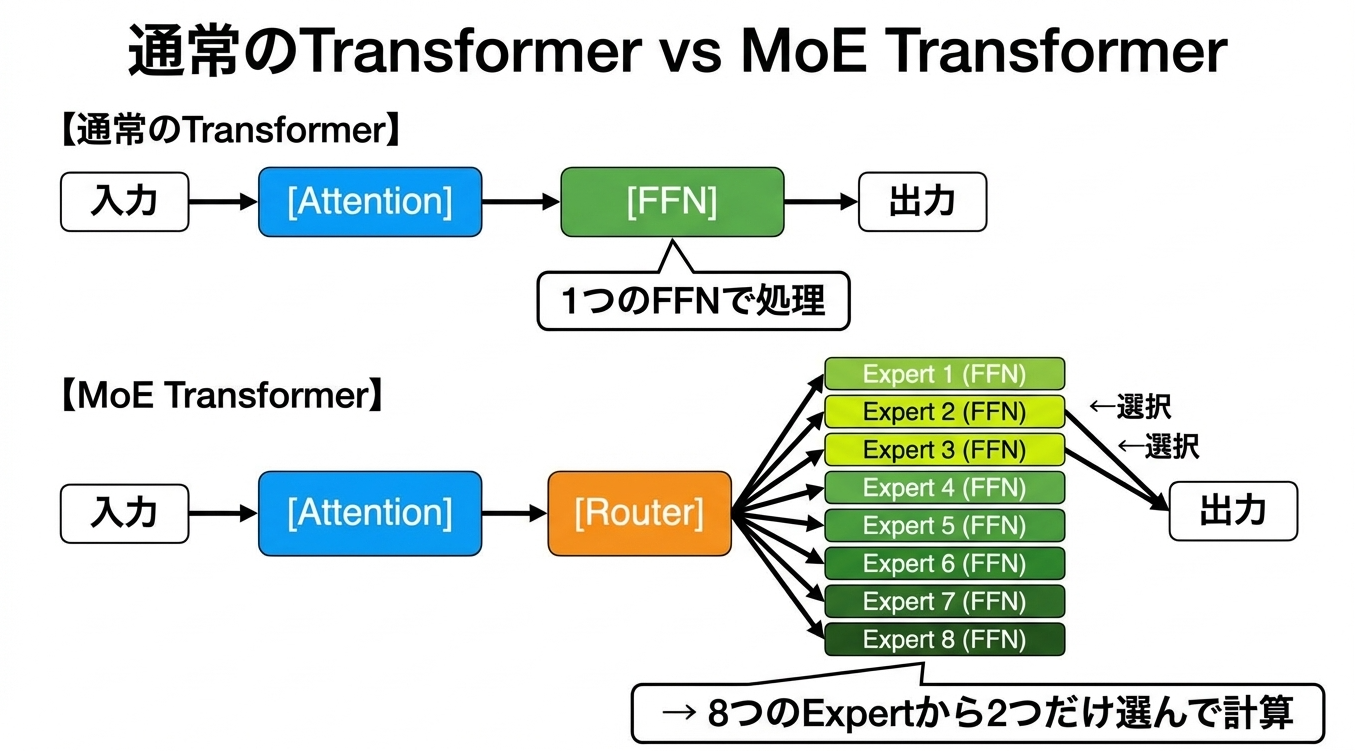
コードで見ると、以下のようになります。
class MoE(nn.Module):
def __init__(self, hidden_size, num_experts=8):
super().__init__()
# Expert = 普通のFFN(全結合層)が複数
self.experts = nn.ModuleList([
nn.Sequential(
nn.Linear(hidden_size, hidden_size * 4),
nn.GELU(),
nn.Linear(hidden_size * 4, hidden_size)
) for _ in range(num_experts)
])
# Router = どのExpertを使うか決める層
self.router = nn.Linear(hidden_size, num_experts)
def forward(self, x):
