
ついに一般公開、Claude Mythos5(ミュトス)/ Fable 5(フェイブル) を実務視点で読み解く


こんにちは! Qualitegプロダクト開発部です。
2026年6月9日、Anthropicから Claude Fable 5(フェイブル5)と Claude Mythos 5(ミュトス5)が発表されました。
この記事では、
Fable 5 とは何か、Mythos 5 と何が違うのか、
Claude Code やAIエージェントを実務で使う立場から見て何が変わるのか
を整理します。当社ブログを読んでくださっている方は、4月の「強すぎて出せないモデル "Mythos"」や「Mythosレベルのオープンモデルはいつ出るのか」でも触れた、あの Mythosクラスの一般公開版がついに来た、という話でもあります。
この記事でわかること
- Fable 5 と Mythos 5 は「同じ基盤モデルだが、安全装置の有無が違う」こと
- 高リスク領域では応答が Opus 4.8 にフォールバック すること、その仕組みと実務上の注意点
- 企業利用では、料金・モデル切り替わり・30日データ保持・誤検知 を運用設計に組み込む必要があること
- ベンチマークの具体的数値と、当社が注目した「長時間自律タスク」での強さ
- 料金 $10 / $50 の位置づけと、賢いモデル振り分けの考え方
1. Fable 5 と Mythos 5
「同じ基盤モデル、安全装置だけが違う双子」
今回 2つのモデルが同時に発表された 点がまず混乱しやすいところです。
名前が違うので別物に見えますが、
Anthropicは両者を 同じ基盤モデル(same underlying model) だと明言しています。
違いは、セーフガード(安全装置)がかかっているかどうか だけです。
- Fable 5
一般公開版。サイバー・生物・化学・蒸留などの高リスク領域に制限(後述のフォールバック)がかかっている。誰でも使える。 - Mythos 5
制限を一部外した版。Project Glasswing のサイバー防御パートナーなど、審査を通った組織だけが使える。Anthropic自身が「世界で最も強力なサイバーセキュリティ能力を持つモデル」と表現している。
名前の由来も、この「双子」という構図を反映しています。
Anthropicは脚注で、"Fable"(寓話)はラテン語の fabula=「語られるもの」に由来し、ギリシャ語の mythos(神話)と同根だ、と説明しています。
中身は同じ語りの系譜で、安全装置の有無だけが両者を分ける
だから別の名前を与えた、というわけですね。
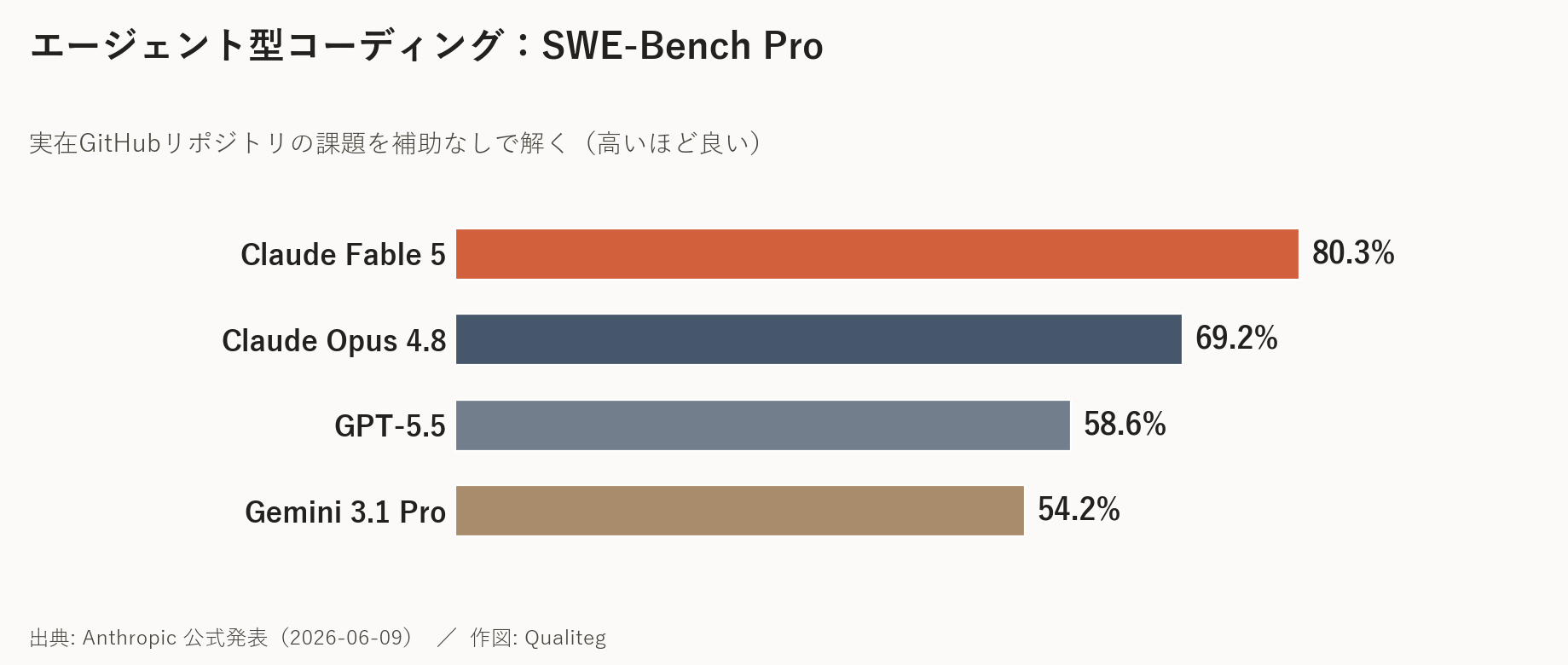
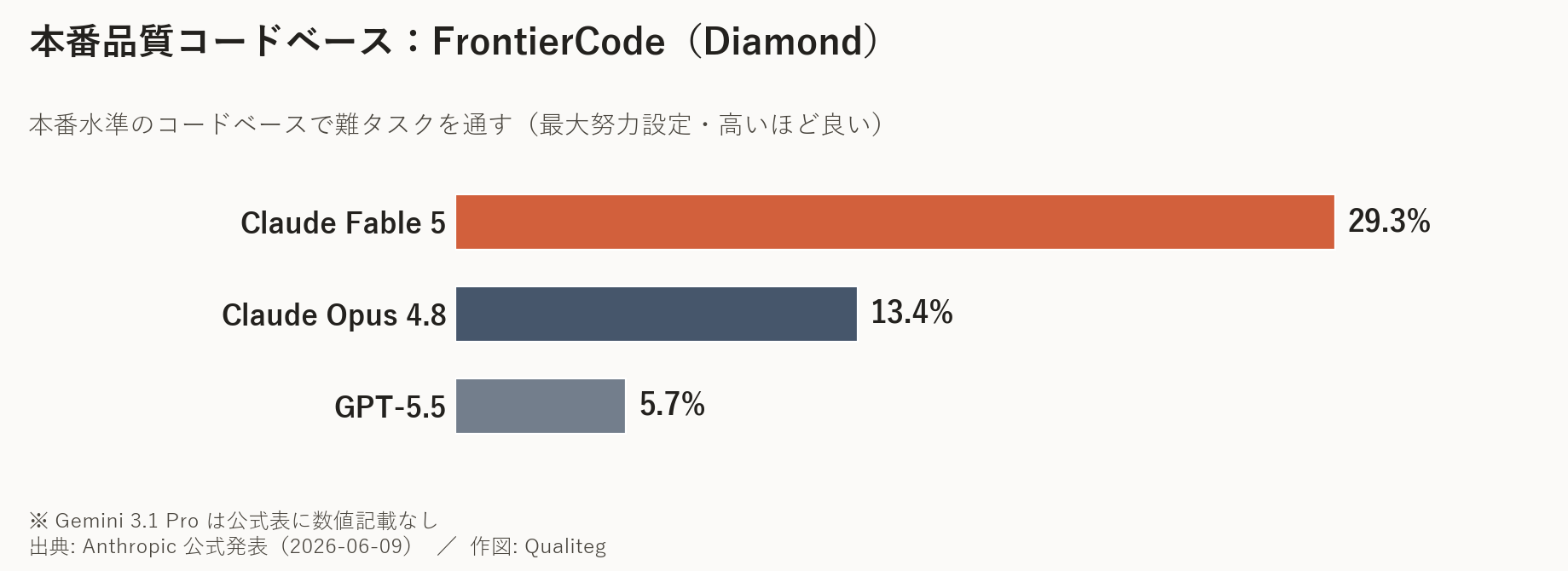
