
【2024/5/14更新】LLM 推論 API 料金と推論速度


LLM を API から利用するときに従量課金される料金と生成速度一覧まとめました。順次更新予定です。
【API 料金】 は 100万トークンあたりのアウトプット側 利用料を表示しています。
【生成速度】 は1秒間に何トークン生成できるかを示す " tokens/s"( tokens per second )で表示します。
(生成速度は入出力プロンプトの量・内容によって変動しますので、あくまで参考情報として表示しています)
OpenAI GPT シリーズ
- OpenAI GPTシリーズ
- gpt-4o、100万トークンあたり $15.00 (約2250円)、 70 tokens/s

- gpt-4-turbo-2024-04-09: 100万トークンあたり $30.00 (約4500円)、 45 tokens/s

- gpt-3.5-turbo-0125: 100万トークンあたり $1.5 (約225円)、100 tokens/sc

Amazon Bedrock
- Amazon Bedrock
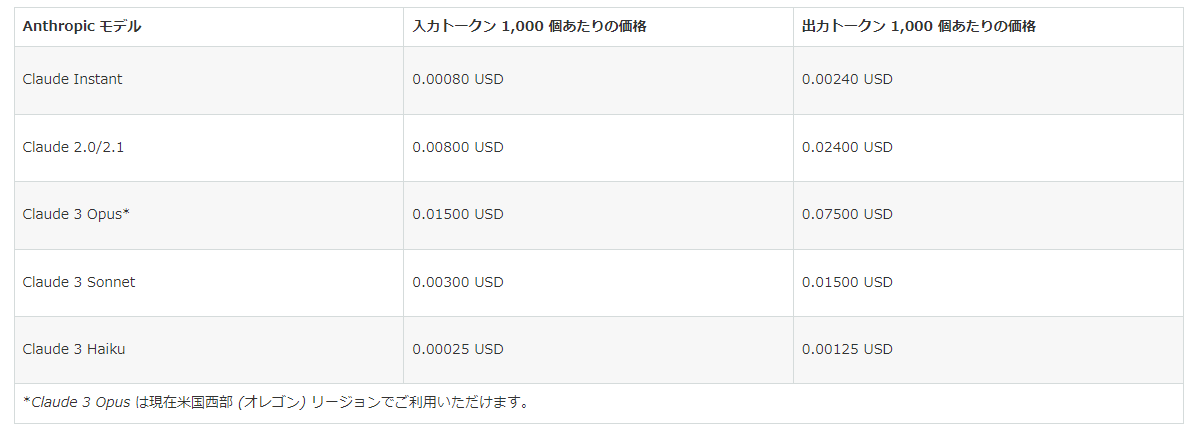
- Claude3 Opus: 100万トークンあたり $75 (約11250円)
- Claude3 Sonnet: 100万トークンあたり $15 (約2250円)
- Claude3 Haiku: 100万トークンあたり $1.25(約188円)、生成速度 120 tokens/s
- Llama3 70B: 100万トークンあたり $3.5 (約525円)、生成速度 36.5 tokens/s
- Llama3 8B: 100万とーくんあたり 生成速度 77.8 tokens/s
Llama3-8B-instruct を Amazon Bedrock の Playground で動作させ生成速度(tokens/sec)を確認
Llama3-70B-instruct を Amazon Bedrock の Playground で動作させ生成速度(tokens/sec)を確認
Groq
- Groq
- Llama3 70B: 100万トークンあたり $0.79(約119円) 、生成速度 302 tokens/s
- Llama3 8B: 100万トークンあたり $0.1 (約15円)、生成速度 900 tokens/s

Llama3-8B-instruct を Groq で動作させ生成速度(tokens/sec)を確認
Llama3-70B-instruct を Groq で動作させ生成速度(tokens/sec)を確認
fireworks.ai
- fireworks.ai
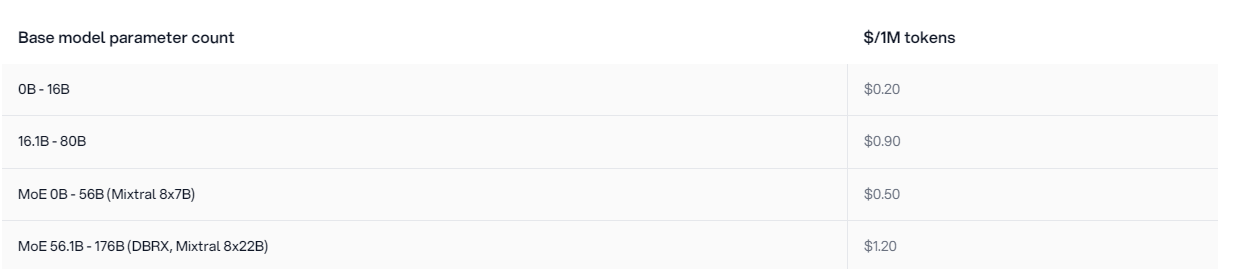
- 16Bモデル: 100万トークンあたり、$0.20 (約30円)、
例) Llama3-8B-Instruct 269 tokens/sec - 80Bモデル: 100万トークンあたり、$0.90 (約135円)、
例) Llama3-70B-Instruct 200 tokens/sec
- 16Bモデル: 100万トークンあたり、$0.20 (約30円)、
Llama3-70B-instruct を fireworks.ai で動作させ生成速度(tokens/sec)を確認
Llama3-8B-instruct を fireworks.ai で動作させ生成速度(tokens/sec)を確認
deepseek.com
- deepseek.com
- 236Bモデル: 100万トークンあたり、$0.28 (約42円)、
DeepSeek-V2-Chat ≒25 tokens/sec
- 236Bモデル: 100万トークンあたり、$0.28 (約42円)、
Deepseek V2 Chat
まとめ
2024/05/13 に GPT-4o が発表され、100万トークンあたりこれまでの GPT-4-Turboの半額となりクローズドLLMの性能・コスト競争がさらに激しくなっています。
オープンLLMでは、推論速度の点では、2024年5月現在、Groq が頭一つ抜け出ています。コストの点でもオープンな LLM の利用を前提とするならば Groq が優れています。
ただし、チューニングできるポイントやサポートの提供、過去の技術アセット、ノウハウ、人材調達の観点で総合的に判断して採用を決めるものですので採用に際しては総合的判断となるとおもいます。当社でも 上記内容ふくめ幅広い知見・経験をもとにしたLLM サービス構築コンサルティングを行っております。
LLM API を活用して最速でチャットボットを構築する
当社のLLMサービス開発ソリューション ChatStream をご利用いただくと、 LLM API を使用してノーコード・ローコードで本格的な UI を備えたチャットボットを構築可能です。(APIを使用せず、独自のオープンソースLLMをホスティング使用した推論サーバーソリューションも利用可能です)
LLMサービス開発、チャットボット開発についてご興味、ご関心のある方は以下よりお問い合わせくださいませ。
https://qualiteg.com/contact