scores = self.router(x) # ルーターがスコアを出す
top2_scores, top2_indices = scores.topk(2, dim=-1) # 上位2つ選択
# 選ばれたExpertだけで計算...
なぜMoEで計算量が減るのか
MoEの革新的な点は、パラメータ数と計算量を切り離したことです。
| モデル | 総パラメータ | 活性化パラメータ | 計算コスト相当 |
|---|---|---|---|
| Dense 70B | 70B | 70B | 70B |
| Mixtral 8x7B | 47B | 13B | 13B |
| DeepSeek-V3 | 671B | 37B | 37B |
DeepSeek-V3を例に取ると、総パラメータ数は6710億ですが、1トークンあたり活性化されるのは370億パラメータだけです。計算コストは370億パラメータのDenseモデルと同等でありながら、モデル全体としては6710億パラメータ分の「知識容量」を持つことになります。
ただしVRAMは減らない
ここで重要な注意点があります。MoEは計算量を減らしますが、VRAMの使用量は減りません。
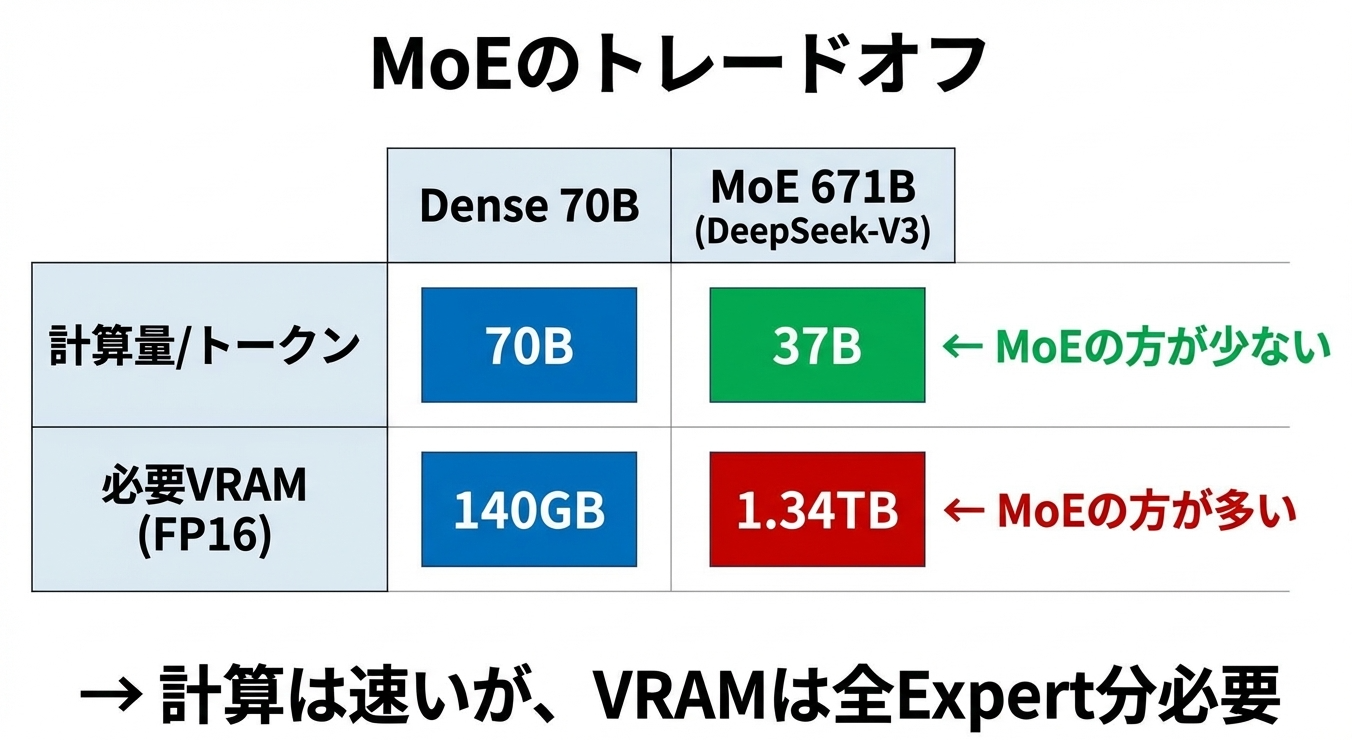
推論時にどのExpertが活性化されるかは、入力に依存して動的に決まります。そのため、すべてのExpertをVRAM上に載せておく必要があります。
DeepSeek-V3がコスト効率に優れている理由
DeepSeek-V3は、6710億パラメータのMoEモデルを、H800×2048枚、約2ヶ月、約5.6百万ドル(約8億円)で学習しました。同規模のモデルとしては驚異的に安いコストです。なぜでしょうか。
| 技術 | 効果 |
|---|---|
| MoEアーキテクチャ | 計算量を約1/18に削減(671B→37B相当) |
| FP8学習 | 計算量・通信量を半分に |
| Multi-head Latent Attention | KVキャッシュのメモリ削減 |
| 通信パターン最適化 | Expert間ルーティングの効率化 |
MoEアーキテクチャだけでなく、FP8学習、Multi-head Latent Attention(MLA)、通信パターンの最適化など、複数の技術革新を組み合わせています。また、先行するMoEモデル(DBRXなど)から約9ヶ月の間に蓄積されたノウハウも大きく貢献していると考えられます。
8. 実際の学習事例から見るコスト感
ここまで理論的な話が続きました。では、実際のLLM学習にはどれくらいのリソースとコストがかかっているのでしょうか。公開されている情報をもとに見ていきます。
過去のLLMモデルの学習スペック
やや古いデータですが、規模が公開(一部は推定)されているLLMモデルの学習規模を示します
| モデル | サイズ | GPU | 枚数 | 期間 | トークン数 | コスト |
|---|---|---|---|---|---|---|