この「能力差ではなく安全装置差」という点は、以下に示す、ベンチマーク表にも表れています。
| 分野・ベンチマーク | Mythos 5 / Fable 5 | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| コーディング|SWE-Bench Pro | 80.3% | 69.2% | 58.6% | 54.2% |
| コーディング|FrontierCode(Diamond) | 29.3% | 13.4% | 5.7% | — |
| 知識労働|GDPval-AA(ELOレート) | 1932 | 1890 | 1769 | 1314 |
| 視覚|GDP.pdf(ツール無) | 29.8% | 22.5% | 24.9% | 16.7% |
| 空間推論|Blueprint Bench 2 | 38.6% | 14.5% | 36.2% | 26.5% |
| ツール利用|AutomationBench | 17.4% | 15.5% | 12.9% | 9.6% |
| コンピュータ操作|OSWorld Verified | 85.0% | 83.4% | 78.7% | 76.2% |
| 法務|Legal Agent Benchmark | 13.3% | 10.4% | 2.1% | 0.0% |
| 総合推論|Humanity's Last Exam(ツール無) | 59.0%*Fable実効 ≈49.8% | 49.8% | 41.4% | 44.4% |
| 総合推論|Humanity's Last Exam(ツール有) | 64.5%*Fable実効 ≈57.9% | 57.9% | 52.2% | 51.4% |
| 生物|BioMysteryBench(hard) | 46.1%*Fable実効 ≈40.0% | 40.0% | — | — |
| エージェント開発|Terminal-Bench 2.1 | 88.0%*Fable実効 ≈82.7% | 82.7% | 83.4% | 70.7% |
| サイバー|ExploitBench | 78.0%*Fable実効 ≈40%/ブロック時ほぼ0% | 40.0% | 34.0% | — |
| 健康|HealthBench Professional | 66.0%*Fable実効 ≈56.9% | 56.9% | 51.8% | — |
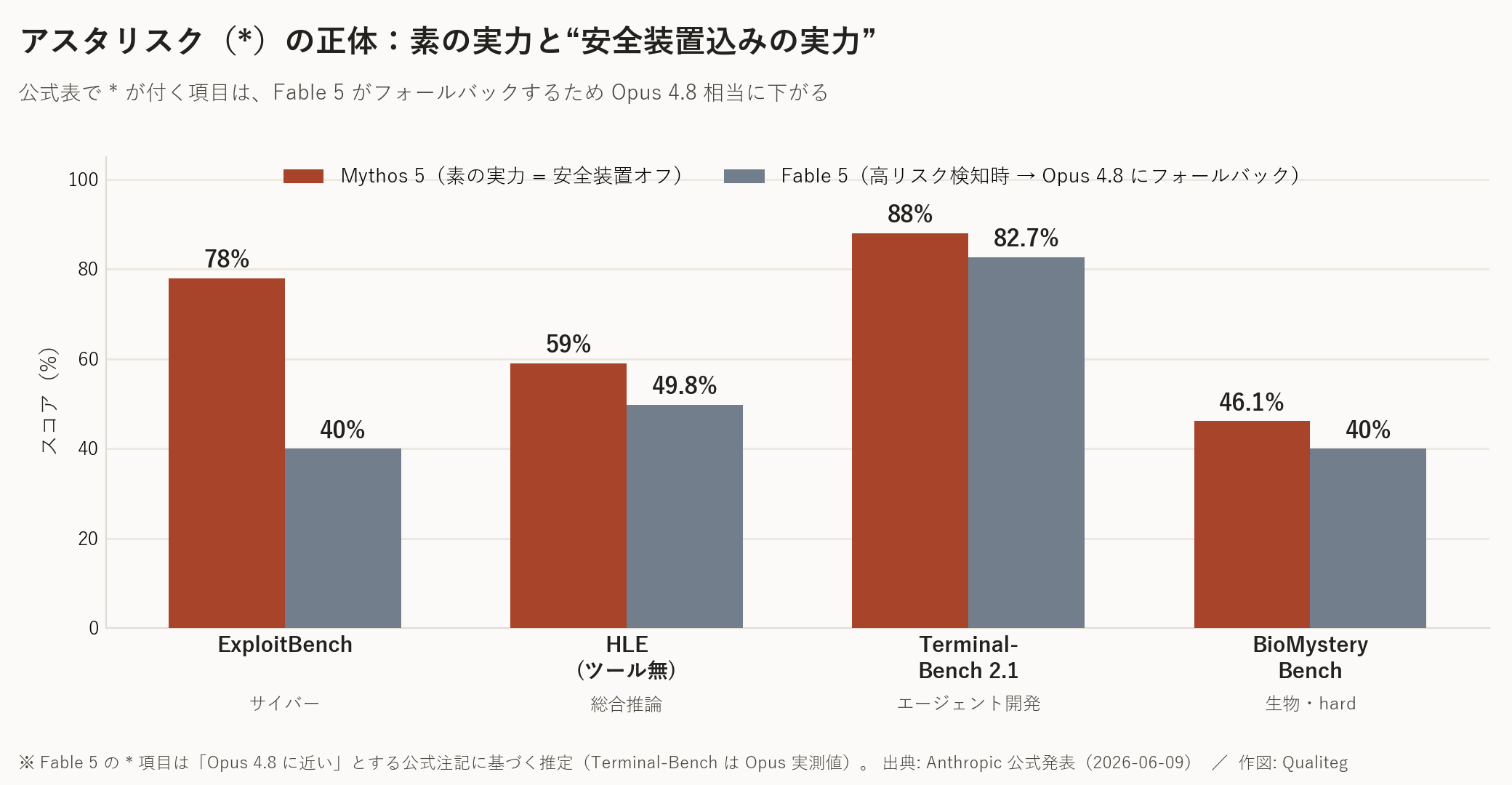
このベンチマーク表にはアスタリスク(*)付きの項目があり、そこに表示されている数字は 安全装置オフの Mythos 5 の値 です。