| LLaMA 2 7B | 7B | A100 80GB | - | 18.4万GPU時間 | 2T | 約8500万円 |
| LLaMA 2 70B | 70B | A100 80GB | 2,048 | 23日 | 2T | 約5億円 |
| DBRX | 132B (MoE) | H100 | 3,072 | 2.5ヶ月 | 12T | 約15億円 |
| DeepSeek-V3 | 671B (MoE) | H800 | 2,048 | 2ヶ月 | 14.8T | 約8億円 |
| GPT-4(推定) | 〜1.8T (MoE) | - | 〜25,000 | 3〜5ヶ月 | - | 約150億円 |
※コストはクラウド換算の概算値
LLaMA 2(Meta, 2023)
LLaMA 2は、Metaが2023年に公開したオープンソースLLMです。70Bモデルの学習には、A100 80GBが2,048枚使われ、約23日かかりました。GPU時間に換算すると、2048 × 24 × 23 ≒ 113万GPU時間です。
A100 80GBのクラウド料金を1時間3ドルとすると、113万 × 3 = 約340万ドル(約5億円)のコストになります。
DBRX vs DeepSeek-V3
両者の比較は興味深いです。
| 項目 | DBRX | DeepSeek-V3 | 比率 |
|---|---|---|---|
| パラメータ | 132B | 671B | 5.1x |
| トークン数 | 12T | 14.8T | 1.2x |
| GPU枚数 | 3,072 | 2,048 | 0.67x |
| 期間 | 2.5ヶ月 | 2ヶ月 | 0.8x |
| コスト | 約15億円 | 約8億円 | 0.53x |
DeepSeek-V3はDBRXの5倍のパラメータを持ちながら、コストは半分程度です。FP8学習やMLAなどの技術革新が効いています。
学習コストの目安
これらの事例から、Denseモデルのフルスクラッチ学習について「1Bパラメータあたり約1000 GPU週間」「1Bパラメータあたり約700万円」という目安が得られます。ただし、これはChinchilla則に従った最適な学習量での見積もりです。
9. GPU別の現実的な学習規模
では、具体的にどのGPUで何ができるのでしょうか。各GPUのスペックと、現実的な用途を見ていきます。
GPU スペック比較
記事内で触れたGPUスペックを以下に示します
| GPU | VRAM | BF16性能 | 価格(概算) | NVLink |
|---|---|---|---|---|
| A6000 | 48GB | 38 TFLOP/s | 70万円 | 2枚まで |
| A100 40GB | 40GB | 312 TFLOP/s | 100万円(中古) | 8枚まで |
| A100 80GB | 80GB | 312 TFLOP/s | 180万円(中古) | 8枚まで |