アスタリスクの無い項目では Fable 5 もほぼ同じ(差は通常1〜3ポイント以内)ですが、サイバー・生物などの * 付き項目では、実際に使える Fable 5 は Opus 4.8 寄りに 大きく下がります
(例:ExploitBench は Mythos 5 の78%に対し、Fable 5 の実効は40%前後)。
つまり、Fable 5 の素の実力そのものは Mythos 5 と同じで、両者のベンチ差は能力差ではなく、安全装置の効き具合の差だ、と読み解けます。
下の図は、この差を当社で可視化したものです。
サイバー(ExploitBench)や生物(BioMysteryBench)のように高リスク領域では、Mythos 5 の素の実力と、フォールバックが効いた Fable 5(≒ Opus 4.8 相当)のあいだに大きな差が出ます。
逆に言えば、この差こそが「安全装置の効き具合」です。
2. 本丸その1
高リスク領域は Opus 4.8 にフォールバックする
ここが、企業利用でいちばん押さえるべきポイントです。
Fable 5 には、サイバーセキュリティ・生物・化学・蒸留(distillation) に関する要求を検知すると、Fable 5 自身では応答せず、Opus 4.8 などの別モデルにフォールバックできる 仕組みが用意されています。
専用の分類器(classifier)が別系統のAIシステムとして動き、リスクのある要求やジェイルブレイク試行を検知して、Mythosクラスの能力を直接使わせず、より低リスクな次善のモデルに処理を逃がす、という設計です。
仕組みを図にすると、こうなります。
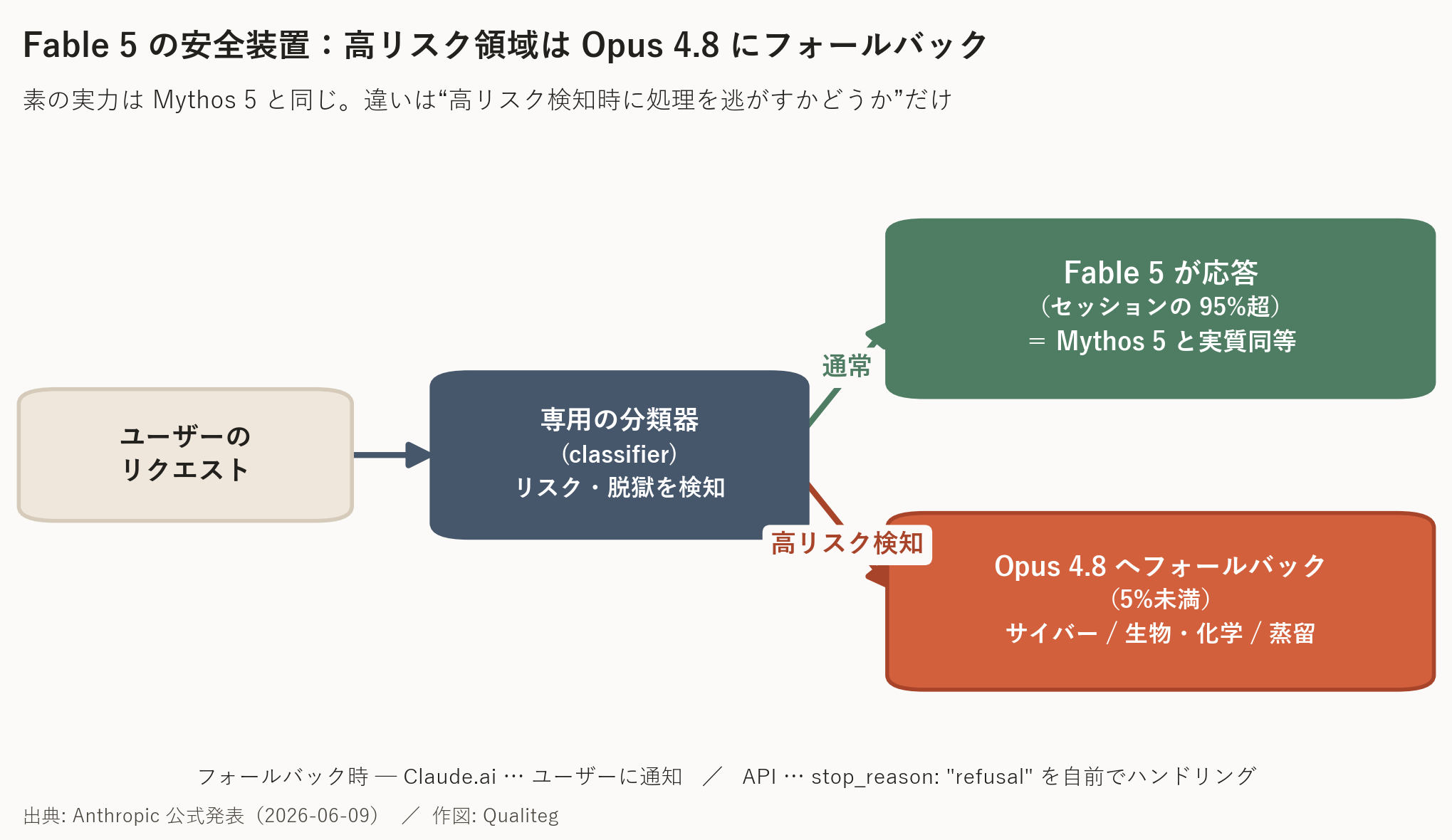
ここで実務上は、提供面によって挙動が違う 点に注意が必要です。
Claude.ai 上ではフォールバックが起きたときユーザーに通知されますが、API利用では「自動で必ず Opus 4.8 に切り替わる」とは限りません。
Messages API では Fable 5 が拒否した場合に stop_reason: "refusal" が返り、別モデルでの再試行は fallbacks パラメータやSDKミドルウェア、クライアント側のリトライを前提に設計する必要があります。エージェントを組む際は、この拒否レスポンスのハンドリングを最初から想定しておくのが安全です。
公式が説明していること
公式発表の要点を整理すると、こうです。
- セーフガードは 意図的に保守的(厳しめ)にチューニング してあり、「理想よりまだ厳しい」と自認している。
→当社でも実際に試してみましたが、「厳しめ」をたしかに体験できました。こちらは、もう少し定量的にとらえられてきたら別途レポートさせていただければと思います。 - そのため 無害な要求も時々引っかかる(=false positive、誤検知)。「一部のユーザーには不満だろう」と明言。
- ただし、発動するのは 平均してセッションの5%未満。逆に言えば95%超のセッションではフォールバックは起きず、その場合 Fable 5 は Mythos 5 と実質同等の性能 で動く。
- 誤検知は今後アップデートで減らしていく方針。
- フォールバックが起きたとき、Claude.ai 上では ユーザーに通知される(API利用時の扱いは後述)。
分類器がカバーするのは3領域です。
●サイバー(脆弱性発見・悪用に加え、偵察・横展開などの「エージェント的ハッキング」を広くブロック)、
●生物・化学(当面は広めにフォールバック。例として遺伝子治療用AAVの設計予測タスクでMythosクラスが専用モデルを上回った、というデュアルユース性が挙げられている)、
●蒸留(Claudeの能力を抽出して競合モデルを訓練しようとする試みを検知)。
なお、refusal(拒否)ではなく Opus 4.8 への肩代わり という形を採ったのは、「いきなり断られるより、それ自体が高性能なOpusが答えてくれるほうがマシな体験だろう」という設計思想によるものです。これは率直に、改善だと感じます。
当社の読み解き ── 誤検知記事との接点
ここからは当社の解釈です。
当社は先日「Claude Codeで正規の運用作業が『Usage Policy違反』になる理由 ── リアルタイム・サイバーセーフガードの誤検知と対処法」という記事を書きました。自社サーバへのSSHデプロイや自社リポジトリへのコミットといった、まったく攻撃的でない作業が、サイバー関連のセーフガードに引っかかってブロックされる、という現象です。
Fable 5 の「フォールバック」は、当社が Claude Code で遭遇してきたサイバーセーフガードの誤検知問題と 非常に近い運用上の課題を、公式仕様として可視化したもの と見ることができます。
「同じ仕組み」と断言はできませんが、実務上は同じ種類の注意点が伴う、という読み方です。
実務で頭に入れておくべき点を、当社なりに3つ挙げます。
- 無音で切り替わるわけではないが、挙動は部分的に変わりうる。
Claude.ai ではフォールバック時にユーザーへ通知され、API利用では前述のとおり拒否レスポンスを自前でハンドリングする形になります。いずれにせよ、長時間の自律タスクの途中で一部だけ Opus 4.8 が混ざると、出力の質やツール呼び出しの癖が部分的に変わる可能性があります。当社がOpus 4.7のガイド記事で書いたように、モデルが変われば命令の解釈も変わる。エージェントを長く走らせる設計では、ここは検証ポイントです。 - セキュリティ系・バイオ系の正当な業務ほど引っかかりやすい。