| H100 SXM | 80GB | 990 TFLOP/s | 500万円 | 8枚まで |
| B200 | 192GB | 2,250 TFLOP/s | 700万円〜 | 8枚まで |
その他GPUについても当社の別ブログ記事で詳しく確認することが可能です
A6000(48GB)の場合
A6000は、NVIDIAのプロフェッショナル向けGPUです。注意点は、NVLinkが2枚までしか接続できないことです。3枚以上を使う場合、GPU間通信はPCIe経由になります。
| 用途 | A6000×4枚で可能か | 備考 |
|---|---|---|
| 70B推論(INT4) | ○ | 35GB必要、余裕あり |
| 70BファインチューニングQLoRA) | ○ | 24GB/枚程度で可能 |
| 10B継続事前学習 | ○ | 数週間かかる |
| 10Bフルスクラッチ | △ | 数ヶ月〜1年 |
| 70Bフルスクラッチ | × | 非現実的 |
A100(80GB)の場合
A100はNVSwitchを介して8枚までNVLink接続できます。
| 用途 | A100 80GB×8枚で可能か | 備考 |
|---|---|---|
| 70B推論(FP16) | ○ | 140GB必要、複数インスタンス可 |
| 70Bファインチューニング | ○ | 快適 |
| 30B継続事前学習 | ○ | 数週間 |
| 30Bフルスクラッチ | ○ | 数ヶ月 |
| 100Bフルスクラッチ | × | 1年以上かかる |
H100の場合
H100はA100の約3倍の性能があります。
| 構成 | 可能なこと |
|---|---|
| H100×8枚 | A100×8の3倍速、30Bフルスクラッチが現実的 |
| H100×100枚 | 100Bフルスクラッチが約3ヶ月で可能 |
| H100×1000枚 | 100Bを数週間、GPT-4クラスはまだ不足 |
規模別のまとめ

10. 推論に必要なGPU
推論については本稿では扱いませんが、こちらのシリーズにて詳しく解説しています。
11. 日本語LLMの現状
日本語LLMの開発動向についてもみておきましょう。
日本語のオープンモデルが登場したのは2023年夏ごろです。日本製の筆頭は rinnaさんで、そのすぐ後に Cyberagentさんのモデルが出てきたように記憶しています。日本語のモデルもアーキテクチャは GptNeoXをベースにしたもののフルスクラッチ学習からはじまり、2023年の後半には継続事前学習モデルへと変遷していきました。2024年以降はより性能の高いQwenをベースとした継続事前学習へとつながっています。最新の高性能な日本語LLMについては、こちらの記事で日本語LLMをランキング形式で解説しています。
日本語LLM開発の変遷
| 時期 | 主流アプローチ | 代表例 |
|---|---|---|
| 2022〜2023年前半 | フルスクラッチ | rinna 3.6B, OpenCALM-7B, Weblab-10B |