防御側の正当な用途と攻撃側の悪用が両用(デュアルユース)になりがちな分野では、正しいことをしているのにブロックされる場面が、当面ある程度避けられないと考えておくのが現実的です。Anthropic自身も「専門家には有益な同じ質問が、悪意ある者の手では危険になりうる」と述べています。生物分野については、近く審査制の「信頼済みアクセスプログラム」が開かれ、対象研究者は生物・化学のセーフガードを外した Fable 5 を使える予定、とされています。 - ジェイルブレイク耐性はかなり堅牢。
外部バグバウンティで1,000時間以上テストしても万能(universal)ジェイルブレイクは見つからず、攻撃計画・エクスプロイト開発・防御回避に関する単発の有害リクエストへの応答はゼロ件(30種類の公開ジェイルブレイク技法を使われても変わらず)、と報告されています。一方で、英国AISIが短い初期テストで部分的に進展した、という正直な注記もあります。
3. 本丸その2
30日データ保持ポリシー
地味ですが、企業導入では必ず確認すべき変更点です。
Fable 5・Mythos 5、そして今後の同等以上の能力を持つモデルでは、
ビジネス顧客のトラフィックについて30日間のデータ保持が必須 になります
(自社・サードパーティ両方の経路で)。
Anthropicは「学習には使わない」「安全目的以外には使わない」「人間がアクセスしたら全件ログを取る」「ほぼすべてのケースで30日後に削除する」
と説明しています。
理由は、新しいジェイルブレイクや複数リクエストにまたがる攻撃の検知・防御、そして誤検知の特定・低減のため、とされています。
セキュリティ向上のための施策である一方で、
機密情報を扱う企業にとっては「自社データが30日間どう扱われるか」を社内規程やお客様との契約と突き合わせて確認する必要があります。
当社がAIエージェントを"事業に載せる"連載で繰り返し述べてきた通り、AI導入は技術選定だけでなく、データ・権限・責任の設計がセットです。
新モデルの能力に飛びつく前に、法務・情シスと一度すり合わせておくことを強くおすすめします。
4. 本丸その3 ── 料金と「どの業務に使うか」の設計
料金は 入力 $10 / 出力 $50(1Mトークンあたり) です。Mythos Preview の半額以下まで下がりましたが、立ち位置を正確に押さえると Opus 4.8 の約2倍 です。
| モデル | 入力 | 5分キャッシュ書込 | 1時間キャッシュ書込 | キャッシュヒット | 出力 |
|---|---|---|---|---|---|
| Claude Fable 5 | $10 | $12.50 | $20 | $1 | $50 |
| Claude Mythos 5(限定提供) | $10 | $12.50 | $20 | $1 | $50 |
| Claude Opus 4.8 | $5 | $6.25 | $10 | $0.50 | $25 |
(単位はいずれも /1Mトークン)
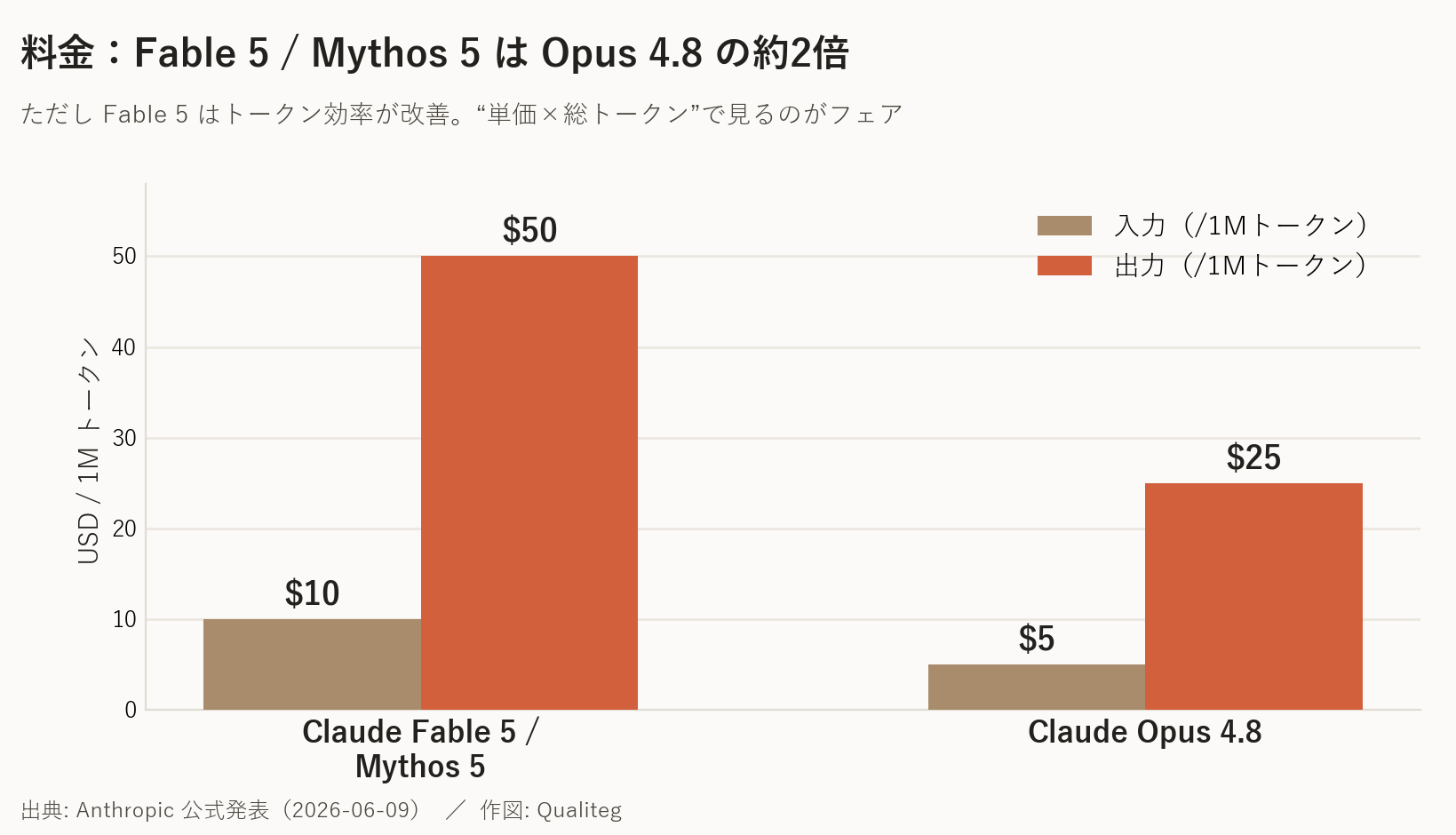
主要モデルの中では最高価格帯ですが、Fable 5 はトークン効率が改善している(同じ仕事をより少ないトークンで終える)とされるため、
「トークン単価」だけでなく「タスク完了までの総トークン」で見る
のがフェアな比較になります。
実務では、「全部 Fable 5 で回す」のではなく、長時間・高難度の本丸タスクにだけ Fable 5、それ以外は Opus / Sonnet / Haiku に振り分ける という設計がコスト面の王道になりそうです。当社の主要LLMプロバイダーのAPI料金表も、適宜更新していきます。
5. 性能 ── 当社が注目したのは"短距離走"より"長距離走"
ここまで運用面を先に整理しましたが、性能の話も押さえておきます。
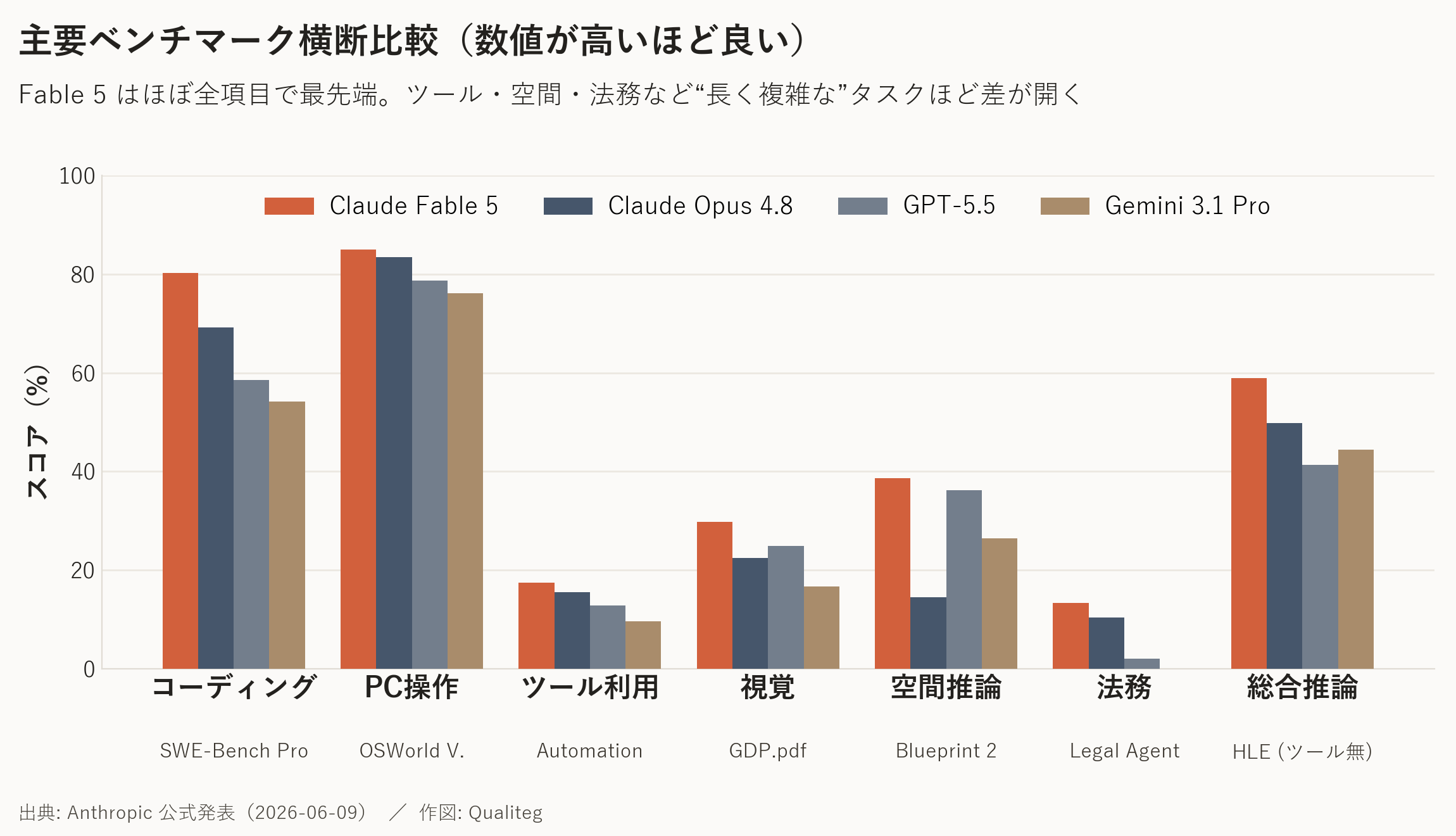
Anthropicは Fable 5 を「これまで一般公開したどのモデルより高性能」「ほぼ全ベンチマークで最先端」と表現しています。
面白いのは、タスクが長く複雑になるほど他モデルとの差が開く という特徴です。
ベンチマークの全体像は、冒頭の表(公式発表の数値を当社で日本語に整理したもの)のとおりです。ここでは要点を図で補足します。
| 分野・ベンチマーク | Mythos 5 / Fable 5 | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| コーディング|SWE-Bench Pro | 80.3% | 69.2% | 58.6% | 54.2% |
| コーディング|FrontierCode(Diamond) | 29.3% | 13.4% | 5.7% | — |
| 知識労働|GDPval-AA(ELOレート) | 1932 | 1890 | 1769 | 1314 |
| 視覚|GDP.pdf(ツール無) | 29.8% | 22.5% | 24.9% | 16.7% |
| 空間推論|Blueprint Bench 2 | 38.6% | 14.5% | 36.2% | 26.5% |
| ツール利用|AutomationBench | 17.4% | 15.5% | 12.9% | 9.6% |
| コンピュータ操作|OSWorld Verified | 85.0% | 83.4% | 78.7% | 76.2% |
| 法務|Legal Agent Benchmark | 13.3% | 10.4% | 2.1% | 0.0% |
| 総合推論|Humanity's Last Exam(ツール無) | 59.0%*Fable実効 ≈49.8% | 49.8% | 41.4% | 44.4% |