| 2023年後半〜 | 継続事前学習 | ELYZA-Llama, Japanese StableLM |
| 2024年〜 | Qwenベース | 各社のQwen派生モデル |
なぜフルスクラッチからと継続事前学習に移行したのか
2023年2月のLLaMA公開が転機となりました。
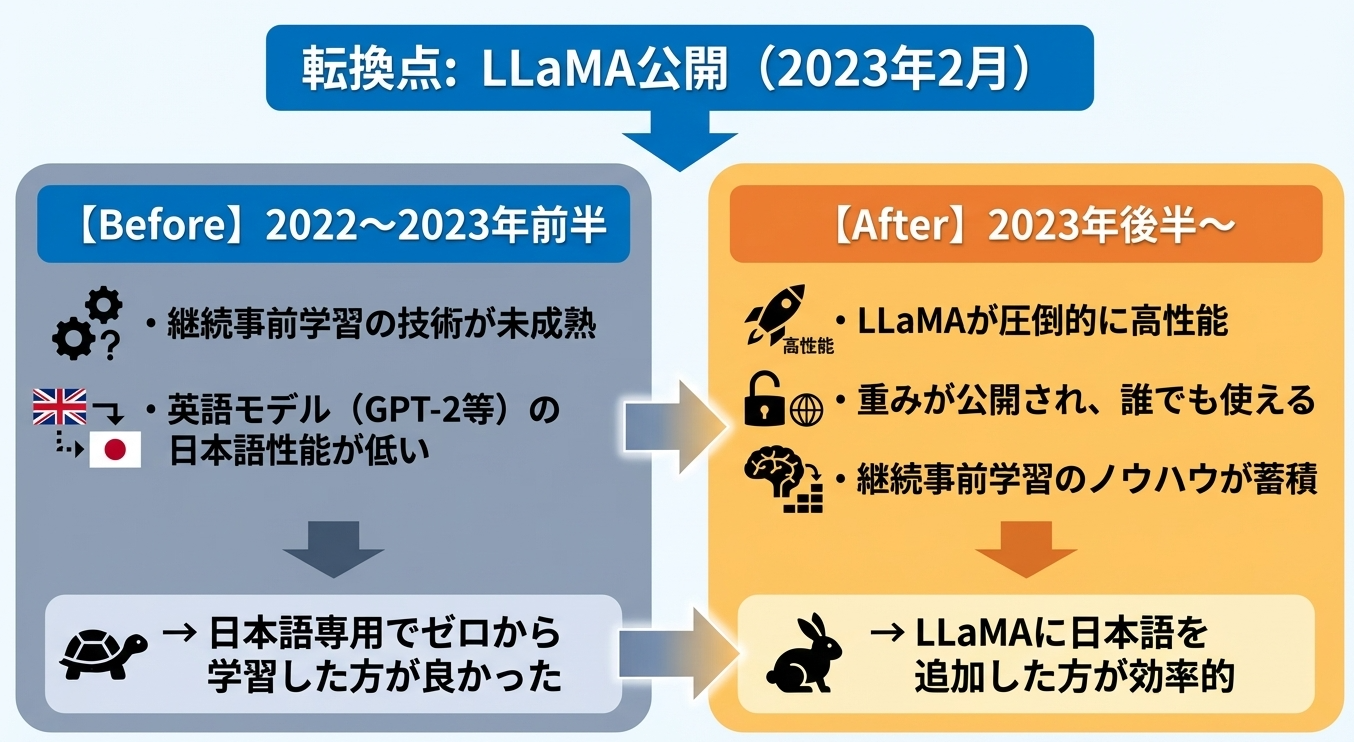
継続事前学習への移行が進んだ理由は、効率の違いです。LLaMAはすでに「言語モデルとしての基礎能力」を持っています。日本語をゼロから学習するより、LLaMAに日本語を追加する方が、同じ計算コストで高い性能が得られることがわかってきました。
なぜQwenベースが日本語に強いのか
最近では、中国のAlibabaが開発したQwenをベースにした日本語モデルも登場しています。興味深いことに、LLaMAベースよりQwenベースの方が日本語性能が高いことがあります。なぜでしょうか。
答えはトークナイザーにあります。
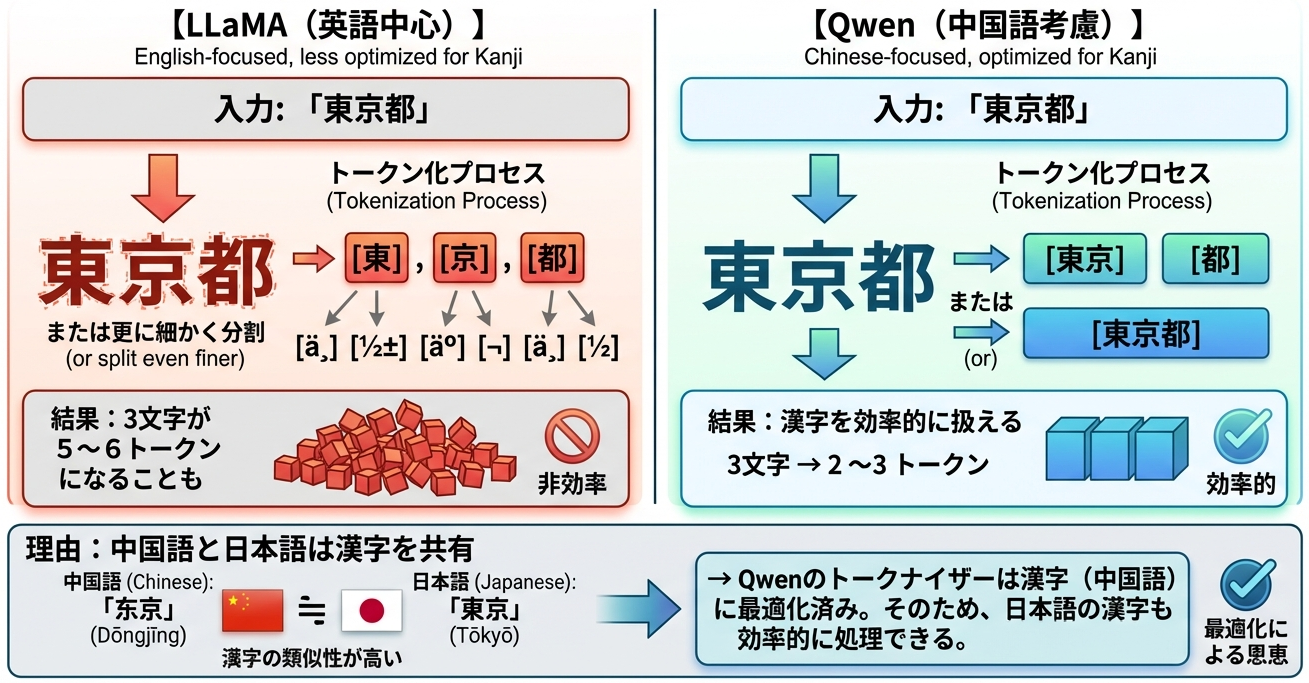
トークン効率が良いと、同じコンテキスト長でより多くの情報を扱えます。また、同じテキストの学習に必要なトークン数が少なくなるため、学習効率も上がります。
さらに、中国語と日本語は文法構造も一部共通しています。漢字熟語の語順、敬語のような丁寧表現など、英語よりも近い部分があります。英語モデルに日本語を追加するより、中国語モデルに日本語を追加する方が、転移学習の効果が高いと考えられます。
12. まとめ
学習タイプ別の比較
フルスクラッチ>継続事前学習>ファインチューニングという学習タイプがあることをみてまいりましたが、多くの場合、継続事前学習で十分であることをご理解いただけたかと思います。
| 項目 | ファインチューニング | 継続事前学習 | フルスクラッチ |
|---|---|---|---|
| 目的 | 振る舞いの調整 | 知識の追加 | ゼロからの学習 |
| データ量 | 数千〜数万サンプル | フルの10〜20% | パラメータ×20トークン |
| 計算コスト比 | 1 | 10〜20 | 100 |
| 70Bの所要時間 | 数時間〜数日(数GPU) | 数週間(数百GPU) | 数ヶ月(数千GPU) |
| 用途例 | チャットボット、タスク特化 | 日本語追加、専門知識 | 独自基盤モデル |
実際の学習事例
モデルサイズが大きくなると、コストや期間が指数関数的にふくれあがることもみてまいりました。
| モデル | サイズ | GPU枚数 | 期間 | コスト |
|---|---|---|---|---|
| LLaMA 2 7B | 7B | - | 18.4万GPU時間 | 約8500万円 |
| LLaMA 2 70B | 70B | 2,048 | 23日 | 約5億円 |
| DBRX | 132B (MoE) | 3,072 | 2.5ヶ月 | 約15億円 |