| 総合推論|Humanity's Last Exam(ツール有) | 64.5%*Fable実効 ≈57.9% | 57.9% | 52.2% | 51.4% |
| 生物|BioMysteryBench(hard) | 46.1%*Fable実効 ≈40.0% | 40.0% | — | — |
| エージェント開発|Terminal-Bench 2.1 | 88.0%*Fable実効 ≈82.7% | 82.7% | 83.4% | 70.7% |
| サイバー|ExploitBench | 78.0%*Fable実効 ≈40%/ブロック時ほぼ0% | 40.0% | 34.0% | — |
| 健康|HealthBench Professional | 66.0%*Fable実効 ≈56.9% | 56.9% | 51.8% | — |
“ほぼ”全項目で先頭ですが、長期運用系の Vending-Bench では Fable 5 が Opus 4.8 を僅差で下回る例(約 $5,680 対 $5,787)もあります。
象徴的なデモも並んでいます。
Stripe が5,000万行のRubyコードベースの全面マイグレーションを「人手のチームなら2ヶ月以上の作業を1日で」完了。
永続メモリを与えると『Slay the Spire』の成績改善幅が Opus 4.8 の3倍に。
複雑な補助ツールを必要とした『ポケモン ファイアレッド』を、生スクリーンショットだけの最小ハーネスでクリア(=ビジョン性能の向上)。
ゲームの話が並ぶとつい「お遊び」に見えますが、当社の現場感覚では、これは 「長時間、自分のメモを頼りに、自分の出力を検証しながら走り続けられる」 というエージェント能力の証明です。"書くAI"から"指揮するAI"へ、という流れの中で最大のボトルネックだった「長丁場でコンテキストを見失う」「途中で自分の間違いに気づけない」という弱さに、正面から効いてくる改善だと見ています(参考:コーディングエージェントの連載)。
知識労働でも、金融ベンチで最高スコア、トレーディング分析をほぼ全項目で制覇、といった早期顧客の声が並んでいます。資料を読んで考える系の仕事で効いてくるはずです。
6. いつから使える? ── サブスクの提供スケジュールに注意
- Claude API / 従量課金のEnterpriseプラン … 6/9から全面提供。開発者は
claude-fable-5で叩けます。 - サブスク(Pro / Max / Team / シート課金Enterprise) … 段階的ロールアウト。
- 6/9〜6/22:追加料金なしで利用可能。
- 6/23以降:いったんプランから外れ、利用にはクレジット(usage credits)が必要に。容量に余裕があれば無料期間を延長する可能性あり。
- その後:容量が十分確保でき次第、標準機能として復活させる予定。
需要が「非常に高く、読みにくい」と見込んでの慎重なロールアウト、とのこと。
「6/22までは追加料金なしで試せる期間、それ以降はいったんクレジット利用」
と覚えておくとよさそうです。
試すなら今のうちですね!
なお Claude.ai 上では「2x usage(通常の2倍消費)」扱いと報じられています。
まとめ
Claude Fable 5 は、単に「新しい高性能モデルが出た」というニュースではありません。
Mythosクラスの能力を一般利用に近づける一方で、サイバー・バイオ・化学・蒸留といった高リスク領域ではフォールバックを組み込み、企業利用では30日データ保持も前提になる。4月に「強すぎて出せない」と言われた神話(Mythos)が、安全装置をまとった寓話(Fable)として降りてきた、というわけです。
つまり重要なのは、性能だけを見ることではなく、どの業務に使い、どこで人間が確認し、どのデータを入れてよいかを設計すること です。Fable 5 は、AIエージェントの実務利用を一段進めるモデルであると同時に、企業側にもより丁寧な運用設計を求めるモデルだと言えます。
なお、当社のエンタープライズAIエージェント基盤 Bestllam なら、Claude Fable 5 をはじめ30以上のLLMを単一契約で利用でき、タスクに応じて最適なモデルを振り分けます。
本記事で触れた「本丸タスクは Fable 5、それ以外は Opus / Sonnet / Haiku」という振り分けを、契約も運用も一本化したまま実現できます。しかも本記事で挙げた懸念 ── 30日データ保持やセーフガードの誤検知 ── に対しても、LLM-Audit® の入出力監査とクロスボーダー保護(データを国外に出さない運用)で、企業の決裁を通せるガバナンスを標準装備しています。
Fable 5 をはじめとした最新AIを自社の業務にどう生かすか、
迷ったら、お気軽にお問い合わせくださいませ!
それでは、また次回お会いいたしましょう!
※本記事はAnthropicの公式発表(2026年6月9日)および各種報道に基づいて作成しています。価格・提供条件・セーフガードの仕様は今後変更される可能性があります。最新の情報はAnthropic公式をご確認ください。
※本記事中のグラフ・比較表・解説図は、すべて Anthropic 公式発表の数値を出典として当社(Qualiteg)が独自に作図・整理したものです(公式図版の転載ではありません)。ヘッダーおよび挿絵は当社の生成AIで作成したオリジナル画像です。数値は公式ベンチマーク表をもとに複数ソースで照合のうえ掲載していますが、最終的な正確性は公式ページでご確認ください。