| DeepSeek-V3 | 671B (MoE) | 2,048 | 2ヶ月 | 約8億円 |
| GPT-4(推定) | 〜1.8T (MoE) | 〜25,000 | 3〜5ヶ月 | 約150億円 |
結論
ここまで見てきたように、LLMのフルスクラッチ学習は、数千枚のGPUと数億〜数百億円の投資を必要とする、極めて特殊なワークロードです。これを現実的に行えるのは、世界でもごく一部のプレイヤーに限られます。
しかし、それは「GPUを使ったLLM開発が無意味」という話ではありません。
本記事で見てきたように、ファインチューニングや継続事前学習であれば、現実的なGPUリソースで十分に取り組めます。
QLoRAを使えば70Bモデルのファインチューニングが24GBのGPU1枚で可能ですし、A100が数枚あれば継続事前学習で日本語能力や専門知識を追加することもできます。LLaMA、Mistral、Qwenといった高性能なオープンモデルをベースに、自社のニーズに合わせてカスタマイズする。これが、GPUを活用した最も費用対効果の高いアプローチです。
一方で、すべてのユースケースでGPUが必要なわけでもありません。ChatGPTやClaudeといった商用APIは、インフラ管理の手間なく最先端の性能を利用できます。プロトタイピングや小規模な運用であれば、APIから始めるのが合理的な選択肢です。
結局のところ、重要なのはモデルを自前で作ることではなく、どう活用するかです。自社固有のデータとどう組み合わせるか。どんな業務プロセスに組み込むか。どんな顧客価値を生み出すか。オープンモデルのカスタマイズでも、商用APIの活用でも、差別化の源泉はそこにあります。
LLM導入・GPU環境構築のご相談
さて、これまでの内容はいかがだってでしょうか。
当社では、GPUクラスタの設計・構築から、PyTorchによるモデル開発、LLMの推論・学習・実装まで、理論だけでなく自社GPU環境での技術検証を含めた実践的なサポートを提供しています。
「自社に最適なGPU構成がわからない」「オープンモデルのファインチューニングを試したい」
「商用APIとオンプレどちらを選ぶべきか判断できない」
「オープンモデルを使いたいけど、どうやったら社内で活用できるのか」
そんなお悩みがあれば、ぜひお気軽にお問い合わせください。
参考資料
- Kaplan et al. (2020). "Scaling Laws for Neural Language Models". OpenAI.
- Hoffmann et al. (2022). "Training Compute-Optimal Large Language Models". DeepMind.
- Hu et al. (2021). "LoRA: Low-Rank Adaptation of Large Language Models".
- Dettmers et al. (2023). "QLoRA: Efficient Finetuning of Quantized LLMs".



